Reliability Reasoner
All of the software artefacts for runtime support produced in tasks 2.1 and 2.2 have certain knowledge about the operation of the system, especially the artefacts of the middleware. Here, the expert group will analyze how this knowledge can be shared as context info for increasing the reliability in system and adding diagnostic features.
D1.3C(IV) defines Common Providers as: "A placeholder for the provision of specific context data considered as basic or of common use. Those components that provide such commonly needed context data are the common providers represented by this building block. The provision of context, however, can be a matter of 'configuration' using the reasoning facilities of Context Management from the lower layer. Up-lifters represent the possibility for plugging in such context providers. For example, if the aforementioned reasoning facilities include a configurable rule engine, concrete rules added to the repository of the reasoning engine can be classified as such up-lifters."
Common Rules definition comes also from D1.3C(IV): "Assuming that the Automatic Situational Assistance from the lower layer provides facilities for dynamic configuration of the system behaviour in reacting and pro-acting, then this building block is serving as a placeholder for such configuration rules that, for instance, define which actions to perform under which conditions.". Same definitions appear in D1.3D.
High-level requirements
RC9_R1: Dependability: The universAAL architecture shall support the delivery of services that can justifiably be trusted, where the service is the intended behavior of the system. The system must be resilient with respect to unanticipated behavior from the environment or of subsystems (e.g., transient and permanent hardware faults, design faults).
Technical requirements
RC9_TR2: Design for Testability Testability shall be supported by the architecture (design testing, system-integration testing, manufacturing testing and assembly testing).
RC9_TR6: Unreliable Components The architecture must be capable to tolerate the failure of individual devices and inter-connects.
RC9_TR7: Fault Hypothesis Assumptions shall be identified that define the type and frequency of faults that the sys-tem has to be able to tolerate
RC9_TR10: Consistent membership Service A membership service shall exist within the architecture that consistently provides sub-systems with the health state of other subsystems.
RC9_TR14: Fault Classification Error-detection mechanisms provided by the architecture have to distinguish between transient and permanent faults.
RC9_TR19: No Probe Effect There must be no interference from the diagnostic service on the subsystems that are diagnosed.
RC9_TR20: Systematic Diagnostic Methods The detection of application-independent failures modes (e.g., communication errors) should be supported by providing systematic diagnostic methods.
RC9_TR21: Application-specific Diagnostic Methods Diagnostic services should be configurable to enable the detection of application-specific failures.
RC9_TR22: State Enforcement It shall be possible to set the history state of a subsystem.
RC9_TR23: Different Levels of Reliability The architecture shall provide different levels of reliability of the communication service.
RC9_TR24: Handling of Changing Reliability Fault tolerance mechanisms shall be capable of adapting to changed reliability of subsystems over lifetime.
In this phase of the development the work done from the reliability point of view will be presented. Therefore, in the following the fault diagnosis procedure is described using situation reasoner.
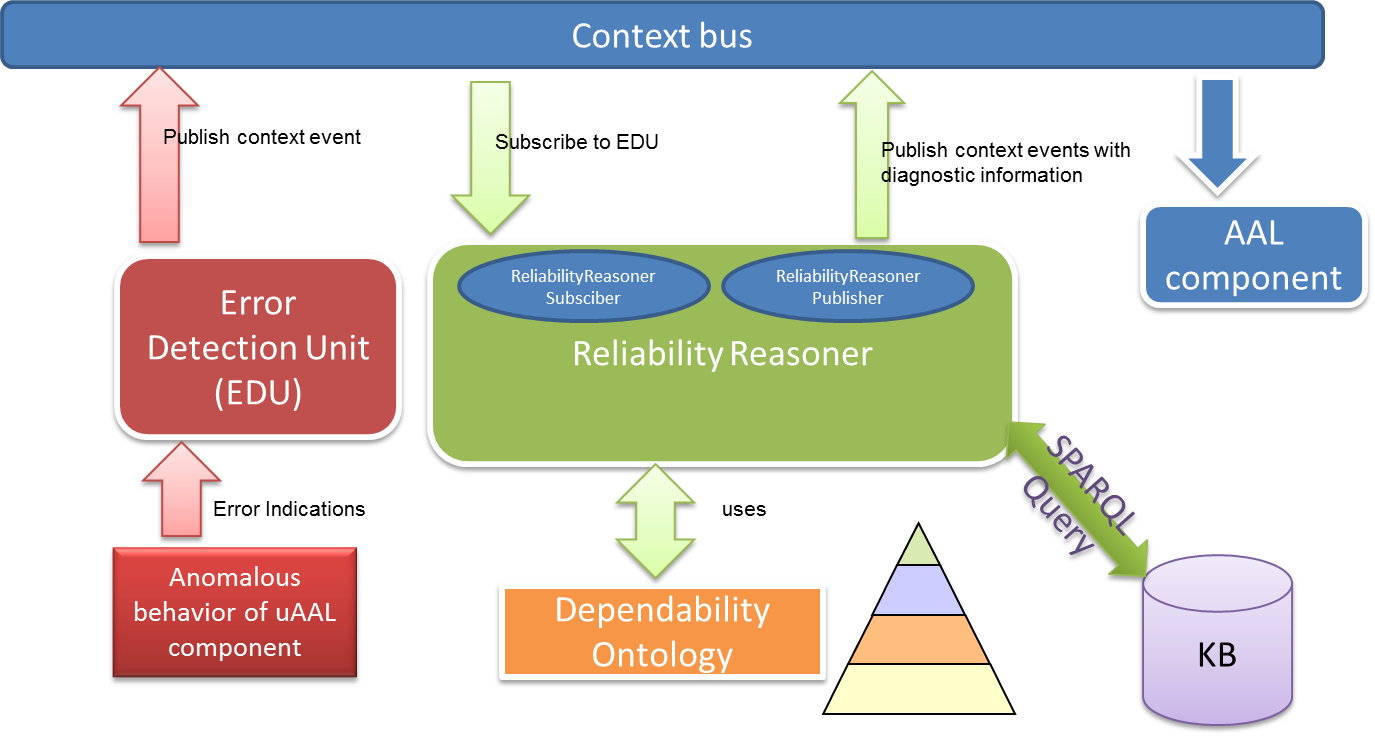
From the context bus, the context events related to faults are taken as symptoms for a failure. These symptoms are analyzed by a priori knowledge of the FCR and the related static knowledge on the associated failure mode. These symptoms are further queried by Situation Reasoner with the help of the KB (Knowledge Base). These symptoms can be analyzed either in a rule based approach or simple SPARQL query. Then the SR will publish the context event with the diagnosis information into the context bus. This diagnosis information includes the Fault recovery steps that have to be adopted for the specific failure modes for that specific FCR. The fault recovery also includes the exchange of the configuration parameters with the control bus.
