{kind=link}
CaTFormer: Causal Temporal Transformer with Dynamic Contextual Fusion for Driving Intention Prediction
- [2026.01.16] 🚀 Code has been released on GitHub.
- [2026.01.09] The preprint version is available on arXiv.
- [2025.11.08] 🎉 Our paper has been accepted to AAAI 2026!
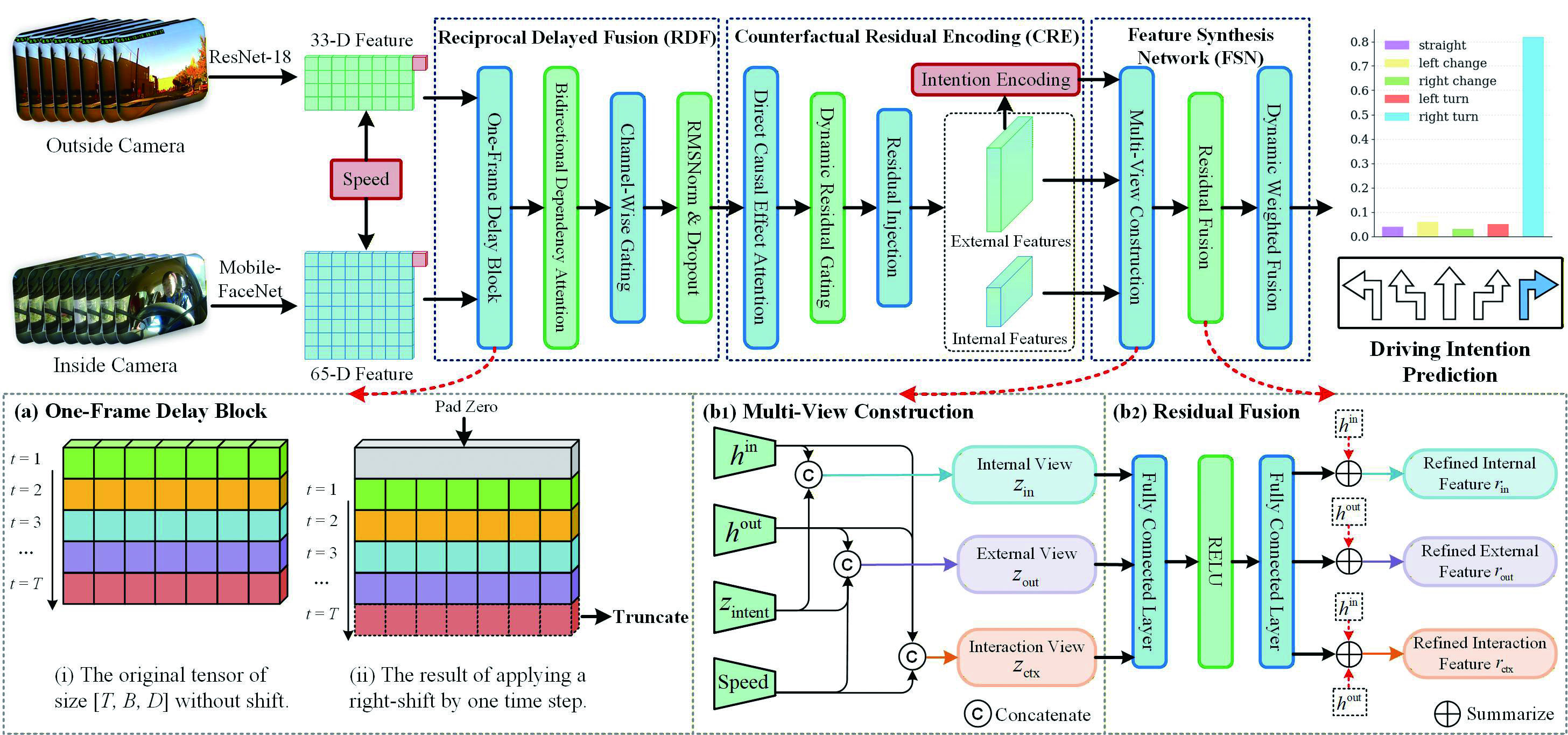
Accurate prediction of driving intention is key to enhancing the safety and interactive efficiency of human-machine co-driving systems. It serves as a cornerstone for achieving high-level autonomous driving. However, current approaches remain inadequate for accurately modeling the complex spatiotemporal interdependencies and the unpredictable variability of human driving behavior. To address these challenges, we propose CaTFormer, a causal Temporal Transformer that explicitly models causal interactions between driver behavior and environmental context for robust intention prediction. Specifically, CaTFormer introduces a novel Reciprocal Delayed Fusion (RDF) mechanism for precise temporal alignment of interior and exterior feature streams, a Counterfactual Residual Encoding (CRE) module that systematically eliminates spurious correlations to reveal authentic causal dependencies, and an innovative Feature Synthesis Network (FSN) that adaptively synthesizes these purified representations into coherent temporal representations. Experimental results demonstrate that CaTFormer attains state-of-the-art performance on the Brain4Cars dataset. It effectively captures complex causal temporal dependencies and enhances both the accuracy and transparency of driving intention prediction.
