Use database store for media library #316
Conversation
| $table->integer('parent_id')->unsigned()->nullable(); | ||
| $table->integer('nest_left')->unsigned()->nullable(); | ||
| $table->integer('nest_right')->unsigned()->nullable(); | ||
| $table->integer('nest_depth')->unsigned()->nullable(); |
There was a problem hiding this comment.
I'm concerned keeping the nested tree data in sync with the path would be more complicated than just using the path by itself. We should be able to do queries based on the path, and we wouldn't want order inside of a path to be determined by integers in the database rather than the file attributes like path, size, date modified, etc.
There was a problem hiding this comment.
I felt using nested set will make it easy to modify hierarchical data in bulk, as opposed to using any form of parent_id or trying to substring a path to work out multiple levels of child structure.
I definitely wasn't going to use it for ordering, that'll just be name, size, date modified as it is now.
There was a problem hiding this comment.
Well I'll wait to see the implementation but I'm concerned about the reliability
There was a problem hiding this comment.
I've used its abilities here:
https://github.com/wintercms/winter/pull/316/files#diff-cd9950fa78d52abcf50430faf1b4d47b0ece142fbef305253728d05ac684d7d1R170
and here:
https://github.com/wintercms/winter/pull/316/files#diff-cd9950fa78d52abcf50430faf1b4d47b0ece142fbef305253728d05ac684d7d1R207
so far. It's been really good for traversing the whole structure underneath a particular item.
There was a problem hiding this comment.
A competing CMS solved this using a variation of path enumeration:
https://github.com/drupal/drupal/blob/9.3.x/core/lib/Drupal/Core/Menu/MenuTreeStorage.php#L529 (they do limit the depth to 10 levels)
Also based on the below comparison nested sets are somewhat more "difficult"
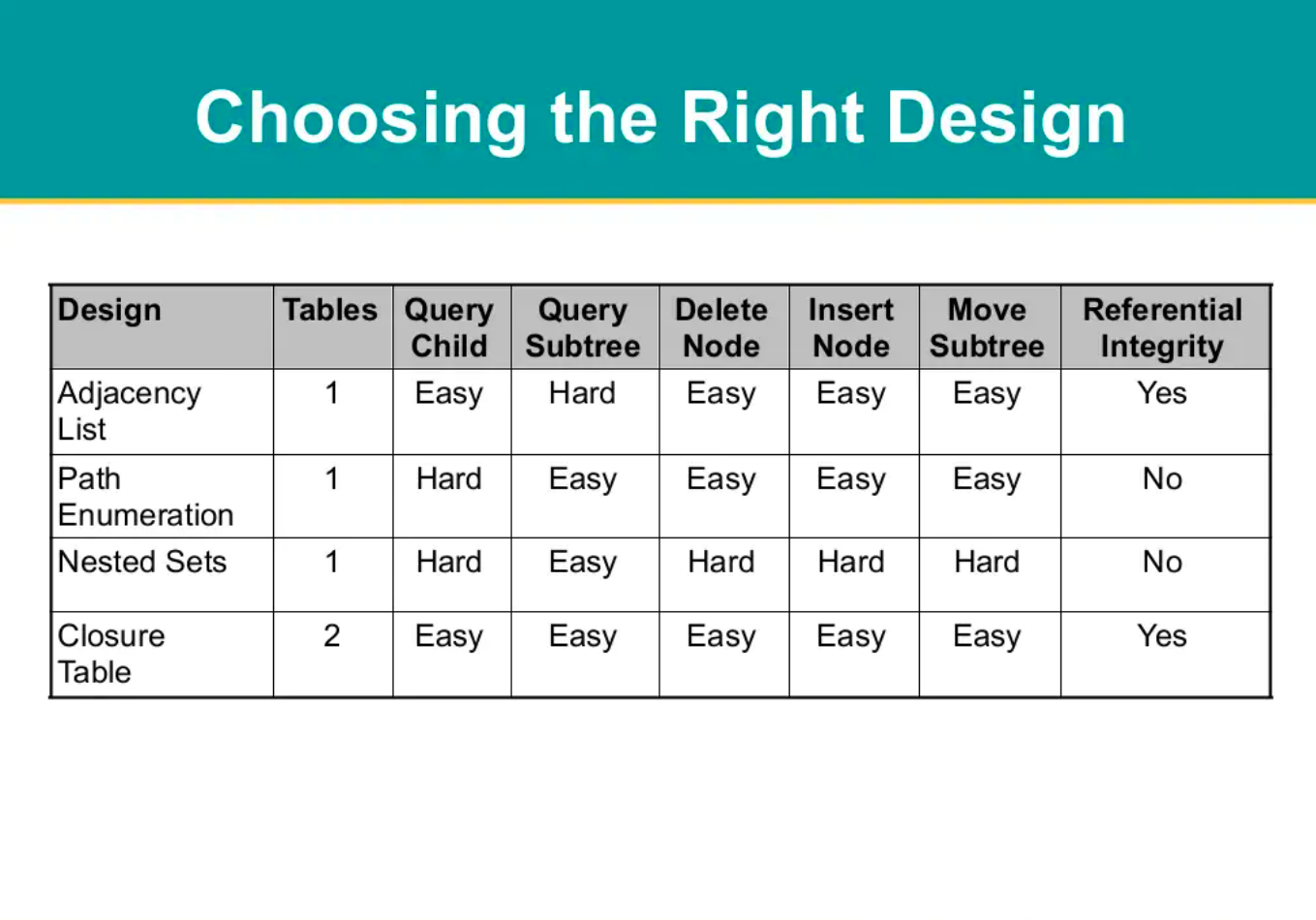
There was a problem hiding this comment.
