
Deteksi objek (object detection) adalah teknologi yang memungkinkan sistem untuk mengenali dan mengidentifikasi objek dalam gambar atau video. Dalam machine learning, deteksi objek dapat dicapai dengan menggunakan algoritma deep learning yang dapat mempelajari fitur-fitur objek dalam gambar dan membedakannya dari objek lainnya.
Pada dasarnya, deteksi objek melibatkan empat tahap: pendaftaran objek, pelatihan model, deteksi objek, dan klasifikasi objek.
Pada tahap pendaftaran objek, gambar-gambar yang berisi objek-objek yang ingin dideteksi diambil dan dilabeli untuk mengidentifikasi objek tersebut.
Pada tahap pelatihan model, algoritma deep learning akan dipelajari menggunakan data gambar yang telah dilabeli. Algoritma akan belajar untuk mengidentifikasi objek-objek tertentu dalam gambar dan membedakannya dari objek-objek lainnya.
Pada tahap deteksi objek, gambar yang diambil akan diproses oleh algoritma deep learning untuk mendeteksi objek yang telah dilatih dalam model.
Pada tahap klasifikasi objek, objek-objek yang terdeteksi kemudian diklasifikasikan ke dalam kategori-kategori yang telah ditentukan sebelumnya, seperti mobil, manusia, atau hewan.
Deteksi objek digunakan dalam berbagai aplikasi, seperti pengawasan lalu lintas, deteksi benda asing pada industri makanan dan minuman, serta pengenalan citra pada robotika dan kendaraan otonom. Namun, teknologi ini juga memiliki tantangan, seperti masalah akurasi deteksi dan kecepatan pemrosesan yang harus ditingkatkan secara terus-menerus.
Ada beberapa metode yang umum digunakan dalam object detection, antara lain yaitu:
- Region-based Convolutional Neural Networks (R-CNN): R-CNN adalah pendekatan yang populer dalam object detection. Pendekatan ini membagi gambar menjadi beberapa wilayah dan setiap wilayah dianalisis menggunakan algoritma deep learning yang terpisah untuk mengenali objek. Metode ini kemudian menggabungkan hasil dari semua wilayah untuk menghasilkan lokasi dan label objek.

- Single Shot Detector (SSD): SSD adalah metode yang memungkinkan objek untuk dideteksi dalam satu jangkauan dengan model jaringan tunggal. Pendekatan ini menggabungkan tiga jaringan convolutional network dengan resolusi yang berbeda untuk mendeteksi objek pada berbagai skala.

- You Only Look Once (YOLO): YOLO adalah metode object detection real-time yang membagi gambar menjadi beberapa grid cell dan memprediksi lokasi dan label objek untuk setiap grid cell. Pendekatan ini menggabungkan deteksi objek dan klasifikasi dalam satu jaringan neural, sehingga sangat efisien dan cepat.

- Faster R-CNN: Faster R-CNN adalah pengembangan dari R-CNN yang menggunakan jaringan neural untuk mempercepat proses proposal wilayah. Pendekatan ini menghasilkan kemampuan deteksi yang lebih cepat dan lebih akurat.

- RetinaNet: RetinaNet adalah metode yang menggunakan struktur jaringan neural yang mirip dengan SSD. Namun, pendekatan ini menggunakan struktur khusus yang memungkinkan model untuk mengidentifikasi objek pada skala yang berbeda dengan lebih akurat.

