Projeto acadêmico com objetivo de identificar, implementar e mensurar otimizações de performance em bibliotecas Python open source amplamente utilizadas. As contribuições foram submetidas como Pull Requests para os repositórios oficiais de cada projeto.
- Equipe
- Bibliotecas Alvo
- Metodologia
- Gestão do Projeto
- Estrutura do Repositório
- TinyDB
- python-dotenv
- whoosh-reloaded
- Pull Requests
- Resultados Consolidados
- Conclusão
- Referências
| Integrante | GitHub |
|---|---|
| Matheus Virgolino | @matheusvir |
| Lucas Gabriel | @Lucaslg7 |
| Manoel Netto | @ManoelNetto26 |
| Pedro Almeida | @Predd0o |
| Railton Dantas | @RailtonDantas |
| João Pereira | @jpereira-Dev |
| Biblioteca | Descrição | Fork |
|---|---|---|
| TinyDB | Banco de dados documental leve, armazenado em JSON | matheusvir/tinydb |
| python-dotenv | Carregador de variáveis de ambiente a partir de arquivos .env |
matheusvir/python-dotenv |
| whoosh-reloaded | Motor de busca full-text em Python puro | matheusvir/whoosh-reloaded |
Cada biblioteca foi incluída como submódulo Git e suas alterações foram versionadas em branchs dedicadas, seguindo o fluxo definido em contribution.md.
Todos os benchmarks foram executados dentro de contêineres Docker para garantir isolamento do ambiente de execução e eliminar variações causadas por escalonamento de CPU do sistema operacional, cache do sistema e diferenças de versão de bibliotecas. Os Dockerfiles estão disponíveis em setup/<projeto>/Dockerfile.
O protocolo é o mesmo para todas as otimizações:
- 50 execuções totais por cenário; as 10 primeiras (aquecimento) e as 10 últimas (resfriamento) são descartadas, restando 30 execuções efetivas.
- Controle de Garbage Collector:
gc.collect()antes de cada execução;gc.disable()/gc.enable()ao redor do trecho cronometrado. - Temporizador:
time.perf_counter_ns()para resolução em nanossegundos. - Estatísticas reportadas: média, desvio padrão e mediana das 30 execuções.
Uma melhoria é considerada confirmada quando:
mean_otimizado < mean_baseline − std_baseline
Melhorias observadas que não atingem esse limiar são reportadas como "não confirmadas pelo critério estrito", porém ainda relevantes do ponto de vista prático.
Os scripts de benchmark seguem a nomenclatura baseline_<projeto>_<feature>.py e experiment_<projeto>_<feature>.py. Os resultados são gravados em results/<projeto>/result_<projeto>_<feature>.json com o seguinte esquema:
{
"experiment": "...",
"project": "...",
"baseline": { "mean_ms": ..., "std_ms": ..., "runs": 30 },
"optimized": { "mean_ms": ..., "std_ms": ..., "runs": 30 },
"improvement_pct": ...,
"improvement_confirmed": true
}Cada otimização passa pela suíte de testes existente do projeto. Quando a cobertura existente não era suficiente, novos arquivos de teste foram adicionados. O framework utilizado é pytest, com classes de testes agrupadas por funcionalidade.
O projeto utiliza Git para versionamento e GitHub como plataforma de hospedagem. Cada otimização foi desenvolvida em um branch dedicado e integrada ao branch principal do fork via Pull Request, permitindo rastrear o histórico de alterações de forma isolada. Os commits seguem o padrão Conventional Commits (feat, fix, perf, test, docs). Os três projetos-alvo foram incluídos como submódulos Git, mantendo o repositório de pesquisa desacoplado dos forks. Todo o fluxo de trabalho coletivo — desde a nomenclatura de branches até a formatação do código e revisão de PRs — foi rigidamente guiado pelo arquivo contribution.md, garantindo consistência no desenvolvimento entre os membros da equipe.
As tarefas foram gerenciadas por meio do GitHub Projects em EDA OSS Performance, complementado por issues criadas neste repositório principal para rastreamento individual das atividades. Esse fluxo permitiu distribuir responsabilidades entre os integrantes e acompanhar o progresso de cada otimização de forma transparente.
