

📌 The framework is currently in alpha and is subject to change.
ProtoLink is a lightweight Python framework that allows you to build autonomous, LLM-powered agents that communicate directly, manage context, and integrate tools seamlessly. Build distributed multi-agent systems with minimal boilerplate and production-oriented architecture.
Each ProtoLink agent is a self-contained runtime that can embed an LLM, manage execution context, expose and consume tools (native or via MCP), and coordinate with other agents over a unified transport layer.
ProtoLink implements and extends Google’s Agent-to-Agent (A2A) specification for agent identity, capability declaration, and discovery, while going beyond A2A by enabling LLM & tool integration.
The framework emphasizes minimal boilerplate, explicit control, and production-readiness, making it suitable for both research and real-world systems.
Focus on your agent logic - ProtoLink handles communication, authentication, LLM integration, and tool management for you.
Follow the API documentation here 📚 documentation.
- A2A Protocol Implementation: Fully compatible with Google's A2A specification
- Extended Capabilities:
- Unified Client/Server Agent Model: Single agent instance handles both client and server responsibilities, reducing complexity.
- Transport Layer Flexibility: Swap between HTTP, WebSocket, gRPC or in-memory transports with minimal code changes.
- Simplified Agent Creation and Registration: Create and register autonomous AI agents with just a few lines of code.
- LLM-Ready Architecture: Native support for integrating LLMs to agents (APIs & local) directly as agent modules, allowing agents to expose LLM calls, reasoning functions, and chain-of-thought utilities with zero friction.
- Tooling: Native support for integrating tools to agents (APIs & local) directly as agent modules. Native Adapter for MCP tooling.
- Runtime Transport Layer: In-process agent communication using a shared memory space. Agents can easily communicate with each other within the same process, making it easier to build and test agent systems.
- Enhanced Security: OAuth 2.0 and API key support.
- Built-in support for streaming and async operations.
- Planned Integrations:
- Advanced Orchestration Patterns
- Multi-step workflows, supervisory agents, role routing, and hierarchical control systems.
- Advanced Orchestration Patterns
ProtoLink implements Google’s A2A protocol at the wire level, while providing a higher-level agent runtime that unifies client, server, transport, tools, and LLMs into a single composable abstraction the Agent.
| Concept | Google A2A | ProtoLink |
|---|---|---|
