Conversation
567c076 to
e2f19dc
Compare
2896fcb to
f6b8f5b
Compare
 jacobkaufmann
left a comment
jacobkaufmann
left a comment
There was a problem hiding this comment.
Neither approving or requesting changes because I want to get your thoughts on the comments.
I'm also not sure how I feel about changing the query callback response type for FindContent. An alternative would be to create a struct for that type and include a field for the trace, which could be wrapped in an Option. I don't have a problem with doing the trace for all queries, because it could be useful for metrics, but I'm not sure it should be included in the response for non-trace find content queries.
I also find the structure of the response confusing, particularly the omission of previously returned ENRs from the arrays. If each response is timestamped, then you could infer the path if you assume that you only query a node the first time you see it. Alternatively, you could include a field in the response dedicated to representing the path.
8b6155d to
649eedb
Compare
 perama-v
left a comment
perama-v
left a comment
There was a problem hiding this comment.
Very nice. Looks good to me. Tested by making a query (portal_historyTraceRecursiveFindContent) and inspecting the results.
I notice that the resulting "responses" includes the nodes own ID and includes "responded_with": ["node_x", "node_y", ...] for itself. This seems ok/useful, just wanted to note it.
 ogenev
left a comment
ogenev
left a comment
There was a problem hiding this comment.
Blocking this until we agree on what to do with the Value type in TraceContentInfo.
Agreed 👍
I originally had it that way but didn't see any useful, non-chaotic way of visualizing that info on the front-end so it was unnecessary data & front-end parsing complexity. I'm open to a second iteration down the line that adds all response data. |
|
Note that Also note that Node IDs are now being used as the primary ID for each node rather than ENRs. This was due to a bug caused by multiple ENRs for the same node ID making it into the |
jacobkaufmann
left a comment
There was a problem hiding this comment.
It looks like there are some unaddressed comments from other reviewers, and I have some comments of my own.
At a high level, the following aspects of the trace structure do not make much sense to me:
- that the origin node has an entry in the
responsesfield - that only the first node to respond with some node
Xwill be the only entry withXin that list
I believe we can find a better representation for the trace that doesn't warp the information in these ways. I would be more in favor of a straightforward representation that requires the caller to do whatever necessary disentanglement of the data on their end.
Why would
My previous response from above:
Why add unused complexity to both the back-end and front-end? We can iterate this format as our needs progress. |
|
apologies for missing some of the original comments on rationale. the origin would not have entry in my claim is that right now we are introducing complexity on the back-end where things could be much simpler, and it would be better for any complexity to reside on the front-end. the simplest thing to do on the back-end is to provide all the response data as we received it. as long as the front-end can tease out the structure from that data, then it is preferable to keep our logic simple at the expense of the consumer. |
I've created I kept the |
The format is generalized: each node (including the origin node) responds to the query by either returning the requested content or by looking in its own routing table for closest ENRs to continue the query. I see no need to make the origin node's behavior an edge case and add complexity to the format instead of just describing its behavior the exact same way that the behavior of every other node is described. Seems cleaner than any non-generalized format to me. This is the same reason why I felt it was best to change the output of a trace where the content is found locally from I suppose the semantics of the word
Could you elaborate on where complexity is being introduced to trin? Are you referencing nodes only being included in the trace the first time they're seen? The single I agree with adding all responses in the near future. It will allow us to answer/visualize interesting questions like the degree of routing table overlap across the network. Not sure if you're saying we should block this and come up with a new format before deploying the existing functionality. |
Yeah, naming this as a DAGSearchPath instead of a query trace might help? This data structure is the nodes and directed edges that were followed in the path. That explains why we drop the duplicate responses, and why the origin node lists outbound edges just like all the intermediate nodes do. The reason to favor something like Jacob is talking about would be if we want to use the query trace for something besides visualizing a search path. In which case, it makes sense to keep the data structure as clearly describing the series of events that occurred (nodes responded, etc), rather than overfitting to this particular usage. I don't have a clear idea what else we would use this for right now. So maybe just "admitting" that we're building this data for a single purpose, by naming it as such, is the way to go. Until we have a specific idea of what else we would use a query trace for. |
Sure.
I would agree if we were locking ourselves into anything. Adding all of the responses is a ~1 line code change in trin, and is backward compatible on the front-end. |
|
here is a concrete example of the sort of thing I had in mind: struct QueryPeer {
requested_at: Instant,
responded_at: Instant,
response: QueryResponse,
}
enum QueryResponse {
Peers(HashMap<Enr, QueryPeer>),
Content,
}
struct QueryTrace {
// originator of query (i.e. local node)
origin: Enr,
// target content ID.
target: ContentId,
// UTC timestamp for query start.
started_at: Instant,
// UTC timestamp for query end (termination).
ended_at: Instant,
// first level of peers in the map are the bootstrap peers, or those initially queried.
trace: HashMap<Enr, QueryPeer>,
}the structure could be modified to include peers who do not respond or use nested arrays instead of maps, but I just want to get the general idea across. having said that, I'm okay moving forward with the existing structure. like @carver said, we can move forward with this special-purpose design until something more general is required. there are still some outstanding comments that I would like to see addressed though. |
80d6b81 to
c53b856
Compare
ogenev
left a comment
There was a problem hiding this comment.
