Is it possible to create model that not only understand human’s narrative but also evaluate it? Our journey begins with this purpose to create model that distinguish various latent themes in many stories and compare it to human’s recalls of each story. Our purpose is concentrated in three parts. First one is to make model that could judge a variety of stream of the story. The second is the model to figure out sequential orders of each story. last is to make a model that can find useless or inadequate parts out in a human’s recall. Specifically, we use topic modeling of LDA method.
The experiment was conducted by a story called PuruPuru’s egg. To distinguish the dynamic content of the PuruPuru story and compare with subjects’ recalls, we used a topic modeling to discover story’s latent theme. Topic model takes as inputs a sentence of documents and a collections of document and generate two output matrics. First one is a topics matrix whose rows are topics and whose columns are words of vocabulary. The entries indicate how each word is important by each topic. The Second matrix is a topic-proportions matrix, which show how each document is comprised with mixture of topics.
The dataset is collected as original story of PuruPuru’s egg hand-segmented to consider the context. In this process, there was a problem of how long it should be divided when dividing documents into sentences. Therefore, when training the topic model, a verification process was required to find out what the appropriate length of the sentence was.
In topic modeling, data preprocessing is essential because it improves the performance of the model and optimizes the model. For pre-processing purposes, we used a total of three lists. The dataset is located in the data folder in the Git hub.
+ 1) Word replacement list
-
File name: replace_list_hip.xlsx
- Because LDA topic modeling provides results around frequent vocabulary, unifying words with the same meaning into one word is an effective way to perform semantic analysis in text. For example, '러닝' and '런닝' are both words like '달리기'. One can judge that the words all have the same meaning, but the computer recognizes them all as different words. This can result in the occurrence of a keyword being missed because the number of appearances is less as each word is used as a different word, even though the word of a particular meaning is a frequent vocabulary. Therefore, in text mining techniques where the frequency of word appearance is important, such as LDA topic modeling, preceding such word replacement tasks is one of the ways to increase the effectiveness of data analysis.
-
- Stopword list
-
File name: stopword_list_hip.xlsx
- A stopword is a vocabulary that is frequently used in text mining, but it is a word such as a predicate or postposition that is far from people's reactions or opinions. For example, there are words such as '~입니다', '~이다', '~와', and '에서'. These words are common in several recalls, but they are considered unnecessary information in this project of the topic modeling. Therefore, it is necessary to organize these disused terms well in the preprocessing stage.
-
- One char list
-
File name: one_char_list_hip.xlsx
- Earlier, it was said that stopwords are a set of unnecessary words in semantic analysis through text mining. After a tokenization operation, a single-letter token is generally treated as an stopwords term. Therefore, we often analyze meaning by using only tokens that have been removed from two or more characters or words. This is the same in English other than Korean. Because it's hard to have a big meaning with just one letter of the alphabet. However, in Korean, it is a single character, but it is sometimes a keyword depending on the domain you analyze. For example, keywords that are importantly related to story development such as '물', '알', and '화' appear. Therefore, in the preprocessing stage, these single-letter but keyword words are exceptionally not removed from the preprocessing stage.
We coded, and to extract a total of 10 topics in the topic model. The number 10 is appropriate number according to the configuration requirements of the story. The model extracted a total of 10 topics, two of which were excluded because they were very fine. A total of eight significant topics were extracted, which was exactly the same number as the scene segments we originally expected.
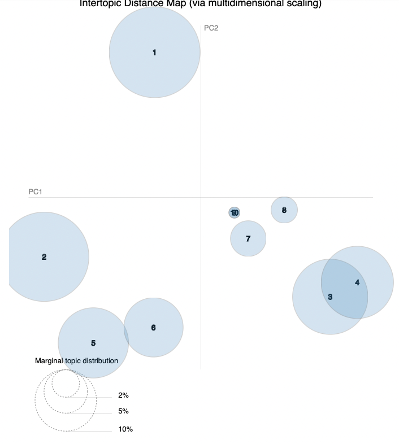
We mapped each topic to a scene segment and named each topic. After that, the subjects' recalls were analyzed. The subjects' recalls were accurately expressed in the order of the story. Accordingly, topic model was able to accurately grasp the order of the story. As shown in the figure, it can be seen that the order of the story is divided by topic for each subject. It can be seen that topic 5 appears a lot in the beginning of the recall, and topic 2 and 8 appear in the second half of the recall.
For more detail.. See this detail