| Agent | Protocol-level concept | Runtime object |
| Transport | External server concern | Agent-owned |
| Client | Separate | Built-in |
| LLM | Out of scope | First-class |
| Tools | Out of scope | Native + MCP |
| UX | Enterprise infra | Developer-first |
Protolink takes a centralized agent approach compared to Google's A2A protocol, which separates client and server concerns. Here's how it differs:
| Feature | Google's A2A | Protolink |
|---|---|---|
| Architecture | Decoupled client/server | Unified agent with built-in client/server |
| Transport | Factory-based with provider pattern | Direct interface implementation |
| Deployment | Requires managing separate services | Single process by default, scales to distributed |
| Complexity | Higher (needs orchestration) | Lower (simpler to reason about) |
| Flexibility | Runtime configuration via providers | Code-based implementation |
| Use Case | Large-scale, distributed systems | Both simple and complex agent systems |
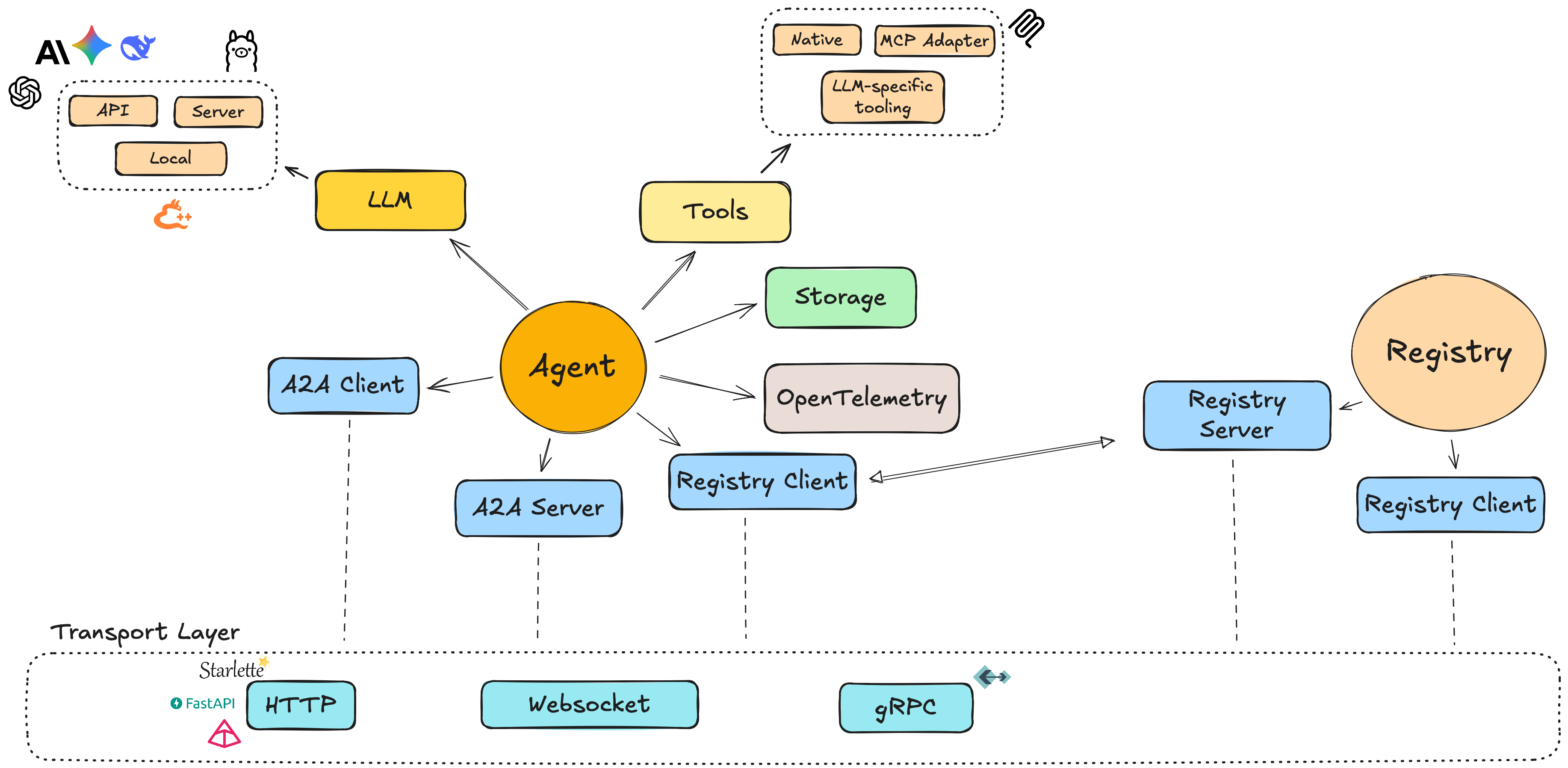
- Simplified Development: Manage a single agent runtime without separate client/server codebases.
- Reduced Boilerplate: Common functionality is handled by the base Agent class, letting you focus on agent logic.
- Flexible Deployment: Start with a single process, scale to distributed when needed
- Unified State Management: Shared context between client and server operations
- Maintainability:
- Direct code paths for easier debugging
- Clear control flow with fewer abstraction layers
- Type-safe interfaces for better IDE support
- Extensibility:
- Easily add new transport implementations
- Simple interface-based design
- No complex configuration needed for common use cases
- Real Multi-Agent Systems: Build autonomous agents with embedded LLMs, tools, and memory that communicate directly.
- Simple API: Built from the ground-up for minimal boilerplate, letting you focus on agent logic rather than infrastructure.
- Developer Friendly: Clean abstractions and direct code paths make debugging and maintenance a breeze.
- Production Oriented: Designed for performance, reliability, and scalability in real-world deployments.
- Extensible & Interoperable: Add new agents, transports, or protocols easily; compatible with A2A and MCP standards.
- Community Focused: Designed for the open-source community with clear contribution guidelines.
This will install the base package without any optional dependencies.
# Using uv (recommended)
uv add protolink
# Using pip
pip install protolinkProtolink supports optional features through extras. Install them using square brackets:
Note: uv add can be replace with pip install if preferred.
