Funboost 是一个 Python 万能分布式函数调度框架。以下是您的核心学习资源导航:
| 资源类型 | 链接地址 | 说明 |
|---|---|---|
| ⚡ 快速预览 | 👉 点击查看演示 | 直观感受框架运行效果 |
| 📖 完全教程 | 👉 ReadTheDocs | 包含原理、API 与进阶用法 |
| 🤖 AI 助教 | 👉 AI 学习指南 | [必读] 利用 AI 掌握框架的最佳捷径 |
funboost是一个 万能 强大 简单 自由 的 python 全功能分布式调度框架,它的作用是给用户任意项目的任意函数赋能
Funboost 的核心价值主张:把复杂留给框架,把简单留给用户。
<iframe src="https://ydf0509.github.io/funboost_git_pages/index2.html" width="100%" height="2400" style="border:none;"></iframe> 您的浏览器不支持音频播放。快速了解和上手funboost,直接看1.3例子
pip install funboost --upgrade
或 pip install funboost[all] #一次性安装所有小众三方中间件 -
万能分布式调度:
funboost通过一行 @boost 装饰器,将普通函数瞬间升级为具备 分布式执行、FaaS 微服务化、CDC 事件驱动 能力的超级计算单元,连接一切,调度万物。 -
全能支持:自动支持 40+种 消息队列 + 30+种 任务控制功能 +
python中所有的并发执行方式。 -
FaaS 能力:通过
funboost.faas的功能,可以一键快速实现 FaaS (Function as a Service),让函数秒变自动发现的微服务。 -
重功能,轻使用:
funboost的功能是全面性重量级,用户能想得到的功能 99% 全都有;但使用方式却是极致轻量级,只有@boost一行代码需要写。 -
颠覆性设计:
funboost的神奇之处在于它同时拥有“轻量级使用方式”和“重量级功能集”,完全颠覆了“功能强大=使用复杂”的传统思维。它是对传统 Python 框架设计的一次巧妙超越。只需要一行
@boost代码即可分布式执行python一切任意函数,99% 用过funboost的pythoner核心感受是:方便、高速、强大、自由。
funboost 是 Python 函数的万能加速器。它包罗万象,一统编程思维,将经典的 生产者 + 消息中间件 + 消费者 模式封装到了极致。
无论新老项目,Funboost 都能无缝融入,为您提供以下核心能力:
-
🌐 需要分布式? 没问题!Funboost 支持 40+种 消息队列中间件。只要是叫得上名字的 MQ(甚至包括数据库、文件系统),它都能支持。
-
⚡ 需要 FaaS (Function as a Service)? 这是亮点! 借助
funboost.faas,您可以一键将普通函数转化为 HTTP 微服务接口。函数自动发现,发布消息、获取结果、管理任务,瞬间完成 Serverless 般的体验。 -
🚀 需要并发? 满足你!Python 所有的并发模式(线程、协程、多进程)任你选择,甚至支持它们叠加使用,榨干 CPU 性能。