IMO, we don't need two QueryTrace types - one in ethportal-api and one in query_trace.rs.
We can leave only the QueryTrace type in query_trace.rs and use some serde primitives not to serialize the started_at and target_id fields. We can also use the NodeId type from ethportal-api which will make implementing Serialize/Deserialize for this QueryTrace type trivial. Then we should re-export this type via ethportal-api for external users to access it.
In summary, this would look something like this:
- Remove the
QueryTracetype fromethportal-api. - Move
QueryTracefromtrin-coretotrin-types. - Use
ethportal-api::discv5::NodeIdtype instead ofdiscv5::enr::NodeIdinQueryTrace. - Implement Serialize/Deserialize for
QueryTraceand add#[serde(skip_serializing)]attributes forstarted_atandtarget_idfields. - Import
QueryTraceinethportal-apifromtrin-typesand re-export it.
812b062 to
b4b9992
Compare
|
Tested, looks good. Three minor notes:
|
The first is the content itself, whereas the second is optional ID of the node that returned the content.
Good point, this was previously skipped, but with the way that |
 carver
left a comment
carver
left a comment
There was a problem hiding this comment.
Just did a quick scan. Seems like we're well into the territory of this being an improvement from where we were, with no major setbacks. I think Ognyan's ❌ is outdated and can be disregarded now. I say we address any last things, and I saw you put issues in for follow-up work, so it's good to go. I'm excited to see the results in glados!
| // Re-exports jsonrpsee crate | ||
| pub use jsonrpsee; | ||
|
|
||
| pub use trin_types::discv5::*; |
There was a problem hiding this comment.
I'm personally not a fan of the flattening of this trin_types module structure, but that seems to already be the standard in this module, so it seems like the right choice, incrementally. Maybe it's a standard we can talk about in person at the upcoming summit.
| let uniq_content_key = | ||
| "\"0x0015b11b918355b1ef9c5db810302ebad0bf2544255b530cdce90674d5887bb286\""; | ||
| let history_content_key: HistoryContentKey = serde_json::from_str(uniq_content_key).unwrap(); |
There was a problem hiding this comment.
This feels like it has extra steps that I don't understand. Why go into a json-encoded string and back out?
I see some other places that do this same concept like this, like:
let content_key: HistoryContentKey =
serde_json::from_value(json!(HISTORY_CONTENT_KEY)).unwrap();which is a little better. But still, it seems like going in and out of json doesn't really do anything for us.
Something equivalent to this seems like the direct path that doesn't involve unnecessary json:
let key_bytes = "0015b11b918355b1ef9c5db810302ebad0bf2544255b530cdce90674d5887bb286";
let history_content_key = HistoryContentKey::from_bytes(hex::decode(key_bytes));| callback: Option<oneshot::Sender<FindContentResult>>, | ||
| is_trace: bool, | ||
| ) -> Option<QueryId> { | ||
| info!("Starting query for content key: {}", target); |
There was a problem hiding this comment.
We might want to reduce this to debug or drop it altogether, if we notice it being too little noisy, but I'm pretty happy to let that evolve over time, and be just a little generous with logs, especially with new features.
| let mut trace = QueryTrace::new( | ||
| &self.network.overlay.local_enr(), | ||
| NodeId::new(&content_key.content_id()).into(), | ||
| ); | ||
| trace.node_responded_with_content(&local_enr); | ||
| (Some(val), if is_trace { Some(trace) } else { None }) |
There was a problem hiding this comment.
Seems like a bummer to do all the trace work every time, even when it wasn't requested. Maybe something like:
| let mut trace = QueryTrace::new( | |
| &self.network.overlay.local_enr(), | |
| NodeId::new(&content_key.content_id()).into(), | |
| ); | |
| trace.node_responded_with_content(&local_enr); | |
| (Some(val), if is_trace { Some(trace) } else { None }) | |
| let trace_option = if is_trace { | |
| let mut trace = QueryTrace::new( | |
| &self.network.overlay.local_enr(), | |
| NodeId::new(&content_key.content_id()).into(), | |
| ); | |
| trace.node_responded_with_content(&local_enr); | |
| Some(trace) | |
| } else { None } | |
| (Some(val), trace_option) |
Adds response timestamps to tracing output Adds comments Adds timestamp for content found event Adds ENRs and distinction between no response and no progress Passes ENRs by reference Adds unit test Update peertest to parse trace output Add release notes Small cleanup of query_tracer.rs Add node metadata to trace De-duplicate ENRs and rename to QueryTrace Refactors node_responded_with to take a vec of all ENRs Adds test of node_metadata values Update ms->millis Update jsonrpc types & test Do not create or manage a QueryTrace for queries which don't require one Define and test ethportal-api QueryTrace type Use NodeId within trin_core::QueryTrace instead of String
What was wrong?
portal_historyTraceRecursiveFindContentendpoint's output contains a list of nodes involved in a content query, but currently lacks a comprehensive trace of the query's search path.How was it fixed?