# Install with all optional dependencies
uv add "protolink[all]"
# Install with HTTP support (for web-based agents)
uv add "protolink[http]"
# Install all the supported LLM libraries
uv add "protolink[llms]"
# For development (includes all optional dependencies and testing tools)
uv add "protolink[dev]"To install from source and all optional dependencies:
git clone https://github.com/nmaroulis/protolink.git
cd protolink
uv pip install -e ".[dev]"👉 The example found in the jupyter notebooks here: Hello World Example
from protolink.agents import Agent
from protolink.models import AgentCard
from protolink.tools.adapters import MCPToolAdapter
from protolink.llms.api import OpenAILLM
from protolink.discovery import Registry
# Initialize Registry for A2A Discovery
registry = Registry(url="http://127.0.0.1:9000", transport="http")
await registry.start()
# Define the agent card
agent_card = AgentCard(
name="example_agent",
description="A dummy agent",
url="http://127.0.0.1:8020",
)
# OpenAI API LLM
llm = OpenAILLM(model="gpt-5.2")
# Initialize the agent
agent = Agent(agent_card, transport="http", llm=llm, registry=registry)
# Add Native tool
@agent.tool(name="add", description="Add two numbers")
async def add_numbers(a: int, b: int):
return a + b
# Add MCP tool
mcp_tool = MCPToolAdapter(mcp_client, "multiply")
agent.add_tool(mcp_tool)
# Start the agent
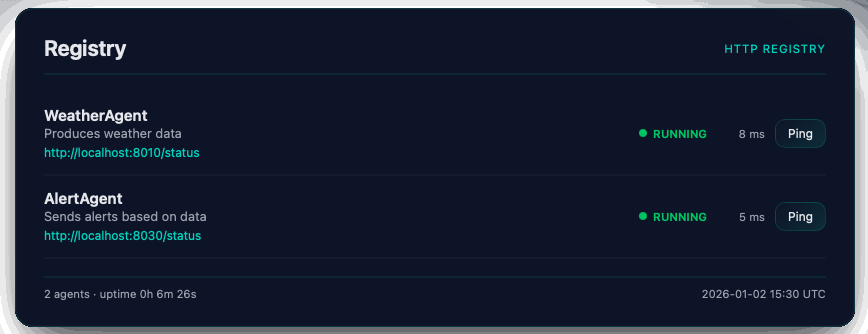
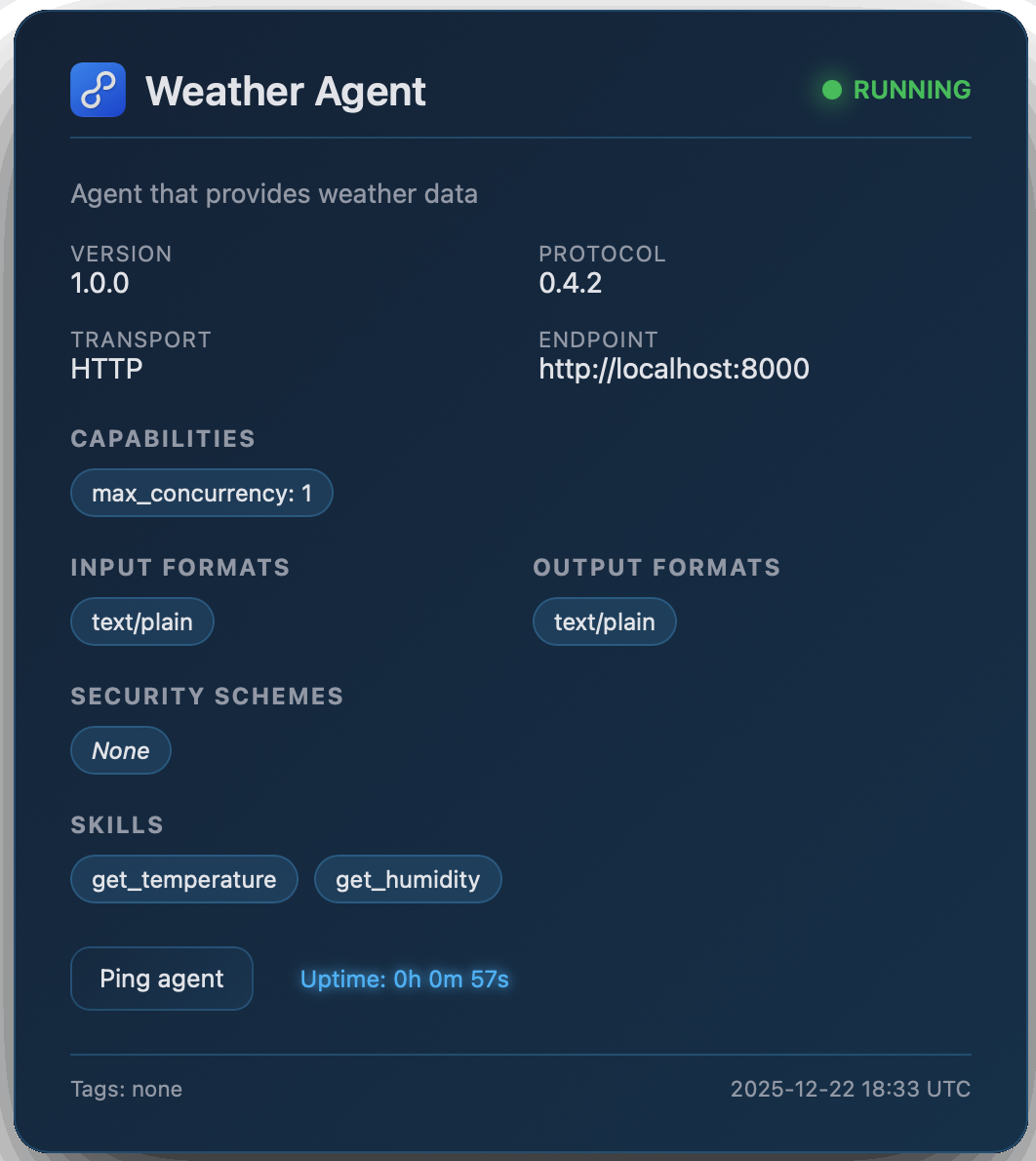
await agent.start()Once the Agent and Registry objects have been initiated, they will automatically expose a web interface at /status where they display the registry and agent's information.
|
|
Follow the API documentation here: Documentation
For Agent-to-Agent & Agent-to-Registry communication:
http· HTTPTransport: Uses HTTP/HTTPS for synchronous requests. Two ASGI implementations are available.- Lightweight:
starlette,httpx&uvicorn - Advanced | Schema Validation:
fastapi,pydantic&uvicorn
- Lightweight:
websocket· WebSocketTransport: Uses WebSocket for streaming requests. [websockets]grpc· GRPCTransport: TBDruntime· RuntimeTransport: Simple in-process, in-memory transport.
Protolink separates LLMs into three types: api, local, and server.