-
🛡️ 需要可靠性? 稳如泰山!消费确认 (ACK)、自动重试、死信队列 (DLQ)、断点续爬... 即使服务器宕机,任务也绝不丢失。
-
🎛️ 需要控制力? 如臂使指!精准 QPS 控频、分布式限流、定时任务、延时任务、超时熔断、任务过滤... 给您三十多种控制武器。
-
📊 需要监控? 一目了然!开箱即用的 Funboost Web Manager,让您对任务状态、队列积压、消费者实例等信息了如指掌。
-
🦅 需要自由? 零侵入!它不绑架您的代码,不强管您的项目结构。随时能用,随时能走,还您最纯粹的 Python 编程体验。
答:很难用一句话定义它。Funboost 是一个万能框架,几乎覆盖了 Python 所有的编程业务场景。它的答案是发散的,拥有无限可能。
答:绝对值得。选择一个用途狭窄、性能平庸、写法受限的框架,确实是在浪费生命。Funboost 则完全不同。
核心比喻:
funboost与celery的关系,如同 iPhone 与 诺基亚塞班。 它们的核心功能虽都是通讯(任务调度),但不能因为功能重叠就判定为重复造轮子。正如 iPhone 重新定义了手机,Funboost 正在重新定义分布式任务调度,让“框架奴役”成为历史。
1. 共同点 两者本质上都是基于分布式消息队列的异步任务调度框架,遵循经典的编程思想:
生产者 (Producer)->中间件 (Broker)->消费者 (Consumer)
2. 核心区别
| 维度 | Celery (重型框架) | Funboost (函数增强器) |
|---|---|---|
| 设计理念 | 框架奴役:代码需围绕 Celery 的架构和 App 实例组织。 | 自由赋能:非侵入式设计,为任意函数插上分布式的翅膀。 |
| 一等公民 | Celery App 实例 (Task 是二等公民) |
用户函数 (无需关注 App 实例) |
| 核心语法 | 需定义 App,使用 @app.task |
直接使用 @boost 装饰器 |
| 易用性 | 需规划特定的项目结构,上手门槛较高。 | 极简,任意位置的新旧函数加上装饰器即可用。 |
| 性能表现 | 传统性能基准。 | 断层式领先:发布性能是 Celery 的 22倍,消费性能是 46倍。 |
| 功能广度 | 支持主流中间件。 | 支持 40+ 种中间件,拥有更多精细的任务控制功能。 |
funboost 全面覆盖 Python 生态下的并发执行方式,并支持灵活的组合叠加:
- 基础并发模式:支持
threading(多线程)、asyncio(异步IO)、gevent(协程)、eventlet(协程) 以及单线程模式。 - 叠加增强模式:支持 多进程 (Multi-Processing) 与上述任一细粒度并发模式(如多线程或协程)进行叠加,最大限度利用多核 CPU 资源。
得益于强大的架构设计,在 funboost 中 “万物皆可为 Broker”。不仅涵盖了传统 MQ,更拓展了数据库、网络协议及第三方框架。
- 传统消息队列:RabbitMQ, Kafka, NSQ, RocketMQ, MQTT, NATS, Pulsar 等。
- 数据库作为 Broker:
