yolo系列的学习笔记
-
-
-
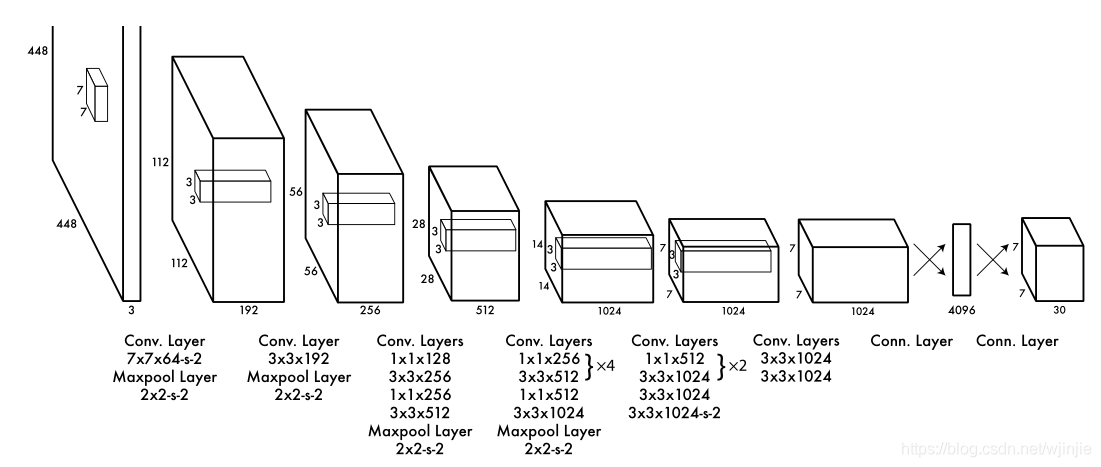
网络结构
网络输入:448x448x3的彩色图片(Yolov1输入大小是固定的,因为全连接层需要前面的大小固定)
中间层:由若干卷积层和最大池化层组成,用于提取图片的抽象特征。
全连接层:由两个全连接层组成,用来预测目标的位置和类别概率值。
网络输出:7x7x30的预测结果。(每个格子都会预测两个框,两个框中各有x,y,w,h,confidence,这些值为归一化后的结果0.几,而不是图像中的真实值。)所以30代表:5+5+20(种类)
使用合适的损失函数,使损失最小就可以得到想要的结果。
-
目标损失函数:
- 位置损失函数 :先对x,y,w,h进行选择(对每个格子中的两个框进行选择,选择IoU最大的框,代表这个框最好补救,或者最好微调,对w,h加根号,为了对小目标调整时更敏感,但是效果不是很好。)
- 置信度损失函数 :
- 含Object的:选候选框中confidence最大的与真实框比较,IoU大于阈值,
- 不含Object:IoU小于阈值。含有权重,由于不重要,所以权重设置小一点。
- 分类损失函数:20分类损失函数,使用交叉熵。计算概率。
-
NMS非极大值抑制:在测试的时候,可能会出现很多预选框,选择IoU最大的,其它的不要。
-
优点: 快速、简单。
-
缺点:
- 重合在一起东西很难检测
- 小目标无法检测,预选框是固定的,只能检测较大的物体。
- 多标签物体无法检测,比如是狗 还是斑点狗,具有多个标签。
- Batch Normalization: v2版本舍弃了Dropout,卷积后全部加入Batch Normalization (v2不存在全连接层)
- 网络的每一层的输入都做归一化,收敛更容易。
- 现在网络必备。(增加后,网络提升2%mAP)
- V2使用更大的分辨率 :
- v1训练时用224x224,测试时使用448x448
- v2刚开始训练使用224x224,最后额外加10次448x448的微调。(mAP提升约4%)
- 网络结构 :
- DarkNet19,实际输入416x416 (因为除以32能整除,商希望为奇数,这样才有实际的中心点)(借鉴VGG,GoogLeNet)
- 没有FC层,5次下采样。(全连接层容易过拟合,参数多,训练慢),最终输出特征图大小为 w/32 , h/32。实际输出为13x13 。(特征图越大,特征越多)
- 使用1x1卷积,减少参数。卷积核全为3x3(借鉴VGG),1x1(借鉴GoogLeNet)
- v2-聚类提取先验框 :
- yolov1使用两个先验框。faster-rcnn使用9种不同的先验框。
- yolov2中使用k-means聚类提取先验框。k=5。对训练数据集中的具体目标大小先进行聚类,得出5类大小不同的先验框,再根据这5类中的中心点,作为代表先验框。这样就使得先验框更合理一些。
- k-means中的距离:不是使用欧式距离,因为有的先验框大,误差就大。d = 1 - IoU
- K越大,先验框越精确。

- 特点:
- 最大的改进是网络结构,使其更适合小目标检测。
- 特征做的更细致,融入多持续特征图信息来预测不同规格物体。
- 先验框更丰富,3种scale,每种3个规格,一共9种。(V1:2种,v2:5种,v3:9种)
- softmax改进,预测多标签任务。
- 多scale:为了能检测到不同大小的物体,设计了3个scale
- 一共三种scale:13x13预测大的,26x26预测中等的,52x52预测小的物体。
- 每个scale种,产生3个不同大小的候选框。
- scale变换经典方法
- 图像金字塔:对特征图做不同resize,排成图像金字塔,每层做预测。(速度慢)
- 特征金字塔 :13x13特征图不仅做预测,并且,对13x13特征图做上采样变为26x26,与原来26x26特征图进行融合,得出26x26特征图的预测。(特征图越小,越靠后,感受野越大,看到的东西越多,可以上采样后,与较大的特征图进行融合,相当于给浅层的特征图一些建议 )
- 残差连接:更好的特征(借鉴ResNet的思想)
- 没有池化和全连接层,全是卷积
- 下采样通过stride为2实现
- 3中scale,更多的先验框。(其中一个scale:13x13x3x85)
- 网格大小13x13,3指一个scale中预测三个box,80为样本类类别,5代表x,y,w,h,confidence