Semua metode di atas dapat diimplementasikan dengan menggunakan berbagai framework machine learning seperti TensorFlow, PyTorch, atau Caffe. Metode object detection yang dipilih tergantung pada aplikasi dan data yang digunakan.
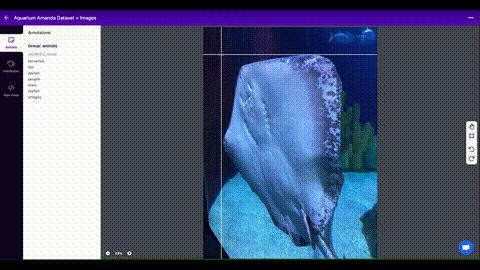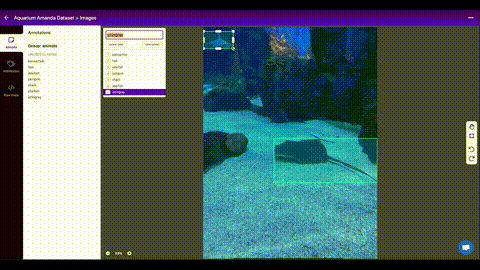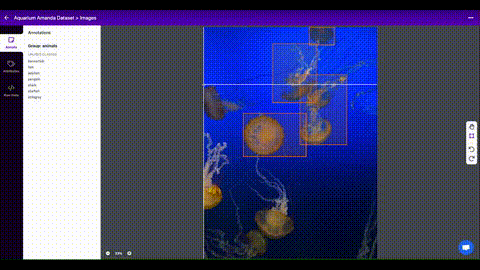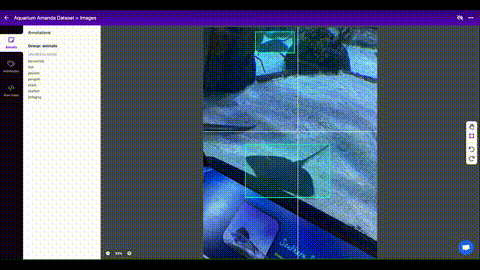
Data preparation adalah tahap penting dalam machine learning dan deep learning, di mana data disiapkan dan diproses sebelum dimasukkan ke dalam model. Tujuan dari data preparation adalah untuk menghasilkan dataset yang berkualitas tinggi dan representatif yang dapat meningkatkan performa dan akurasi model.
Beberapa tahap dalam data preparation meliputi:
-
Pengumpulan data: Data dapat diperoleh dari berbagai sumber, seperti internet, basis data, atau sensor.
-
Preprocessing data: Data perlu dipreprocessing terlebih dahulu sebelum dimasukkan ke dalam model. Proses preprocessing dapat meliputi penghapusan data yang tidak relevan, penyeimbangan dataset, normalisasi data, pengisian data yang hilang (imputation), dan transformasi data (misalnya, encoding).
-
Pemisahan dataset: Dataset perlu dipisahkan menjadi dataset pelatihan, dataset validasi, dan dataset pengujian. Dataset pelatihan digunakan untuk melatih model, dataset validasi digunakan untuk mengukur kinerja model saat diuji dengan data yang belum pernah dilihat sebelumnya, dan dataset pengujian digunakan untuk mengevaluasi kinerja akhir model.
-
Augmentasi data: Augmentasi data adalah proses pembuatan data baru dengan memodifikasi data asli. Augmentasi data dapat membantu meningkatkan keanekaragaman dataset dan mengurangi overfitting. Contoh augmentasi data termasuk flipping, zooming, cropping, dan rotasi.
-
Pengkodean label: Data yang digunakan untuk pemodelan deep learning perlu memiliki label yang sesuai untuk memastikan model dapat membedakan antara kelas yang berbeda. Contoh pengkodean label termasuk one-hot encoding dan label encoding.
Data preparation membutuhkan waktu dan sumber daya yang cukup untuk diproses dengan benar, tetapi sangat penting untuk memastikan kualitas dan performa model yang baik.
YOLO (You Only Look Once) adalah salah satu arsitektur deteksi objek real-time yang paling populer digunakan, dan pada pelatihan ini juga kita menggunakan YOLO versi 8.
YOLOv8 (You Only Look Once version 8) menggunakan pendekatan single-shot detector, yang berarti bahwa objek dapat dideteksi dalam satu tahap, tanpa perlu tahap deteksi lanjutan.

