Hi! I am Saksham Garg, currently studying in 3rd year and persuing my Bachelor's of technology in Information Technology
To Perform sentiment analysis of tweets using logistic regression and then understanding naïve Bayes classification on training our model. Twitter Sentiment Analysis Project
Sentiment Analysis is the process of ‘computationally’ determining whether a piece of writing is positive, negative or neutral. It’s also known as opinion mining, deriving the opinion or attitude of a speaker.
- Business: In marketing field companies use it to develop their strategies, to understand customers’ feelings towards products or brand, how people respond to their campaigns or product launches and why consumers don’t buy some
products.
- Politics: In political field, it is used to keep track of political view, to detect consistency and inconsistency between statements and actions at the government level. It can be used to predict election results as well!
- Public Actions: Sentiment analysis also is used to monitor and analyse social phenomena, for the spotting of potentially dangerous situations and determining the general mood of the blogosphere.
- Sentiment analysis uses Natural Language Processing (NLP) to make sense of human language, and machine learning to automatically deliver accurate results.
This will build a dictionary where we can lookup how many times a word appears in the lists of positive or negative tweets.
import nltk
from nltk.corpus import twitter_samples
import matplotlib.pyplot as plt
import numpy as np
from nltk.stem import PorterStemmer
from nltk.corpus import stopwords
keys = ['happi', 'merri', 'nice', 'good', 'bad', 'sad', 'mad', 'best', 'pretti', '❤', ':)', ':(', '😒', '😬', '😄', '😍', '♛', 'song', 'idea', 'power', 'play', 'magnific']
We will select a set of words that we would like to visualize.
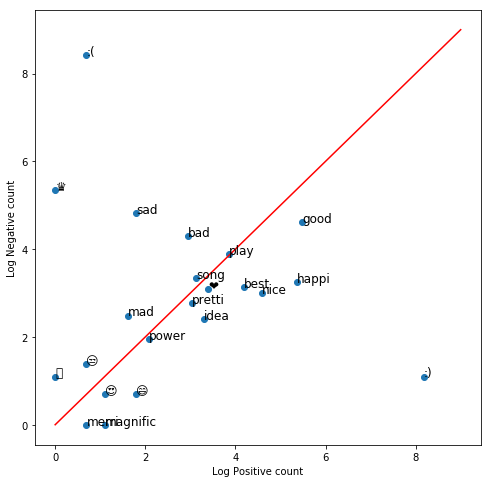
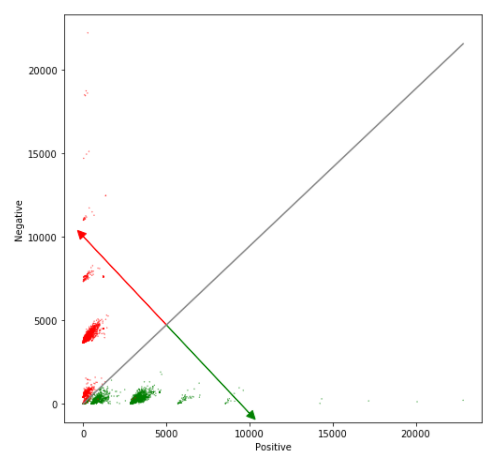
Objectives: Visualize and interpret the logistic regression model
import nltk
from os import getcwd
import pandas as pd
from nltk.corpus import twitter_samples
import matplotlib.pyplot as plt
import numpy as np
step 0) - Collect tweet samples / corpus
step 1) Get or annotate a dataset with positive and negative tweets
Step 2) Preprocess the tweets: process_tweet(tweet)=
Lowercase
Remove punctuation, urls, names
Remove stop words
Stemming
Tokenize sentences
Step 3) Compute freq(w, class)
step 4) Get P(w|pos), P(w|neg)
step 5) Get λ(w) = log (P(w|pos) / P(w|neg))
step 6) Compute logprior - This ratio between positive and negative tweets is called the prior ratio.
These ratios are key for Naive Bayes
Positive words have a ratio larger than 1
Negative words have a ratio lower than 1
Neutral words have a ratio of 1
- Author identification
- Spam filtering
- Information retrieval
- Word disambiguation etc.
I would like to thank Andrew Ng for giving guidance on the course and deeplearning.ai on coursera https://www.coursera.org/account/accomplishments/certificate/X6L7L32PXGPC