- NoSQL: Redis (支持 List, Pub/Sub, Stream 等多种模式), MongoDB.
- SQL: MySQL, PostgreSQL, Oracle, SQL Server, SQLite (通过 SQLAlchemy/Peewee 支持).
- 网络协议直连:TCP, UDP, HTTP, gRPC (无需部署 MQ 服务即可实现队列通信)。
- 文件系统:本地文件/文件夹, SQLite (适合单机或简单场景).
- 事件驱动 (CDC):支持 MySQL CDC (基于 Binlog 变更捕获),使 Funboost 具备了事件驱动能力,设计理念远超传统任务队列。
- 第三方框架集成:可直接将 Celery, Dramatiq, Huey, RQ, Nameko 等框架作为底层 Broker,利用 Funboost 的统一接口调度它们的核心。
答案是:极易上手。Funboost 是“反框架”的框架。
-
🎯 核心极简 整个框架只需要掌握
@boost这一个装饰器及其入参(BoosterParams)。所有的用法几乎都遵循 1.3 章节 示例的模式,一通百通。 -
🛡️ 零代码侵入
- 拒绝“框架奴役”:不像
Celery、Django或Scrapy那样强迫你按照特定的目录结构组织代码(一旦不用了,代码往往需要大改)。 - 即插即用:Funboost 对你的项目文件结构 0 要求,你可以随时将其引入任何新老项目中。
- 拒绝“框架奴役”:不像
-
🔄 进退自如(双模运行) 即使引入了 Funboost,也不需要担心代码被绑定。加上
@boost装饰器后,你的函数依然保持纯洁:- 调用
fun(x, y):直接运行函数(同步执行,不经过队列,和没加装饰器一样)。 - 调用
fun.push(x, y):发送到消息队列(分布式异步执行)。
- 调用
👉 关于“Funboost 学习和使用难吗?”的详细深度回答,请参阅文档 6.0.c 章节。
Funboost 内置了强大的 Funboost Web Manager 管理系统。
- 全方位掌控:支持对任务消费情况进行全面的查看、监控和管理。
- 开箱即用:无需额外部署复杂的监控组件,即可掌握队列积压、消费者状态等核心指标。
Funboost 的性能与 Celery 相比,有着数量级的优势(基于控制变量法测试):
- 发布性能:是 Celery 的 22倍。
- 消费性能:是 Celery 的 46倍。
注:详细的控制变量法对比测试报告,请参阅文档 2.6 章节。
95% 的用户在初步使用后都表示“相见恨晚”。核心评价如下:
- 极致自由:Funboost 对用户代码的编程思维零侵入。
- 拒绝改造:不像其他框架要求用户围绕框架逻辑重构代码,Funboost 尊重用户的原生代码结构。
- 核心体验:简单、强大、丰富。
- 旧框架名称:
function_scheduling_distributed_framework - 兼容说明:两者的关系和兼容性详情请见 1.0.3 章节。
- 旧版地址:GitHub - distributed_framework
🚀 快速上手指南
- 文档说明:文档篇幅较长,主要包含原理讲解与框架对比(
How&Why)。- 学习捷径:您只需要重点学习 [1.3 章节] 的这 1 个例子即可! 其他例子仅是修改
