Architecture
#Concept of Particles
Apache Storm works with tuples every one of which is a data item to be processed. The tuples coming from Storm Spout follow the materialized topology of user by being processed bolt by bolt in their turn (see Figure 1).

Figure 1.Basic Apache Storm user topology
Every SensorStorm bolt contains the OperationManager which is responsible for dealing with the Particles (specific tuples). It contains as well a Batcher, a synchronization buffer, and MetadataParticleHandler (see Fugure 2) which are described further in sections.

Figure 2.Architecture of SensorStorm Bolt
The Particles (that is how we name our primitives) represent a special type of tuple. The features of Particle are:
- Every Particle has a timestamp;
- Every Particle is strongly typed.
The Particles are matched to Apache Storm tuples automatically, therefore, there is no any break of compatibility with the basic Storm functionality.
We distinguish 2(two) different types of Particles: Data Particle and Meta Particle (see Figure 2). They both are processed by Storm cluster, but in a different way.
 Figure 3. Data and Meta Particles
Figure 3. Data and Meta Particles
The inheritance structure of the Particles and the content of every type of them one can see at Figure 3.
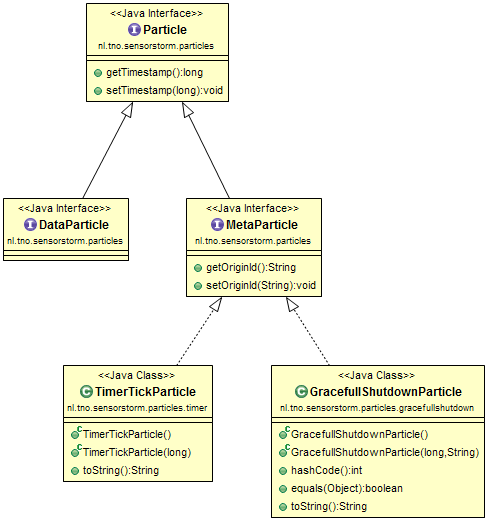
Figure 4. Data and Meta Particles: Class view
##Data Particles Data Particles are the tuples having data. One can see them as typical Apache Storm data streams with the addition of timestamp to every item. They are processed within Storm cluster, following the topology that user started to deal with these data streams. If the functionality of Grouper is used, the Grouper checks whether the incoming Particle is a Data or Meta Particle. If it happens to be Data Particle, the Grouper just groups the Data Particles in the same way as a basic Storm Grouper does and sends it to the next bolt(s) within the topology.
##Meta Particles Metaparticles do not carry measurements, i.e., data items. They are special Particles that are injected into the Apache Storm data stream(s) in order to trigger a specific behavior to that certain stream(s), for example, to adjust time for the replay functionality for the dataset from the past or to slow down the data processing.
###Grouper for Metaparticles Assuming that there could be more than one bolt instance for every type of bolt, the Metaparticles are always broadcast to every bolt instance throughout the whole topology to guarantee that every bolt instance is aware of this exact Metaparticle (see Figure 3).
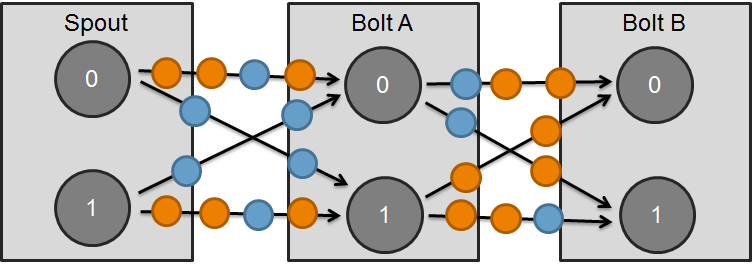 Figure 3. Parallelism of Particles processing: Metaparticles are always broadcast to every type of bolt and to every instance of bolt.
Figure 3. Parallelism of Particles processing: Metaparticles are always broadcast to every type of bolt and to every instance of bolt.
Every spout which has received the Metaparticle, broadcasts it to every known bolt instance. Every bolt that receives the Metaparticle, propagates it by broadcast to all bolt instances at the next step. The process repeats itself until the Metaparticle reaches the end of topology (Fig.3).
More details about the currently available Metaparticles could be found on Metaparticles page.
##Synchronization buffer In a case of receiving many data streams from multiple spouts/bolts at the same time by one bolt instance, some issues may arise that should be dealt with before the streams follow the bolt processing logic. The issues are:
- Data from one spout/bolt could be delivered faster than from other spout/bolt, however, regards, to the receiving bolt processing logic, the merged data stream should be ordered in time. Therefore, the need of ordering regards time synchronization between multiple data streams can arise before the merged stream comes to bolt.
- One bolt instance can receive the multiple copies of the same Metaparticle. It could influence the behavior of the system, especially in case of changing the global state of system (like, shutdown tuple executed two or more times) which would lead to system state inconsistency. To avoid it, every Metaparticle should be delivered Once and only once to every bolt instance.
To deal with these issues the new system component is introduced: synchronization buffer.
It should be put before every bolt (there is only one case when it is not needed: when there is connection one-to-one between two bolts/bolt instances), and it is responsible:
- for applying time ordering for multiple data streams, i.e., provide time synchronization functionality;
- for filtering out the duplicates of the same Metaparticle, so, that only one Metaparticle is arrived to bolt instance.
Synchronization buffer uses the time window for the time synchronization for multiple data streams. The Particles are ordered by timestamp value within the time window. When the first tuple outside of the current time window comes, the first tuple within the buffer is submitted to the bolt. If there are Particles which should be the part of specific time window, but the window is already closed and time moved ahead, the Particle is rejected and it is not processed any more.
When the specific Metaparticle comes, and in synchronization buffer there is already the same Metaparticle, the arriving Metaparticle is rejected and is thrown away for avoiding the processing of Metaparticle duplicates.
If the persistent guaranteed ordering is needed, instead the use of library Storm-Trident is recommended.