[FIX] keep context #1
Conversation
|
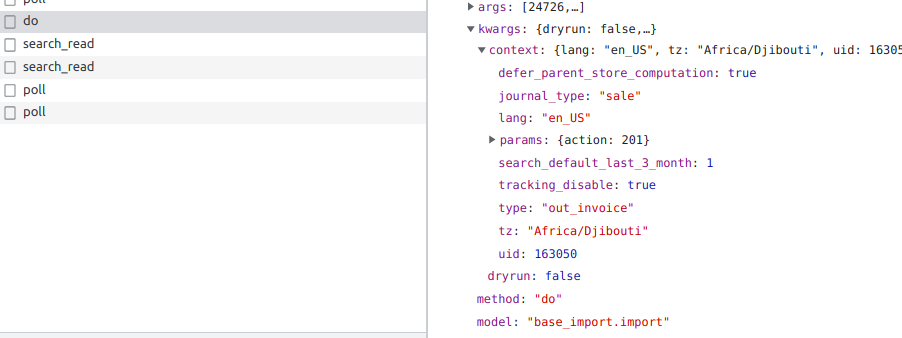
@KKamaa the backport looks OK, although we are supposed to cherry-pick the commit(s) from 13.0 to keep the original author. We should keep that in mind when submitting to OCA, but for now I'll already be happy if this works functionally. However, it doesn't work yet :-/. I confirmed that the code is updated on nightly, and I tried to import the "minified" file that was attached in the issue. The correct context is passed to the "do" function:
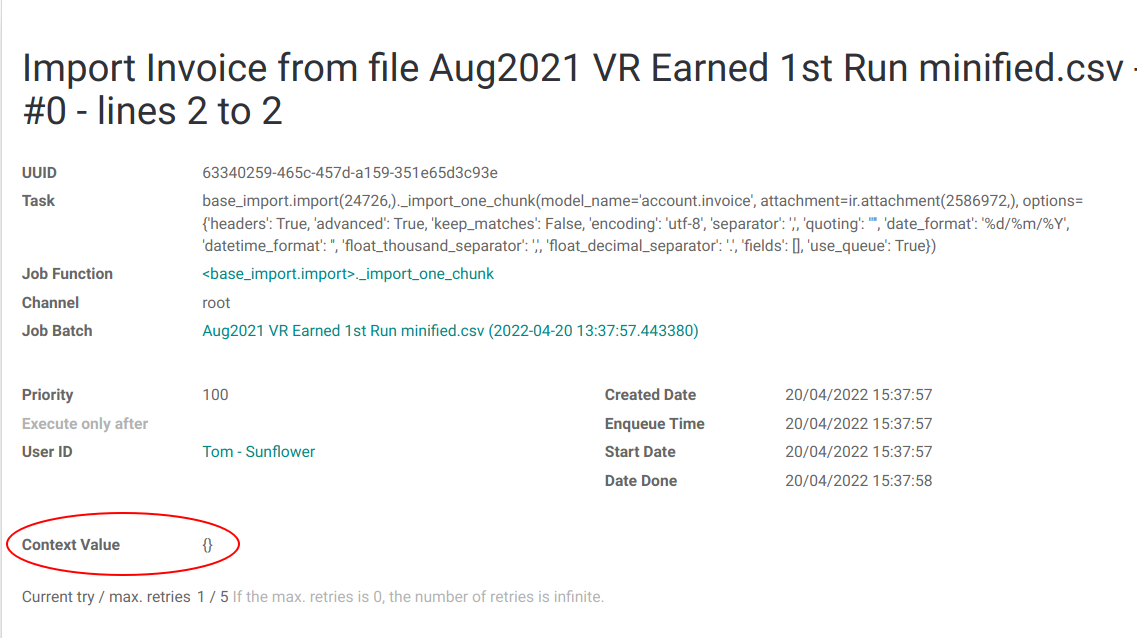
But does not arrive on the job:
Could you debug why not? |
4cbe14b to
bb7909e
Compare
9691bfe to
c761ca2
Compare
queue_job/job.py
Outdated
| date_created = dt_to_string(self.date_created) | ||
| # We store the original context used at import on create | ||
| ctx = self.env.context.copy() or '{}' | ||
| vals.update({'original_context': json.dumps(ctx) or ''}) |
There was a problem hiding this comment.
@KKamaa I don't understand in which cases this would be different from context.
To me the code looks like this:
vals.update({"context": json.dumps(self.env.context.copy())} # line 518
... some code that does not seem to modify `vals['context'] in any way
vals.update({"original_context": json.dumps(self.env.context.copy())} # line 537
What am I missing? Can you give an example of a situation where context would end up different from original_context ?