@boost装饰器中BoosterParams的入参配置。- 核心要点:
funboost极其易用,仅需掌握一行@boost代码。- 🤖 AI 辅助:强烈推荐阅读 [第 14 章],学习如何利用 AI 大模型快速掌握
funboost的用法。
🔗 在线文档地址:ReadTheDocs - Funboost Latest
- GitHub 项目主页:ydf0509/funboost
- nb_log 日志文档:NB-Log Documentation
有了 funboost,开发者将获得“上帝视角”的调度能力:
- 🚫 告别繁琐:无需亲自手写进程、线程、协程的底层并发代码。
- 🔌 万能连接:无需亲自编写操作
Redis、RabbitMQ、Kafka、Socket等中间件的连接代码。 - 🧰 全能控制:直接拥有 30+ 种企业级任务控制功能。
funboost示图:

也就是这种非常普通的流程图,一样的意思

以下两种方式均实现 10并发 运行函数 f。Funboost 更加简洁且具备扩展性。
import time
from concurrent.futures import ThreadPoolExecutor
def f(x):
time.sleep(3)
print(x)
pool = ThreadPoolExecutor(10)
if __name__ == '__main__':
for i in range(100):
pool.submit(f, i)import time
from funboost import BoosterParams, BrokerEnum
# 仅需一行装饰器,即可获得 10 线程并发 + 消息队列能力
@BoosterParams(queue_name="test_insteda_thread_queue",
broker_kind=BrokerEnum.MEMORY_QUEUE,
concurrent_num=10,
is_auto_start_consuming_message=True)
def f(x):
time.sleep(3)
print(x)
if __name__ == '__main__':
for i in range(100):
f.push(i)Funboost 不仅仅是任务队列,它是一个全功能的任务调度平台。
- 多中间件支持:支持 40+ 种中间件(Redis, RabbitMQ, Kafka, RocketMQ, SQL, 文件等)。
- 任务持久化:依托中间件特性,天然支持任务持久化存储。
- 全模式并发:支持
Threading、Gevent、Eventlet、Asyncio、Single_thread。 - 多进程叠加:支持在以上 5 种模式基础上叠加 多进程,榨干多核 CPU 性能。
- 精准控频 (QPS):精确控制每秒运行次数(如 0.02次/秒 或 50次/秒),无视函数耗时波动。
- 分布式控频:在多机、多容器环境下,严格控制全局总 QPS。
- 暂停/恢复:支持从外部动态暂停或继续消费。
- 断点接续:无惧断电或强制杀进程,依赖 ACK 消费确认机制,确保任务不丢失。
- 自动重试:函数报错自动重试指定次数。