- softmax层替代:(logistic激活函数)
- 物体检测任务中可能一个物体有多个标签。
- logistic激活函数来完成,这样就能预测每一个类别是/不是。最终按照confidence与阈值的比较,大于阈值的取出即可。就可以得到多标签分类。
- 改进:
- 单GPU就能训练的非常好。
- BOF
- Bag of freebies(BOF):扩充数据量,使数据有更强的泛化能力。
- 增加训练成本,提高精度,但不影响推理速度。
- 数据增强:调整亮度,对比度,色调,随机缩放,剪切,翻转,旋转。
- 网络正则化方法:Dropout、Dropblock等:(随机吃掉一个区域)
- 类别不平衡,损失函数设计。
- Label Smoothing:神经网络太容易过拟合,很自信,所以不让太自信。使原本(0,1)变为[0.05,0.95],是网络永远达不到最完美。
- Bag of special (BOS):网络层面的多样性增加
- 增加推断代价,但是提高了精度。
- SPPNet(Spatial Pyramid Pooling):用最大池化来满足最终输入特征一致。
- CSPNet(Cross Stage partial Network):没一个block按照特征图的channel维度拆分成两部分,一份正常走网络,一份直接concat到这个block的输出。
- CBAM:加入注意力机制。
- 注意力机制:分为两部分,(1.有些特征图重要,有些不重要,就分大小比例。2.空间上,有些地方重要,有些地方不重要,划分比例。)
- PAN(Path Aggregation Network):特征金字塔中双向传递。
- Mish激活函数:不一棒子打死,给<0,靠近0的一个机会。
-
不同点:
- 输入端:Mosaic数据增强、自适应锚框计算
- BackBone:Focus结构,CSP结构
- Neck:FPN+PAN结构
- Prediction:GIOU_Loss
-
Mosaic数据增强
-
自适应锚框计算:
-
自适应图片缩放:图片长宽不同时,常用方式为将原始图片统一缩放到一个标准尺寸。就需要对图片缩放或填充。填充后两端的黑边大小都不同,而填充过多,则存在信息冗余,影响推理速度。
但是Yolov5在datasets.py中的letterbox函数中进行修改,对原始图像自适应的添加最少的黑边。
-
Focus结构:yolov4中没有,关键的是切片操作。
-
CSP结构:Yolov4中只有主干网络使用了CSP结构,而Yolov5中设计了两种CSP结构
-
Neck:Yolov4的Neck中,采用的都是普通的卷积操作。Yolov5中Neck结构采用借鉴CSPNet设计的CSP2结构,加强网络特征融合的能力。
-
Yolov5中采用其中的CIOU_Loss做Bounding box的损失函数。
-
Yolov4在DIOU_Loss的基础上采用DIOU_nms的方式,而Yolov5中仍然采用加权nms的方式。(可以进行修改:对于一些遮挡重叠的目标,确实会有一些改进。)
- 当前目标检测主要的优化方向:更快更强的网络架构;更有效的特征集成方法;更准确的检测方法;更精确的损失函数;更有效的标签分配方法;更有效的训练方法。
- Input:整体复用yolov5的预处理方式和相关源码。(注意:官方使用的是640x640和1280x1280这样较大图片做训练和测试)
- backbone:主要使用ELAN(并没有使用论文中最复杂的E-ELAN结构)和MP结构。激活函数:silu
- ELAN结构:通过控制最短最长的梯度路径,更深的网络可以有效地学习和收敛。(不破坏原有梯度路径的情况下,不断增加网络学习能力)
- MP结构:之前下采样使用maxpooling,之后选择使用stride=2的3x3卷积。(小孩子才做选择,我都要)MP结构同时使用了maxpooling 和stride=2的conv。MP前后通道数不变。
- neck和head:检测头整体结构和yolov5相似,仍然使用anchor based结构,仍然没有使用yolox和yolov6的解耦头(分类和检测)思路。
- SPPCSPC结构
- ELAN
- MP结构(与backbone中的参数不同)
- 比较流行的重参数化结构Rep结构。
