MS Applied Analytics @ Columbia University (GPA 3.92) | Data Engineer | Machine Learning Engineer
Currently: Data Analyst @ Yondr | Previously: Management Consulting @ Protiviti, Operations @ Amazon
🚀 Building data pipelines, ML models, and analytics platforms that solve real-world business problems
📍 New York, NY | 📧 tracey.ho@columbia.edu | 🔗 LinkedIn
I bridge data engineering and data science - building scalable pipelines that process millions of records, then extracting insights through ML and analytics. My sweet spot is turning messy data into actionable business intelligence.
Recent highlights:
- 🏗️ Yondr: Centralizing fragmented data systems with Python/SQL ETL workflows, building unified dashboards for COO and CFO
- 🔐 Protiviti: Built Python-based cryptocurrency risk detection system (pending patent), analyzed $30M-$1B securitizations
- 📦 Amazon: Led 100+ employees to 60K+ packages/day, saved $25M through robotics optimization
Full-stack ML solution for financial fraud detection combining Random Forest (94% AUC), Isolation Forest for anomaly detection, and market volatility analysis. Discovered 15% fraud increase during market turbulence.
Impact: Catch 38% of fraud at 5% hit rate → save ~$300K/month per 1M transactions
Tech Stack: R Random Forest Isolation Forest SMOTE PCA Statistical Analysis Fintech
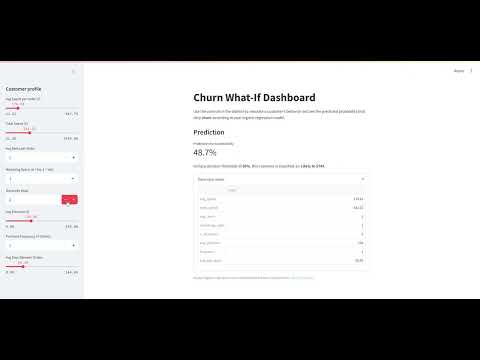
End-to-end customer analytics platform for JOOLA (premium pickleball brand) analyzing 1.9M transactions to predict churn and optimize retention. Built XGBoost model (AUC 0.85) identifying key churn drivers, discovered 66% one-time buyer problem, and found 110K monthly searches in untapped keyword opportunity.
Key insights: 3 premium SKUs drive 50%+ profit (concentration risk), high-spend customers show 2.1x retention vs discount users, court-related keywords have low competition at $0.86-$3.69 CPC
Tech Stack: Python XGBoost Logistic Regression Pandas Streamlit Tableau RFM Analysis Customer Segmentation
End-to-end database system analyzing 2,133 luxury cosmetics pop-up events across global markets. Built normalized 3NF PostgreSQL schema, Python ETL pipeline, and Metabase dashboards tracking revenue efficiency and brand performance for Chanel, Dior, YSL, and 21 other luxury brands.
Key insights: Asia leads with 74% sell-through rate, Special Launch events outperform by 5%, Tokyo generates highest revenue efficiency
Tech Stack: PostgreSQL Python Pandas SQLAlchemy Metabase ETL Database Design 3NF Normalization
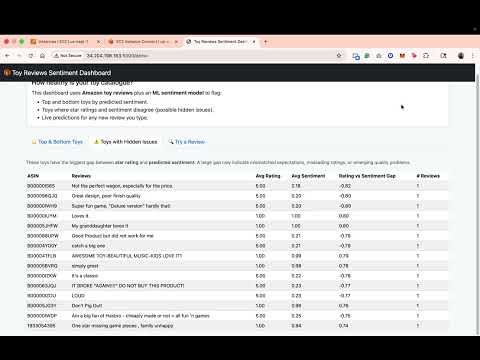
Cloud-native ML system analyzing 50,000 Amazon toy reviews to identify products with hidden quality issues. Built sentiment classifier (91% accuracy) using TF-IDF + Logistic Regression, deployed on AWS (S3, Lambda, EC2, RDS). Flask dashboard reveals products where high star ratings mask negative sentiment.
Key insight: Products with large rating-sentiment gaps signal quality concerns invisible to traditional metrics
Tech Stack: AWS S3 Lambda EC2 RDS Python Flask Scikit-learn TF-IDF PostgreSQL NLP
Production-scale data engineering pipeline processing 22M NYC taxi trips (2.13GB) with Spark + PostgreSQL. Built Streamlit dashboard delivering real-time revenue recommendations for drivers competing with Uber.