- 死信队列:重试失败或主动抛出异常的消息自动进入 DLQ (Dead Letter Queue)。
- 重新入队:支持主动将消息重新放回队列头部。
- 定时任务:基于
APScheduler,支持间隔、CRON 等多种定时触发。 - 延时任务:支持任务发布后延迟 N 秒执行。
- 时间窗口:支持指定某些时间段(如白天)不运行任务。
- 超时熔断:函数运行超时自动 Kill。
- 过期丢弃:支持设置消息有效期,过期未消费自动丢弃。
- 可视化 Web:自带 Web 管理界面,查看队列状态、消费速度。
- 五彩日志:集成
nb_log,提供多进程安全的切割日志与控制台高亮显示。 - 全链路追踪:支持记录任务入参、结果、耗时、异常信息并持久化到 MongoDB/MySQL。
- RPC 模式:发布端可同步等待消费端的返回结果。
- 远程部署:一行代码将函数自动部署到远程 Linux 服务器。
- 命令行 CLI:支持通过命令行管理任务。
🏆 稳定性承诺
能够直面百万级 C 端用户业务(App/小程序),连续 3 个季度稳定运行无事故。 0 假死、0 崩溃、0 内存泄漏。 Windows 与 Linux 行为 100% 一致(解决了 Celery 在 Windows 下的诸多痛点)。
⚠️ 环境准备 (重要)在运行代码前,请确保您了解
PYTHONPATH的概念。 Windows cmd 或 Linux 运行时,建议将PYTHONPATH设置为项目根目录,以便框架自动生成或读取配置。 👉 点击学习 PYTHONPATH
这个例子演示了如何将一个普通的求和函数变成分布式任务。
代码逻辑说明:
- 定义任务:使用
@boost装饰器,指定队列名task_queue_name1和 QPS5。 - 发布任务:调用
task_fun.push(x, y)发送消息。 - 消费任务:调用
task_fun.consume()启动后台线程自动处理。
import time
from funboost import boost, BrokerEnum, BoosterParams
# 核心配置:使用本地 SQLite 作为消息队列,QPS 限制为 5
@boost(BoosterParams(
queue_name="task_queue_name1",
qps=5,
broker_kind=BrokerEnum.SQLITE_QUEUE
))
def task_fun(x, y):
print(f'{x} + {y} = {x + y}')
time.sleep(3) # 模拟耗时,框架会自动并发绕过阻塞
if __name__ == "__main__":
# 1. 生产者:发布 100 个任务
for i in range(100):
task_fun.push(i, y=i * 2)
# 2. 消费者:启动循环调度
task_fun.consume()💡 Tips 如果在 Linux/Mac 上使用
SQLITE_QUEUE报错read-only,请在funboost_config.py中修改SQLLITE_QUEUES_PATH为有权限的目录(详见文档 10.3)。
运行效果截图:
发布任务截图:

消费任务截图:

