{kind=link}
{kind=link}
Predicting Santander Customer Satisfaction using Decision Tree Models
Santander Customer Satisfaction

Introduction and Background
From frontline support teams to C-suites, customer satisfaction is a key measure of success. Unhappy customers don't stick around. What's more, unhappy customers rarely voice their dissatisfaction before leaving.
Santander Bank is asking Kagglers to help them identify dissatisfied customers early in their relationship. Doing so would allow Santander to take proactive steps to improve a customer's happiness before it's too late.
In this project, we work with hundreds of anonymized features to predict if a customer is satisfied or dissatisfied with their banking experience.
You are provided with an anonymized dataset containing a large number of numeric variables. The "TARGET" column is the variable to predict. It equals one for unsatisfied customers and 0 for satisfied customers.
The task is to predict the probability that each customer in the test set is an unsatisfied customer.
We implement a decision tree classifier model from the Scikit-learn library to predict the class. We will initially evaluate the default decision tree model and step by step explore differnent parameters of the decision tree classifier to improve the model.
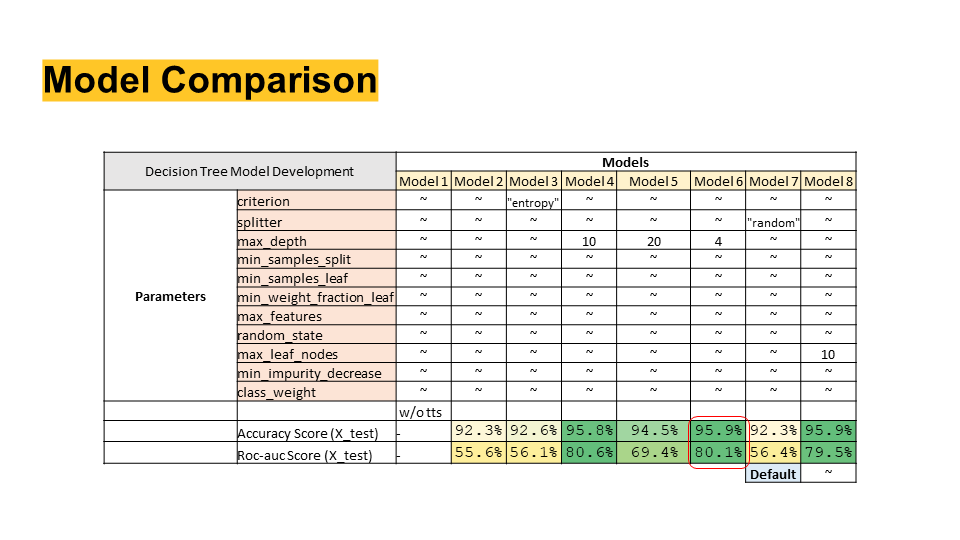
Learnings:
-Building a Classification model using Decision Tree Classfier
-Manually tuning ML Models for better accuracy and ROC score
-Model Evaulation using Accuracy, Precision, Recall and ROC curves
Main Testcode : SantendeCustomerSatisfaction.ipynb
Datasets available in Data folder