The following are the Protolink wrappers for each type. If you want to use another model, you can use it directly without going through Protolink’s LLM class.
[ API ] [ Server ] [ Local ]
![]()
![]()
![]()
![]()
![]()
![]()
- API, calls the API, requires an API key:
- OpenAILLM: Uses OpenAI API for sync & async requests.
- AnthropicLLM: Uses Anthropic API for sync & async requests.
- GeminiLLM: Uses Gemini API for sync & async requests.
- DeepSeekLLM: Uses DeepSeek API for sync & async requests.
- Local, runs the model in runtime:
- LlamaCPPLLM - TBD: Uses local runtime llama.cpp for sync & async requests.
- Server, connects to an LLM Server, deployed locally or remotely:
- OllamaLLM: Uses Ollama for sync & async requests.
- Native Tool: Uses native tools.
- MCPToolAdapter - TBD: Connects to MCP Server and registers MCP tools as native tools.
Protolink treats agentic systems as distributed programs, not probabilistic workflows.
Every interaction between models, tools, and agents is expressed as an explicit, typed action with deterministic execution semantics. The goal is to replace emergent behavior and prompt-driven control flow with inspectable, replayable, and verifiable computation, while preserving the expressive power of modern LLMs.
Protolink provides a deterministic execution layer for LLMs, tools, and agents, allowing users to focus purely on business logic instead of orchestration glue.
Building agentic systems usually means wrestling with tool-calling prompts, JSON schemas, output parsing, routing between agents, retries, and error handling. This boilerplate is repetitive, fragile, and completely orthogonal to the problem you actually want to solve.
Protolink removes that complexity by standardizing all interactions through a small set of explicit primitives:
- Task — a shared unit of work
- Message — communication within a task
- Part — an atomic, machine-interpretable action or result
Agents never infer behavior implicitly. Instead, they declare intent explicitly using structured Parts such as:
- tool_call — execute a local tool
- agent_call — delegate work to another agent
- infer — invoke LLM reasoning
- text — return user-facing output
and more...
From there, the runtime handles everything deterministically.