Key findings: Optimal 5-10 mile trips, 2 AM peak tipping (30% rate), JFK generates $58M revenue (24% of total)
Tech Stack: Python Apache Spark PostgreSQL Streamlit Geospatial Analysis ETL Docker
Machine learning model predicting Click-Through Rates using XGBoost with hyperparameter tuning. Achieved Test RMSE of 0.059, demonstrating feature engineering and model optimization.
Business value: Optimize digital ad spend by targeting high-conversion audience segments
Tech Stack: R XGBoost Hyperparameter Tuning Marketing Analytics Predictive Modeling
Real estate analytics examining crime, education, and walkability factors affecting rent prices across NYC boroughs. Provides data-driven insights for renters and investors.
Tech Stack: Python Pandas Data Visualization Exploratory Data Analysis
Statistical research quantifying the impact of 15-minute workplace naps on productivity and energy levels. Demonstrates experimental design, power analysis, and hypothesis testing.
Tech Stack: R Statistical Analysis Hypothesis Testing Power Analysis Research Design
Apache Spark PostgreSQL MongoDB ETL Pipelines PySpark SQL APIs Docker Cloud Integration
Python R Scikit-learn XGBoost Random Forest Predictive Modeling Feature Engineering Statistical Analysis
Streamlit Tableau Metabase PowerBI Plotly ggplot2 Matplotlib Interactive Dashboards Bootstrap UI
AWS Azure Git VS Code Agile Development Flask Jupyter RStudio Lambda EC2 DynamoDB
Financial Risk Modeling Fraud Detection Transportation Analytics Marketing Analytics Operations Optimization
- Built ETL pipelines processing 22M+ records with Spark, PostgreSQL, MongoDB
- Centralized fragmented data systems at Yondr with Python/SQL workflows
- Designed scalable data models connecting sales, supply chain, and finance
- Developed fraud detection models (Random Forest 94% AUC, Isolation Forest)
- Built cryptocurrency risk detection system (pending patent at Protiviti)
- Created predictive models (XGBoost, Logistic Regression) for customer conversion
- Built interactive dashboards (Streamlit, Tableau) for C-suite executives
- Conducted lender due diligence on $30M-$1B securitizations (CLO, auto, student loans)
- Analyzed 1.9M records for customer conversion & retention at Joola
- Managed 100+ employees at Amazon fulfillment center
- Delivered 60K+ packages/day (record-breaking) while reducing costs by $237K
- Optimized robotics workflows saving $25M and increasing productivity 30%
Columbia University | Master of Science, Applied Analytics | GPA: 4.0 / 4.0 | 2024-2025
- Coursework: AI, Cloud Computing, Machine Learning, Blockchain
UT Austin | Bachelor of Business Administration, Finance | GPA: 3.62 / 4.0 | 2020-2024
- Full-Ride Scholarship ($300K+) | SAT: 1520/1600
1. Full-Stack Data Skills
- Not just analytics or engineering - I do both
- Build the pipeline (Spark ETL) → Train the model (ML) → Ship the product (Dashboard)
2. Business Impact Focus
- Every project has measurable outcomes: $300K/month fraud savings, $25M cost reduction, 30% productivity gain
- I translate data science into executive-friendly insights
3. Production Experience
- Internships at Yondr, Protiviti, Amazon - not just academic projects
- Built systems handling real money ($1B securitizations), real scale (22M trips), real users (100+ employees)
4. Rapid Learner
- 4.0 GPA at Columbia in technical MS program
- Full-ride scholarship at UT Austin (top 1% of applicants)
- Self-taught: Blockchain analytics, patent-pending crypto risk detection
📧 Email: tracey.ho@columbia.edu
📍 Location: New York, NY
🕺 Breakdancer | 🌍 Traveling to the Seven Wonders | 🏔️ Outdoor enthusiast | 🤝 Volunteering
🗣️ Languages: Native Vietnamese | Basic Spanish, Mandarin, Korean, German
💡 "I don't just analyze data - I build systems that turn data into competitive advantage."