Each content query trace is kept track of by a
QueryTracerstruct, that ultimately serializes to the following JSON format:where each letter is an ENR.
Each entry in
responsesis a map of a remote node's ENR to the list of ENRs that it responded with because it didn't have the content.originis the local node, and theresponsesentry for the origin node shows the nodes that were closest to the content in its own routing table. The entry for thefound_atnode should have an emptyresponded_withfield, as it is only used to mark the timestamp at which the content was received.Each node's
timestamp_msfield contains the number of milliseconds that elapsed between the query beginning and the response from the node being received.Note that only the first node that responded with a given node
Awill haveAin theirresponded_withlist, so only the actual route taken is present in the data rather than other hypothetical routes. This means that many nodes will have emptyresponded_witharrays. These nodes did respond, but not with anything that hasn't already been seen in the query. This is the case forCin the example above.A full visualization of a query using this data format is done here: https://github.com/pipermerriam/glados/pull/28
Here's a screenshot:
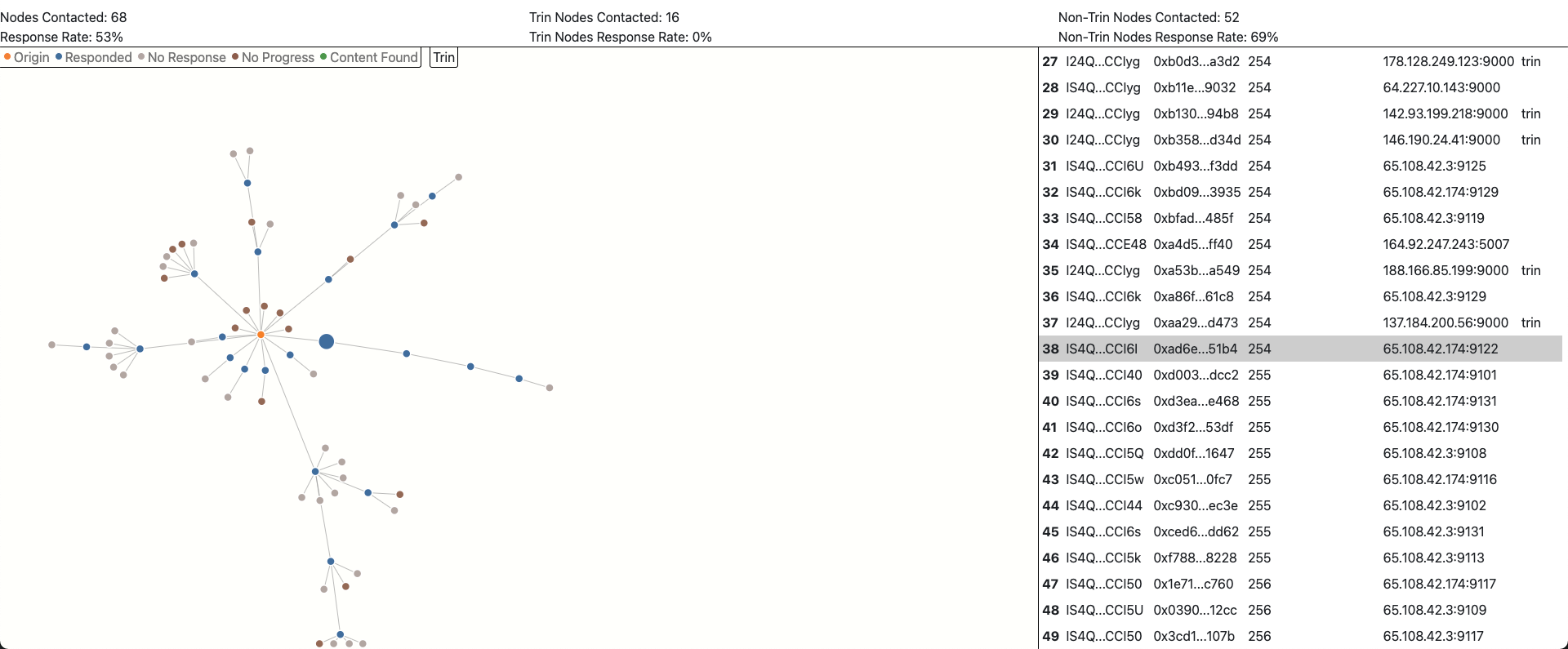
and here's the route highlighted on a successful query:
To-Do