.
├── experiments/ Scripts de benchmark e runners Docker
│ ├── tinydb/
│ ├── python-dotenv/
│ └── whoosh-reloaded/
├── results/ Resultados JSON dos benchmarks
│ ├── tinydb/
│ ├── python-dotenv/
│ └── whoosh-reloaded/
├── setup/ Dockerfiles por projeto
│ ├── tinydb/
│ ├── python-dotenv/
│ └── whoosh-reloaded/
├── analysis/
│ └── plots/ Gráficos comparativos (PNG)
├── tinydb/ Submódulo — fork: matheusvir/tinydb
├── python-dotenv/ Submódulo — fork: matheusvir/python-dotenv
├── whoosh-reloaded/ Submódulo — fork: matheusvir/whoosh-reloaded
└── contribution.md Guia de contribuição do projeto
TinyDB é um banco de dados orientado a documentos, leve e que armazena dados em JSON. Seu modelo simples o torna popular para projetos que não precisam de um servidor de banco de dados completo. Porém, seu design original realiza leitura e varredura linear do arquivo JSON inteiro a cada operação, o que escala mal com o volume de dados. Duas otimizações foram implementadas visando resolver esses problemas.
Por padrão, operações como get(doc_id=N) e contains(doc_id=N) leem o arquivo JSON completo para confirmar que um ID não existe — uma leitura de I/O de complexidade O(n) em relação ao número de documentos. Um Filtro de Bloom resolve o problema em tempo constante para o caso negativo: se o filtro confirma a ausência do ID, o acesso ao armazenamento é descartado imediatamente.
- Novo módulo
tinydb/bloom_filter.py: classeBloomFiltercom duplo hashing (MD5 + SHA-256), taxa de falso positivo configurável (padrão: 1%) e inicialização lazy. Table.__init__()instancia o filtro;get()econtains()consultam o filtro antes de acessar o storage.insert()einsert_multiple()adicionam IDs ao filtro;remove()reconstrói o filtro;truncate()limpa o filtro.
| Operação | Sem otimização | Com Bloom Filter (miss) |
|---|---|---|
get(doc_id=N) / contains(doc_id=N) |
O(n) leitura de storage | O(k) computações de hash |
Onde n é o número de documentos e k é o número de funções de hash (tipicamente 6–10). A garantia de zero falsos negativos é preservada: o filtro nunca oculta um documento existente. Falsos positivos (no máximo 1% por padrão) simplesmente recaem no caminho normal de verificação.