The completed tasks include constructing an ontology http://forge.universaal.org/wiki/ontologies:Dependability# Dependability Ontology based on the RDF schema for diagnosis framework (See Middleware wiki for detailshttp://forge.universaal.org/wiki/middleware:Reliability_Building_Block#universAAL_Diagnosis_Framework). Once the ontology is constructed, the relationships among the entities are determined. The completed work also includes defining the rules (see next section) for diagnosis so that those rules can be accumulated in the Knowledge Base, KB (i.e. in Context History Enteprot, CHE).
In this section, several high level rules for Diagnosis analysis will be defined. As specific faults depend on the specific application (e.g. rules for the faults of a mobile device are quite different than rules for faults in case of an ethernet cable cut ), the high level rules give the upper layer initiatives for the upper layers (to be specific context bus layer) to reason on different faults, based on Dependability Ontology and to take necessary actions. The rules can be numerous. But the basic rules are as follows. The threshold values are based on alpha count threshold mechanism.
- If the FCR shows Fault for consecutive 100 times, then FCR is PermanentFault
- If the FCR shows ValueFault for consecutive 100 times, then FCR is PermanentFault
- If the FCR shows TimingFault for consecutive 100 times, then FCR is PermanentFault
- If the FCR shows EarlyTimingFault for consecutive 100 times, then FCR is PermanentFault
- If the FCR shows LateTimingFault for consecutive 100 times, then FCR is PermanentFault
- If the FCR shows Fault consecutively for less than 10 times, then FCR is TransientFault
- If Middleware shows Fault, then Middleware is a FCR and go to (Rule 1 or Rule6)
- If FCR shows TransientFault, then publish timestamp of the TransientFault of that FCR
- If FCR shows ParmanentFault, then publish timestamp of the ParmanentFault of that FCR
- If FCR shows ParmanentFault, then publish RecoveryAction for the ParmanentFault of that FCR
The Error Detection Unit is described in the Middleware Expert Group, as part of the Reliability Building Block, since it is closely tied to that. The specific Reliability Reasoner, being a higher level Context-related manager, is explained here.
The Reliability Reasoner is a specialized version of Situation Reaonser with a special purpose of integrating failure diagnosis rules using the Dependability Ontology. As in Situation Reasoner, Reliability Reasoner has two main modules.
- Reliability Reasoner Publisher
- Reliability Reasoner Subscriber
| Artifact: Reliability Reasoner | |
|---|---|
| Maven artefact | org.universAAL.context / ctxt.reliability.reasoner |
| OSGi Composite bundle | scan-composite:mvn:org.universAAL.context/ctxt.reliability.reasoner/x.y.0/composite |
| SVN Address | <svn>/uaal_context/trunk/ctxt.reliability.reasoner |
| Continuous Integration | <ci-context>/org.universAAL.context$ctxt.reliability.reasoner |
| Javadoc | <ci-context>/site/ctxt.reliability.reasoner/apidocs/index.html |
| Maven Release Repository | <maven-release-context>/ctxt.reliability.reasoner |
| Maven Snapshot Repository | <maven-snapshots-context>/ctxt.reliability.reasoner |
- RC9_TR1 Modular Certification of Subsystems
- RC9_TR6 Unreliable Components
- RC9_TR7 Fault Hypothesis
- RC9_TR8 Error-Containment
- RC9_TR9 Minimum of two Fault-Containment Regions
- RC9_TR12 Tolerance of Software Errors
- RC9_TR14 Fault Classification
- RC9_TR17 Mixed-Criticality Subsystems
- RC9_TR18 Diagnostic Service
- RC9_TR19 No Probe Effect
- RC9_TR20 Systematic Diagnostic Methods
- RC9_TR21 Application-specific Diagnostic Methods
- RC9_TR22 State Enforcement
- RC9_TR23 Different Levels of Reliability
- RC9_TR24 Handling of Changing Reliability
This artefact offers the following features.
- Diagnositic rules for failure
- Using the error indication by Error Detection Unit
- Reasoning on root-cause of a failure
- Making decisions on detected error events
The Reliability Reasoner is a special modification of the Situation Reasoner that uses the database of CHE and the ontological reasoning of its storage engine and builds up new contextual information using the power of the RDF query language SPARQL. It stores situation queries persistently and indexes them based on context events that must trigger its evaluation as they are not meant as a one-time query that are answered and then forgotten, but they must generate related situational events whenever appropriate, depending on changes in the context.