这是一个集大成的例子,展示了 Funboost 的核心能力:
- ✅ 参数复用:继承
BoosterParams减少重复代码。 - ✅ RPC 模式:发布端同步获取消费结果。
- ✅ 丝滑启动:非阻塞连续启动多个消费者。
- ✅ 定时任务:基于
APScheduler的强大定时能力。
import time
from funboost import boost, BrokerEnum, BoosterParams, ctrl_c_recv, ConcurrentModeEnum, ApsJobAdder
# 1. 定义公共配置基类,减少重复代码
class MyBoosterParams(BoosterParams):
broker_kind: str = BrokerEnum.REDIS_ACK_ABLE
max_retry_times: int = 3
concurrent_mode: str = ConcurrentModeEnum.THREADING
# 2. 消费函数 step1:演示 RPC 模式
@boost(MyBoosterParams(
queue_name='s1_queue',
qps=1,
is_using_rpc_mode=True # 开启 RPC,支持获取结果
))
def step1(a: int, b: int):
print(f'step1: a={a}, b={b}')
time.sleep(0.7)
# 函数内部可以继续发布任务给 step2
for j in range(10):
step2.push(c=a+b+j, d=a*b+j, e=a-b+j)
return a + b
# 3. 消费函数 step2:演示参数覆盖
@boost(MyBoosterParams(
queue_name='s2_queue',
qps=3,
max_retry_times=5 # 覆盖基类默认值
))
def step2(c: int, d: int, e: int=666):
time.sleep(3)
print(f'step2: c={c}, d={d}, e={e}')
return c * d * e
if __name__ == '__main__':
# --- 启动消费 ---
step1.consume() # 非阻塞启动
step2.consume()
step2.multi_process_consume(3) # 叠加 3 个进程并发
# --- RPC 调用演示 ---
async_result = step1.push(100, b=200)
print('RPC 结果:', async_result.result) # 阻塞等待结果
# --- 批量发布演示 ---
for i in range(100):
step1.push(i, i*2)
# publish 方法支持更多高级参数(如 task_id)
step1.publish({'a':i, 'b':i*2}, task_id=f'task_{i}')
# --- 定时任务演示 (APScheduler) ---
# 方式1:指定日期执行
ApsJobAdder(step2, job_store_kind='redis', is_auto_start=True).add_push_job(