There was a problem hiding this comment.
@thomaspaulb about the field original_context I added it to just show how the context we are using changes in execution of the queue job. When we create the queue job we have the entire import context, however when we start executing it the context is lost/modified. So I save the execution from the beginning in original_context field, then from there use what was saved and current context execution the update to use when executing the queue.job so:
{'params': {action: 23}} + {'lang': Fr_fr'} = {"params": {action: 23}, "lang': "Fr_fr"} for example
about the astor lib wasn't that successful with it and changed the part which was having issues. So if context contained a record say job.batch(1,) it was hard in conversion. So I changed where job_batch was being assigned the record class instead of the id. I had added samples on the issue.
So maybe we can just use context alone buy converting it the update it with current context then save again until the queue job is done. Just did a separate to have a proper sample test of the import working.
There was a problem hiding this comment.
Ahhh i get it... I think.
So in the original context you have things like 'lang' and 'invoice_type' which are saved to context
Then in the queue job execution some things are added such as 'job_uuid' (anything else?)
So if you combine both, then it should be good.
| self.cr.execute('delete from queue_job') | ||
| batch = self.env['queue.job.batch'].get_new_batch('TEST') | ||
| self.assertFalse(batch.job_ids) | ||
| model = self.env['test.queue.job'].with_context( |
There was a problem hiding this comment.
@thomaspaulb the culprit was such line which made the conversion have issues when we assign batch record instead of the batch.id
There was a problem hiding this comment.
Hey, I think we were going about this totally the wrong way, because we did not understand the original PR.
Instead of using a text or JSON field, they're actually (JSON-)encoding the original context in a variable keep_context using the JobEncoder, which also encodes other details about the job.
Then instead of using self.keep_context as a boolean flag in the way we're doing now, they're using:
if isinstance(self.keep_context, list):
context = {k: context.get(k) for k in self.keep_context}
So this then reinstates the context keys that were saved in that variable, one by one.
I guess if that works, then it avoids 1) Deviating from the other PR and 2) spending time getting our own JSON conversion right
The only comment on the current original PR was that by default it does not keep context, and most reviewers want it to keep context by default, and I agree with that too
There was a problem hiding this comment.
It already takes care of properly encoding and decoding Odoo recordsets:
https://github.com/OCA/queue/blob/11.0/queue_job/fields.py#L31
queue_job/job.py
Outdated
| vals.update({'channel': self.channel}) | ||
|
|
||
| self.env[self.job_model_name].sudo().create(vals) | ||
| job = self.env[self.job_model_name].sudo().create(vals) |
There was a problem hiding this comment.
We're not really using this job variable anywhere.
queue_job/job.py
Outdated
| date_created = dt_to_string(self.date_created) | ||
| # We store the original context used at import on create | ||
| ctx = self.env.context.copy() or '{}' | ||
| vals.update({'original_context': json.dumps(ctx) or ''}) |
There was a problem hiding this comment.
Ahhh i get it... I think.
So in the original context you have things like 'lang' and 'invoice_type' which are saved to context
Then in the queue job execution some things are added such as 'job_uuid' (anything else?)
So if you combine both, then it should be good.
| self.cr.execute('delete from queue_job') | ||
| batch = self.env['queue.job.batch'].get_new_batch('TEST') | ||
| self.assertFalse(batch.job_ids) | ||
| model = self.env['test.queue.job'].with_context( |
There was a problem hiding this comment.
Hey, I think we were going about this totally the wrong way, because we did not understand the original PR.
Instead of using a text or JSON field, they're actually (JSON-)encoding the original context in a variable keep_context using the JobEncoder, which also encodes other details about the job.
Then instead of using self.keep_context as a boolean flag in the way we're doing now, they're using:
if isinstance(self.keep_context, list):
context = {k: context.get(k) for k in self.keep_context}
So this then reinstates the context keys that were saved in that variable, one by one.
I guess if that works, then it avoids 1) Deviating from the other PR and 2) spending time getting our own JSON conversion right
The only comment on the current original PR was that by default it does not keep context, and most reviewers want it to keep context by default, and I agree with that too
|
@thomaspaulb so you were right on it so I saw that you can pass the so same code remains but added the JobEncoder/Decoder classes as parameters when calling the json function. I was hoping we keep the original_context field, so that in case of any necessary issues we can always check what was the original context when we were doing an upload. But internally the two are used as one by updating the contet dictionary as the context changes. |
c6a8b9a to
aae957e
Compare
aae957e to
4fc4f80
Compare
@thomaspaulb added the WIP from the backport v13.0