- Python >= 3.7
- PyTorch >= 1.7
- CUDA (for GPU support)
- Clone the repository:
git clone https://github.com/srwang0506/CaTFormer.git
cd CaTFormer- Setup environment and install dependencies:
# create env
conda create -n catformer python=3.10 -y
conda activate catformer
# install Pytorch and CUDA
pip install torch==2.1.2 torchvision==0.16.2 torchaudio==2.1.2 \
--index-url https://download.pytorch.org/whl/cu121
# other deps
pip install -r requirements.txt-
Download the Brain4Cars dataset and extract all videos into JPG frame sequences (both interior and exterior cameras).
-
Directory layout we expect after preprocessing:
CaTFormer/
├── brain4cars_data/
│ ├── face_camera/
│ │ ├── end_action/
│ │ ├── lchange/
│ │ ├── lturn/
│ │ ├── rchange/
│ │ ├── rturn/
│ └── road_camera/
│ ├── end_action/
│ ├── lchange/
│ ├── lturn/
│ ├── rchange/
│ ├── rturn/
├── datasets/
│ └── annotation/ # fold0.csv, fold1.csv, ...
└── ...
- Clone the official RAFT repo (princeton-vl/RAFT) and install the required dependencies as instructed in its README (incl. pretrained weights), then run
demo_brain4cars.pyto compute exterior optical flow; set the output path (or move results) so the processed flow frames are located atbrain4cars_data/road_camera/flow.
git clone https://github.com/princeton-vl/RAFT.git
# follow RAFT README to set up env + download pretrained weights
python demo_brain4cars.py
# output should be placed under:
# brain4cars_data/road_camera/flowAfter optical flow processing, the dataset directory structure is as follows:
CaTFormer/
├── brain4cars_data/
│ ├── face_camera/
│ │ ├── end_action/
│ │ ├── lchange/
│ │ ├── lturn/
│ │ ├── rchange/
│ │ ├── rturn/
│ └── road_camera/
│ └── flow/
│ ├── end_action/
│ ├── flow/
│ ├── end_action/
│ ├── lchange/
│ ├── lturn/
│ ├── rchange/
│ ├── rturn/
│ ├── lchange/
│ ├── lturn/
│ ├── rchange/
│ ├── rturn/
├── datasets/
│ └── annotation/ # fold0.csv, fold1.csv, ...
└── ...
- Convert interior
face_camera.matmetadata tocar_state.txtbefore training/testing:
python extract_mat.py
# This writes `car_state.txt` beside each video folder for later loading.To train the model on a specific fold (e.g., fold 3), use the provided shell script:
bash train_fold.shTo train on all folds for the 5-fold cross-validation:
bash train_total.shTo evaluate the trained model, use the provided shell script:
bash test.shIf you find this work helpful, please consider citing:
@misc{wang2026catformercausaltemporaltransformer,
title={CaTFormer: Causal Temporal Transformer with Dynamic Contextual Fusion for Driving Intention Prediction},
author={Sirui Wang and Zhou Guan and Bingxi Zhao and Tongjia Gu and Jie Liu},
year={2026},
eprint={2507.13425},
archivePrefix={arXiv},
primaryClass={cs.CV},
url={https://arxiv.org/abs/2507.13425},
}