trigger='date', run_date='2025-06-30 16:25:40', args=(7, 8, 9), id='job1'
)
# 方式2:间隔执行
ApsJobAdder(step2, job_store_kind='redis').add_push_job(
trigger='interval', seconds=30, args=(4, 6, 10), id='job2'
)
# 阻塞主线程,保持程序运行
ctrl_c_recv()🧠 设计哲学 Funboost 提倡 “反框架” 思维:你才是主角,框架只是插件。
task_fun(1, 2)是直接运行函数,task_fun.push(1, 2)才是发布到队列。 随时可以拿掉@boost,代码依然是纯粹的 Python 函数。
如果你追求极致简洁,也可以直接使用 @BoosterParams 作为装饰器,效果等同于 @boost(BoosterParams(...))。
# 极简写法
@BoosterParams(queue_name="task_queue_simple",qps=5)
def task_fun(a, b):
return a + b这种直接在 @boost传参,而不使用 BoosterParams来传各种配置,是过气写法不推荐,因为不能代码补全了。
# ⚠️ 反例:过时写法,不推荐!
@boost(queue_name="task_queue_simple",qps=5)
def task_fun(a, b):
return a + b可视化管理后台提供了强大的监控与运维能力,以下是核心功能截图:
| 模块 | 功能 | 视图 |
|---|---|---|
| 实时状态 | 查看函数运行状态与结果 |  |
| 速率趋势 | 展示历史与实时消费QPS |  |
| 模块 | 功能 | 视图 |
|---|---|---|
| IP查看消费者 | 根据IP查看消费者进程 |  |
| 查看消费者详情 | 查看一个booster所有消费者运行详情 |  |
| 模块 | 功能 | 视图 |
|---|---|---|
| 运维管理 | 清空、暂停、调整QPS与并发 |  |
| 多维指标 | 查看运行次数、失败率、耗时、积压量 |  |
| 模块 | 功能 | 视图 |
|---|---|---|
| 在线RPC | 发布消息并同步获取结果 |  |
| 模块 | 功能 | 视图 |
|---|---|---|
| 任务列表 | 定时任务管理列表页 | 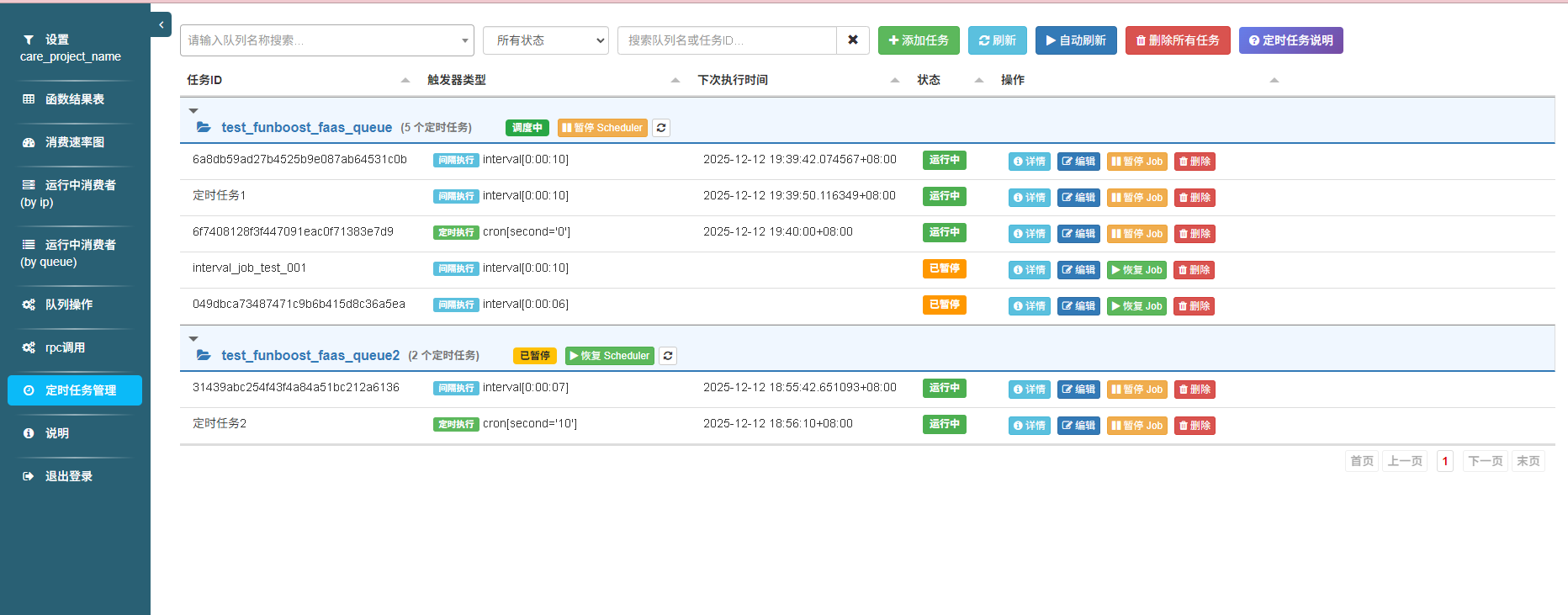 |
| 新增任务 | 添加定时任务 | 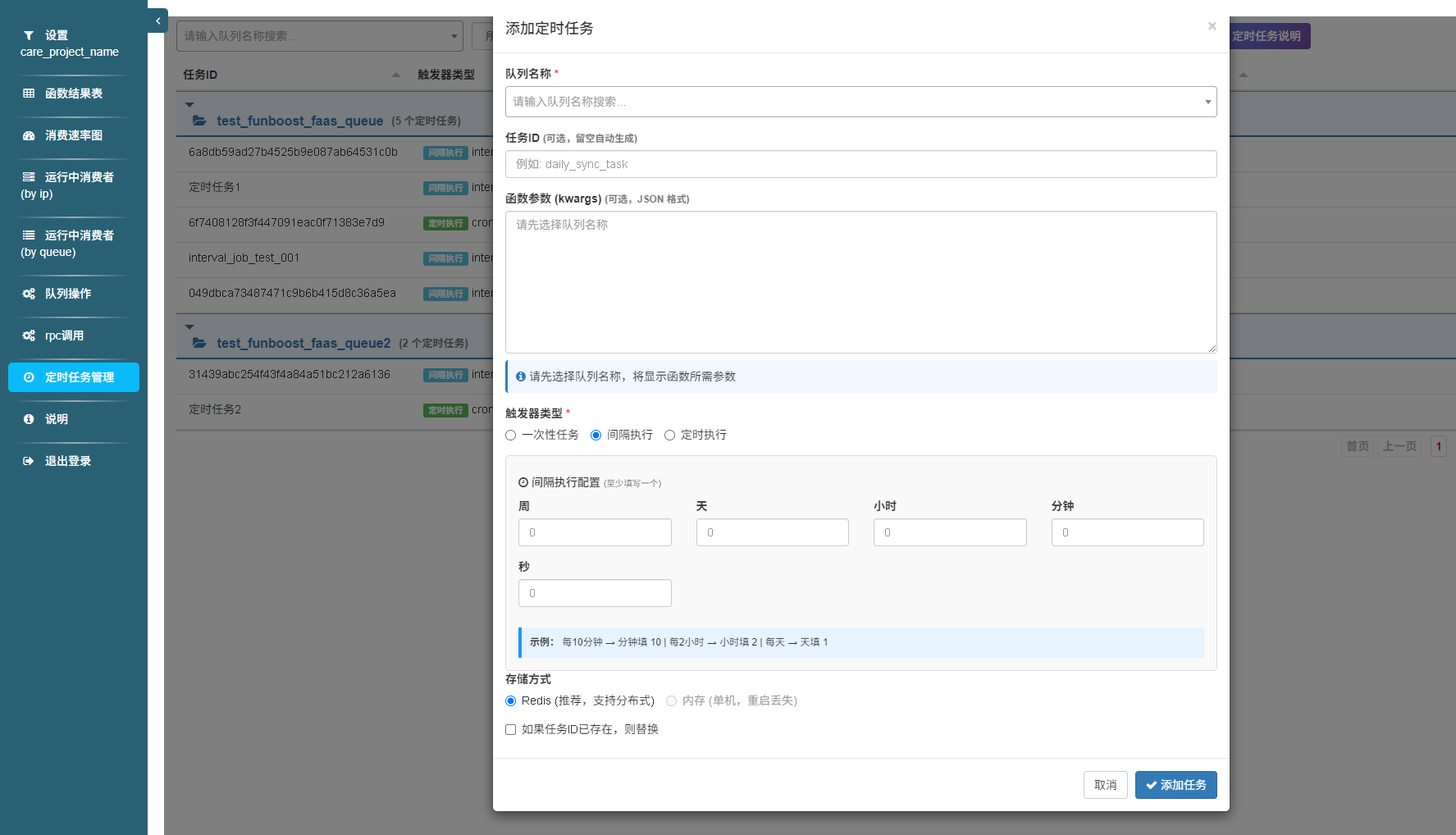 |
| 任务详情 | 查看定时任务详情 | 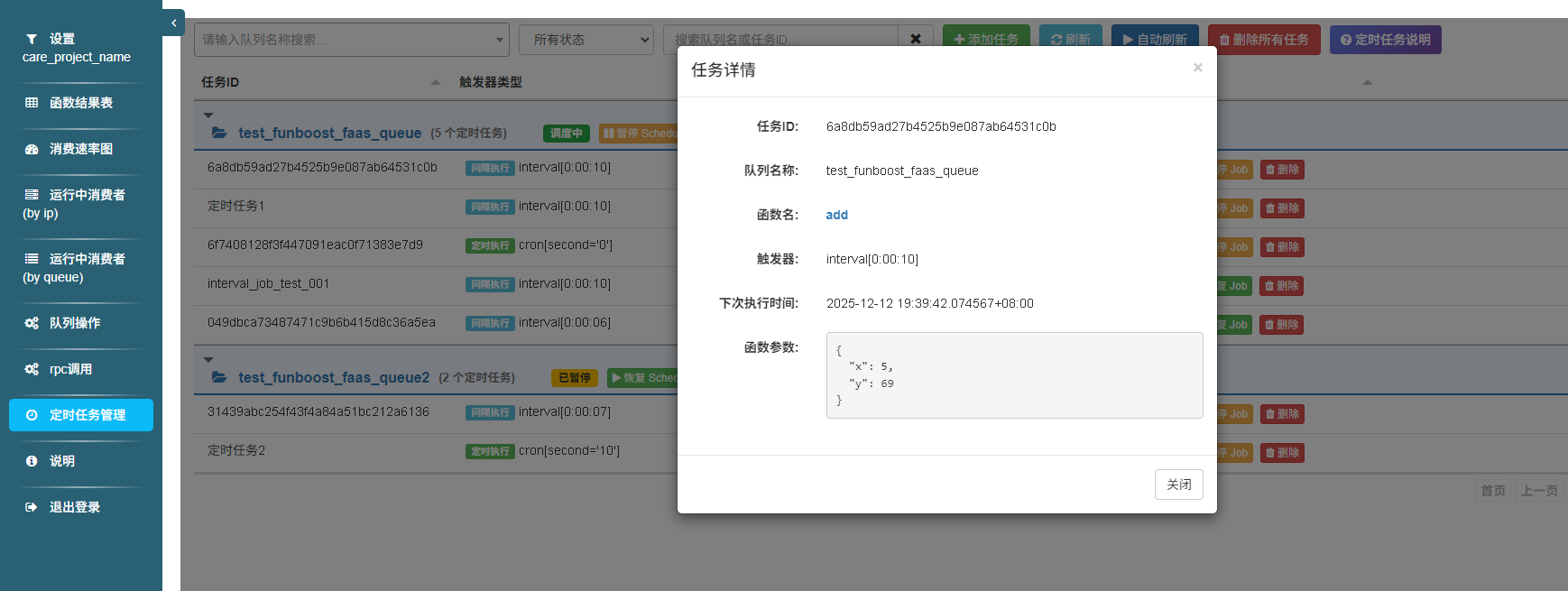 |
Python 语言的特性决定了它比 Java/Go 等语言更依赖分布式调度框架。主要原因有两点:
🛑 现状:由于 GIL (全局解释器锁) 的存在,普通的 Python 脚本无法利用多核 CPU。在 16 核机器上,CPU 利用率最高只能达到 6.25% (1/16)。 😓 难点:手动编写