You do not need to:
- Prompt the LLM to decide when to call tools
- Parse raw LLM text or JSON
- Write routing or delegation logic
- Implement planners, routers, or state machines
The runtime automatically:
- Builds structured system prompts
- Injects tool schemas and agent capabilities
- Enforces strict output contracts
- Executes declared actions deterministically
Tool calls, agent calls, and LLM invocations only happen when explicitly declared. All results are returned as structured Parts — no hidden side effects, no magic. From the user’s perspective:
task = Task.create(
Message.user("What's the weather in Geneva?")
)That’s it.
This is not a black-box agent framework.
- No hidden reasoning
- No implicit planning
- No speculative execution
Every action is explicit, inspectable, and replayable.
If a tool runs, you see a tool_call.
If an agent is contacted, you see an agent_call.
If an LLM is invoked, you see an infer.
This makes the system predictable, debuggable, composable, and production-ready.
The runtime is fully LLM-agnostic. Any model — API-based, self-hosted, or local can be swapped in without changing behavior or results. OpenAI, Anthropic, local servers, or custom backends all operate through the same unified execution model.
The orchestration stays the same. The contracts stay the same. Only the model changes.
This lets you evolve providers, costs, latency, or deployment strategy without rewriting your agents.
This project uses a structured, Agent-to-Agent (A2A) style communication model. Understanding how Tasks, Messages, Artifacts, and Parts interact is key to using the agent effectively.
A Task represents a unit of work or a conversation thread between agents.
- It contains Messages and Artifacts.
- Tracks metadata such as state (
submitted,working,completed) and execution history. - Tasks are sent between agents; each agent executes what is explicitly defined in the task.
A Message is a communicative unit in a task.
- Can be sent by a user or an agent.
- Contains Parts representing atomic content.
- Example roles:
"user"— input from a human or another agent"agent"— output from an agent
An Artifact is a container for outputs generated by the agent.
- Stores Parts that result from executing a tool (tool_call) or an LLM inference (infer).
- Can include tool results, reasoning traces, or structured outputs.
- Artifacts allow agents to append results without modifying the original message.
A Part is the atomic content of a Message or Artifact.
- Defines what to do or what was produced.
- Example Part types (
PartType):"text": plain text content"json": structured data"tool_call": request to execute a registered tool"tool_result": result from executing a tool"infer": input to invoke the agent's LLM"status","error","image","audio", etc.
-
Task Creation
A user or agent creates aTaskwith aMessagecontaining one or moreParts. -
Task Execution
- The receiving agent inspects the last message or artifact in the task.
- Executes each
Partsequentially:tool_call→ executes a registered tool → producestool_resultPart in an Artifact.infer→ invokes the agent's LLM → produces output Part in an Artifact.
-
Appending Outputs
- Results are appended to the Task as new Artifacts.
- Lifecycle state transitions (
working,completed,failed) are updated in the Task metadata.
-
Sequential Processing
- Tasks are processed sequentially at the message/artifact level.
- Parallel execution is possible within the parts of a single message/artifact, but not across multiple messages/artifacts in the same task.
from protolink.models import Message, Part, Task
# 1️⃣ User creates a Task with a message containing a Part
task = Task.create(Message.user("What's the weather in Athens?"))
# 2️⃣ Add a tool call Part
tool_part = Part.tool_call(tool_name="weather_api", args={"city": "Athens"})
task.add_message(Message.agent(parts=[tool_part]))
# 3️⃣ Agent executes the task
result_task = await agent.execute_task(task)
# 4️⃣ Outputs are appended as artifacts
for artifact in result_task.artifacts:
for part in artifact.parts:
if part.type == "tool_result":
print("Tool result:", part.content)
# 5️⃣ If needed, a infer Part can trigger the agent's LLM
infer_part = Part.infer(prompt="Summarize today's weather in Athens")
task.add_message(Message.agent(parts=[infer_part]))
result_task = await agent.execute_task(task)Key Notes:
- Each
Taskmaintains the full history of messages and artifacts. - Agents execute the last message or artifact to determine the next action.
- Parts inside a message or artifact can be executed in parallel if needed.
- Agents do not guess intent; they execute exactly what is defined in the Parts.
This structured approach ensures predictable, deterministic agent behavior while still supporting multi-step interactions and LLM/tool execution.
MIT
All contributions are more than welcome! Please see CONTRIBUTING.md for more information.