- 主要思路是利用CNN提取特征后,均匀的在图片的不同位置进行密集抽样,抽样时可以采用不同尺度和长宽比,物体分类与预测框的回归同时进行,整个过程只需要一步,所以其优势是速度快。
- Single Shot MultiBox Detector,Single shot 说明SSD算法属于one-stage方法,MultiBox说明SSD算法基于多框预测。
- SSD采用的主干网络是VGG网络。
- 将VGG16的FC6和FC7层转化为卷积层。
- 去掉所有的Dropout层和FC8层
- 新增了Conv6、Conv7、Conv8、Conv9。
- SSD采用CNN直接进行检测。
- SSD提取不同尺度特征图做检测。
- SSD采用不同尺度和长宽比的先验框。
- SSD相比yolo的不同点。
- SSD采用CNN来直接进行检测,而不是像Yolo那样在全连接层之后做检测。
- SSD提取不同尺度的特征图来检测,大尺度特征图(较靠前的特征图)可以用来检测小物体,而小尺度特征图(较靠后的特征图)用来检测大物体。
- SSD采用了不同尺度和长宽比的先验框(Prior boxes,Default boxes,在Faster R-CNN中叫做锚,Anchors)。Yolo算法缺点是难以检测小目标,而且定位不准。
- SSD将背景当做一个特殊的类别,如果检测目标共C个类别,SSD需要预测C+1个置信度,其中第一个置信度是不含目标或背景的评分。 [图片]
- 预训练模型:选择一个神经网络(AlexNet、VGG)
- 重新训练全连接层:使用需要检测的目标重新训练全连接层。
- 使用selective search提取region proposals
- 使用SVM实现分类:使用Feature Map训练SVM来对目标和背景进行分类。
- 边界框回归:训练将输出一些校正因子的线性回归分类器。
- 缺点:重复计算,每个region proposal,都需要经过一个AlexNet特征提取。selective search方法生成region proposal,对每一帧图像,需要花费2秒。三个模块(提取、分类、回归)是分别训练的,并在训练时,对于存储空间消耗较大。
- 基于R-CNN与SPPNets进行改进。(SPPnets的创新点是只进行一次图像特征提取,而不是每个候选区域计算一次,根据算法,将候选区域特征映射到整张图片特征图中。)
- 流程:
- 使用selective search生成region proposal候选框。
- 训练时,缩放图片的scale得到图像金字塔,FP得到conv5的特征金字塔。
- 对于每个scale的每个RoI,求映射关系,在conv5中剪裁出对应的patch.并用一个单层的SSP layer来统一成一样的尺度
- 进行两个全连接得到特征,特征分别共享到两个新的全连接,连接到两个优化目标。第一个优化目标为分类,使用softmax,第二个优化目标是bbox regression,使用了一个平滑的L1-loss
- 测试时,加入NMS处理:利用窗口得分分别对每一类物体进行非极大值抑制提出重叠建议框,最终得到每个类别中回归修正后的得分最高的窗口。
- 加入了Rol Pooling,采用一个神经网络对全图提取特征。
- 在网络中加入了多任务函数边框回归,实现了端到端的训练。
- 缺点:采用selective search提取region proposal。无法满足实时应用。利用了GPU,但是region proposal方法在CPU上实现。
- 流程:
- 首先使用一组基本的卷积/激活/池化层提取图像的特征,用于后续的RPN层和全连接层。
- Region proposal network(RPN)。用于生成候选区域,该层通过softmax判断锚点(Anchors)属于前景还是背景,再使用bounding box regression(包围边框回归)获得精确的候选区域。
- RoI Pooling。收集输入的特征图和候选区域,提取候选区特征图,送到后续全连接层判断目标的类别。
- Classification。利用候选区特征图计算所属类别,并再次使用边框回归算法获得边框最终的精确位置。
- 改进:
- 提取Region proposal Network(RPN),取代selective search,生成待检测区域。
- 真正实现了端到端的检测。
- 共享RPN与Fast R-CNN的特征。
- 缺点:无法实时检测目标。获取region proposal,再对每个proposal分类计算量较大。