multiprocessing多进程代码非常麻烦,涉及复杂的进程间通信 (IPC)、任务分配和状态共享。
✅ Funboost 的解法:
- 天生解耦:利用中间件(如 Redis/RabbitMQ)解耦任务,无法手写怎么给多进程分配任务和进程间通信。
- 无感多进程:单进程脚本与多进程脚本写法完全一致,无需手写
multiprocessing,自动榨干多核性能。
🐌 现状:作为动态语言,Python 的单线程执行速度通常慢于静态语言。 🚀 需求:为了弥补单机速度,必须通过横向扩展来换取时间。
✅ Funboost 的解法:
- 无缝扩展:代码无需任何修改,即可适应多种运行环境:
- 🔄 多解释器:同一台机器启动多个 Python 进程。
- 🐳 容器化:部署在多个 Docker 容器中。
- ☁️ 跨物理机:部署在多台物理服务器上。
- 统一驱动:Funboost 作为调度核心,让 Python 跑在集群之上,获得媲更高的系统吞吐量。
Funboost 的设计哲学是 “极简主义”。您无需阅读长篇大论,只需通过实践掌握核心:
-
🧪 实验式学习:
- 以 1.3 章节 的求和代码为蓝本。
- 修改
@boost装饰器中的参数(如qps、concurrent_num)。 - 在函数中添加
time.sleep()模拟耗时。 - 观察:观察控制台输出,体会分布式、并发和控频的实际效果。
-
✨ 一行代码原则:
- 这是最简单的框架:核心只有一行
@boost代码。 - 如果您能掌握这个装饰器,就掌握了整个框架。这比学习那些需要继承多个类、配置多个文件的传统框架要简单得多。
- 这是最简单的框架:核心只有一行
🤖 AI 助教 强烈推荐参考 [文档第 14 章],学习如何利用 AI 大模型快速精通
funboost的各种高级用法。
Funboost + Celery = 极简 API + 工业级调度核心
Funboost 现已支持将整个 Celery 框架作为底层的 Broker (BrokerEnum.CELERY)。这使得 Celery 实际上成为了 Funboost 的一个子集。
通过 Funboost 操作 Celery,您可以完全避开 Celery 原生开发的痛点:
| 🔧 核心优势对比 | 🔴 原生 Celery 的痛点 | 🟢 Funboost操作celery的爽点 |
|---|---|---|
| 简化部署:从 CLI 命令到 Python API | 需记忆复杂的命令行启动 Worker/Beat | 全自动:代码一键启动,无需记忆命令 |
| 灵活组织:适应各种项目结构 | 严格且繁琐的目录结构规划 | 零约束:任意目录,任意文件结构 |
| 降低门槛:自动发现与注册任务 | 复杂的 includes 和 task_routes 配置 |
零配置:框架自动处理路由与注册 |
| 提升开发体验:强类型提示与智能补全 | IDE 无法补全 @app.task 参数 |
全补全:BoosterParams 支持完整代码提示 |
🔗 代码示例 具体用法请参见 [11.1 章节]。您只需使用简单的 Funboost 语法,底层复杂的 Celery 调度便会自动运行。