Berikut adalah beberapa fitur utama dari arsitektur YOLOv8:
-
Backbone: YOLOv8 menggunakan model ResNet-152 sebagai backbone-nya, yaitu model CNN yang dirancang untuk memberikan keseimbangan yang baik antara kecepatan dan akurasi untuk memperoses suatu jaringan konvolusi yang telah terlatih untuk mengenali fitur-fitur umum pada gambar.
-
Deteksi multi-skala: YOLOv8 menggunakan teknik deteksi multi-skala untuk meningkatkan akurasi deteksi. Teknik ini melibatkan penggunaan beberapa ukuran input gambar saat melakukan deteksi, sehingga memungkinkan model untuk lebih baik dalam mendeteksi objek dengan ukuran yang berbeda-beda.
-
FPN: YOLOv8 menggunakan Fitur Pyramid Network (FPN) untuk menggabungkan fitur-fitur yang dihasilkan oleh berbagai layer CNN dalam deteksi objek. FPN dapat meningkatkan akurasi deteksi dengan menghasilkan representasi fitur yang lebih kaya dan detail.
-
Augmentasi data: YOLOv8 menggunakan augmentasi data untuk meningkatkan jumlah data pelatihan dan mengurangi overfitting. Teknik augmentasi data ini meliputi rotasi, flipping, dan pergeseran gambar.
-
Training: YOLOv8 menggunakan teknik transfer learning dan pre-training pada ImageNet untuk mengoptimalkan model pada tugas deteksi objek.
-
Optimizer: YOLOv8 menggunakan optimisasi AdamW untuk mempercepat konvergensi dan meningkatkan akurasi model.
Secara keseluruhan, arsitektur YOLOv8 memiliki kinerja yang sangat baik dalam deteksi objek, dan dapat digunakan pada berbagai aplikasi seperti deteksi kendaraan, deteksi orang, dan sebagainya.
Untuk melakukan pengukuran performa pada model YOLOv8, terdapat beberapa metrik yang dapat digunakan, antara lain:
-
Precision: Metrik ini mengukur seberapa akurat model dalam menentukan objek yang benar positif. Precision dapat dihitung dengan rumus:
$$\frac{TP}{TP + FP}$$ , dimana$TP$ (True Positive) adalah jumlah deteksi yang benar positif dan$FP$ (False Positive) adalah jumlah deteksi yang salah positif. -
Recall: Metrik ini mengukur seberapa banyak objek yang berhasil dideteksi oleh model. Recall dapat dihitung dengan rumus:
$$\frac{TP}{TP + FN}$$ dimana$FN$ (False Negative) adalah jumlah deteksi yang salah negatif.

-
F1-score: Metrik ini merupakan perpaduan antara precision dan recall, dan dapat digunakan untuk mengukur keseimbangan antara kedua metrik tersebut. F1-score dapat dihitung dengan rumus:
$$\frac{2 \times Precision \times Recall}{Precision + Recall}$$ -
Mean Average Precision (mAP): Metrik ini digunakan untuk mengukur akurasi model dalam memprediksi lokasi objek secara tepat. mAP dihitung dengan memperhitungkan nilai IOU (Intersection over Union) antara prediksi dan ground truth pada berbagai threshold IOU yang berbeda. Secara matematis mAP dapat dinyatakan sebagai berikut:
dengan
dimana C merupakan jumlah kelas objek dan N merupakan jumlah semua titik interpolasi nilai P terhadap nilai R.
- Inference time: Metrik ini mengukur waktu yang diperlukan oleh model untuk memproses satu gambar dan menghasilkan deteksi. Inference time sangat penting untuk aplikasi real-time yang membutuhkan deteksi objek yang cepat.
Metrik-metrik ini dapat digunakan untuk melakukan evaluasi performa pada model YOLOv5, baik pada saat pelatihan maupun pada saat inferensi. Semakin tinggi nilai precision, recall, dan F1-score, serta mAP, semakin baik kinerja model tersebut. Sedangkan semakin rendah waktu inferensi, semakin cepat model tersebut dalam mendeteksi objek.