{kind=link}
{kind=link}
{kind=link}
{kind=link}
I ran into Collatz's conjecture while working through Al Sweigart's Automate The Boring Stuff. I guess it was meant to demonstrate simple if-else structure but I quickly got curious about the conjecture's properties and started expanding on the initial idea. Because of how little experience I had at the time of programming I had to google quite a bit about file I/O and calculation over large datasets, but I got the code to work to a point where I could calculate the amount of "steps" it would take to get from an integer back to 1, and automate this to a large sequence of integers if need be.
It became obvious that python was struggling when calculating the steps for millions of integers so I ported the code over to the only other language I knew, which was C. The speed difference was quite staggering (for a noob such as myself) even without compiler optimizations:
All computations done with i7 6700k (utilizing only a single core)
Calculations up to 1 000 000 (one million)
Python - about 49 secs (with results being written to an array and only written to a csv file at the end
C - about 0,8 seconds with results being written to the csv file as they go
Calculations up to 100 000 000 (one hundred million)
C - about 115 seconds with results being written to the csv file as they go
C - about 13 seconds with collatz_malloc (including beaten path -algorithm)
C - about 3,3 seconds without writing to disk (w/ everything immediately simultaneously -algorithm)
C - about 4,5 seconds without writing to disk (w/ beaten path -algorithm)
C - about 13 seconds (w/ everything immediately simultaneously -algorithm). No noticeable change in speed
Calculations up to 1000 000 000 (one billion)
C - about 46 seconds without writing to disk (w/ beaten path -algorithm)
C - about 33 seconds without writing to disk (w/ everything immediately simultaneously -algorithm)
I knew next to nothing about algorithms (or dynamic memory allocation!) but talking to a more experienced friend we started bouncing ideas about optimizing the calculation further by not repeating work that's been done before etc and that's where the different "algorithms" came from. What you could call the "final form" is collatzSequence.c. I'll leave the whole folder as it is to remind myself about how NOT to "organize" different files in a project.
After I had a dataset of the first million integers and the number of steps required to reach 1 from each of them I visualized the whole thing as a heat map with R, and the result was quite fascinating to look at.
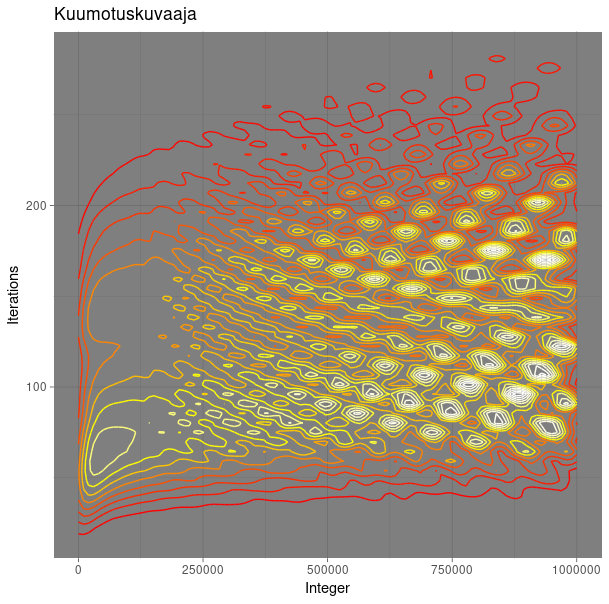
PS. My computer gave out trying to visualize datasets larger than a million data points. The txt file itself with the billion data points was something like 13 gigabytes.