@lex0r really sorry for the delay in responding to this.
Thanks for posting that, however, I slightly disagree with what it puts forward. While nested sets might be hard to wrangle if you build the functionality from scratch, we already have a NestedTree trait which does all the heavy lifting, so it's trivial for us to use.
All the actions - querying, deleting, inserting and moving - are simple through this API.
I'm not quite sure what the "referential integrity" column refers to, however, my previous experience with nested trees finds them to be incredibly reliable and auditable. They can even be easily repaired.
The SimpleTree trait handles the "Adjacency List" design you mention, but as your diagram mentions, it's harder to query a subtree, and more to the point, that's a design fault - you have to run several queries in order to find the full subtree, which is not useful in this case if we want to do filtering and searching. Nested set, by design, handles this flawlessly.
There was a problem hiding this comment.
Hi @bennothommo
I agree with your argument that NestedTree trait is trivial to use, and I understand your experience using them may be positive, but I'd like to share my experience with them in a real world project. To keep it short, nested sets don't survive parallel modifications of the tree structure, and if that happens they are guaranteed to get corrupted. For me it's a big no when it comes to applications used by more than 1 person. I appreciate they are easy to fix (thanks to the parent ref) but why fixing what shouldn't even break?
On the other hand, path enumeration (also known as materialised path) is used in many CMS like Drupal (sorry for repeating that again) and it handles parallel modifications to the trees easily. To make it more attractive, I will mention that I was able to easily implement it using a very slightly modified version of https://github.com/vicklr/materialized-model.
Hope you could give it a try.
There was a problem hiding this comment.
@lex0r thanks for the further feedback.
I would think in your case that corruption of the nested set could be easily resolved by implementing table locking, so there would be no race condition on multiple writes. But I digress.
I would have to see the benchmarks, but path enumeration seems to me - based on my knowledge on MySQL - that it might be slow for reading large datasets and querying individual nodes and sub-nodes, which we're likely to have with media storage. I've heard of people with hundreds of thousands of files within their media libraries. The diagram above says its easy, but it's relying on string parsing which is AFAIK not the greatest performance-wise in SQL.
I'll run some tests though - if it does happen to be fast, then I'll certainly consider it. If you have access to some benchmarks of the different types of hierarchical data, that would be most helpful.
There was a problem hiding this comment.
@bennothommo benchmarking should help, and an obvious performance improvement for the path enumeration concept is to have all path components as individual columns, eg. p1, p2, p3 .. p10, where pN is an ID rather than a string. This will limit the depth but rarely people need a super deep nesting. Alternatively, having an index on the path is a scalable approach especially when talking about the ID-based path (/1/123/544) not the file path (/content/images/abc). The index will be small as only IDs are stored, which are shorter strings, unlike path component strings, and it will be used in all searches starting with a known prefix (which I guess is always known).
Table locking is a big performance killer, I tried that and it left me surprised with how slow it can be, so can't recommend it as a solution for a modern multi-user CMS.
modules/system/database/migrations/2021_10_02_000026_Db_Media_Items.php
Outdated
Show resolved
Hide resolved
| 'folder_size_items' => 'item(s)', | ||
| 'metadata_image_width' => 'Width', | ||
| 'metadata_image_height' => 'Height', | ||
| 'metadata_video_duration' => 'Duration', |
There was a problem hiding this comment.
metadata should be an array with subitems under it so that keys are metadata.image_width instead of metadata_image_width - this will reduce the unnecessary duplication of the metadata_ prefix.
This PR will use the database for tracking file and folder metadata, and adds the grass-roots functionality to allow extension of media item metadata (#16)
The benefits of using the DB to handle this sort of data include:
The media manager will scan the file system on first use and populate the media metadata table - this has not yet been tested with remote filesystems or an extreme amount of files, but works with around 100 images in a couple of seconds. The intention is to make an Artisan command which can run the scan, but I'm sure optimisations can be made. Subsequent scans will compare the stored metadata with the filesystem and will only update files or folders that have been added, modified or removed.
More details on this PR will be forthcoming once it's closer to completion - it works now for browsing at the least.