| Escala | Baseline (ms) | Otimizado (ms) | Melhoria |
|---|---|---|---|
| 1k docs | 54,72 ± 1,87 | 1,81 ± 0,16 | 96,69% ✓ |
| 10k docs | 787,03 ± 18,90 | 0,62 ± 0,08 | 99,92% ✓ |
| 50k docs | 12.559,88 ± 1.349,95 | 1,29 ± 0,43 | 99,99% ✓ |
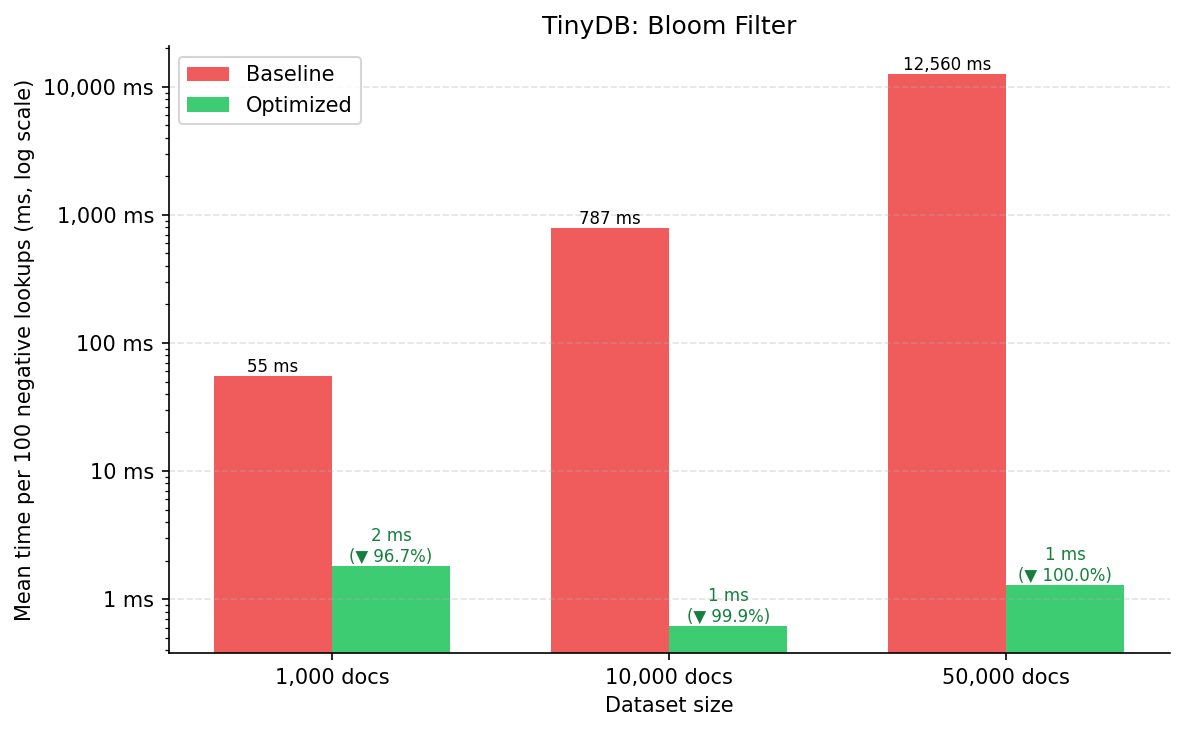
O ganho escala de forma notável com o tamanho do dataset, que é o comportamento esperado para um Filtro de Bloom. Em 50k documentos, o baseline leva ~12,5 segundos por lote de 100 consultas; o caminho otimizado leva ~1,3 ms — uma redução de aproximadamente 9.700×.
Dois novos arquivos de teste foram adicionados:
tests/test_bloom_filter.py— 7 classes, 27 testes cobrindo oBloomFilterisoladamente: inicialização,add()/test(), garantia de zero falsos negativos, determinismo de hash,rebuild()e serialização.tests/test_bloom_integration.py— 9 classes, 27 testes de integração comTinyDB.Table, parametrizados sobreMemoryStorageeJSONStorage. Todos os 260 testes passam sem regressões.
O método search() do TinyDB realiza uma varredura linear O(n) sobre todos os documentos em memória para localizar correspondências por valor de campo. Um índice B-Tree reduz essa complexidade para O(log n) na busca por chave, com um custo de manutenção proporcional ao número de resultados na recuperação.
- Novo módulo
tinydb/index.py: classeBTreeIndexcom B-Tree em memória, criado sob demanda viacreate_index(field_name). Table.search()utiliza o índice quando disponível;insert(),update()eremove()mantêm a consistência do índice.- O comportamento padrão (sem índice) permanece inalterado.
| Operação | Sem índice | Com B-Tree |
|---|---|---|
search() por campo |
O(n) varredura linear | O(log n) busca + O(k) recuperação |
Onde n é o número de documentos e k o número de resultados. O overhead de manutenção do índice é um trade-off esperado e aceitável para cargas de trabalho intensas em leitura.
| Escala | Baseline (ms) | Otimizado (ms) | Melhoria |
|---|---|---|---|
| 1k docs | 126,36 ± 24,99 | 38,41 ± 1,62 | 69,60% ✓ |
| 10k docs | 1.453,87 ± 181,34 | 437,95 ± 8,24 | 69,88% ✓ |
| 50k docs | 5.746,27 ± 331,01 | 2.077,95 ± 120,19 | 63,84% ✓ |
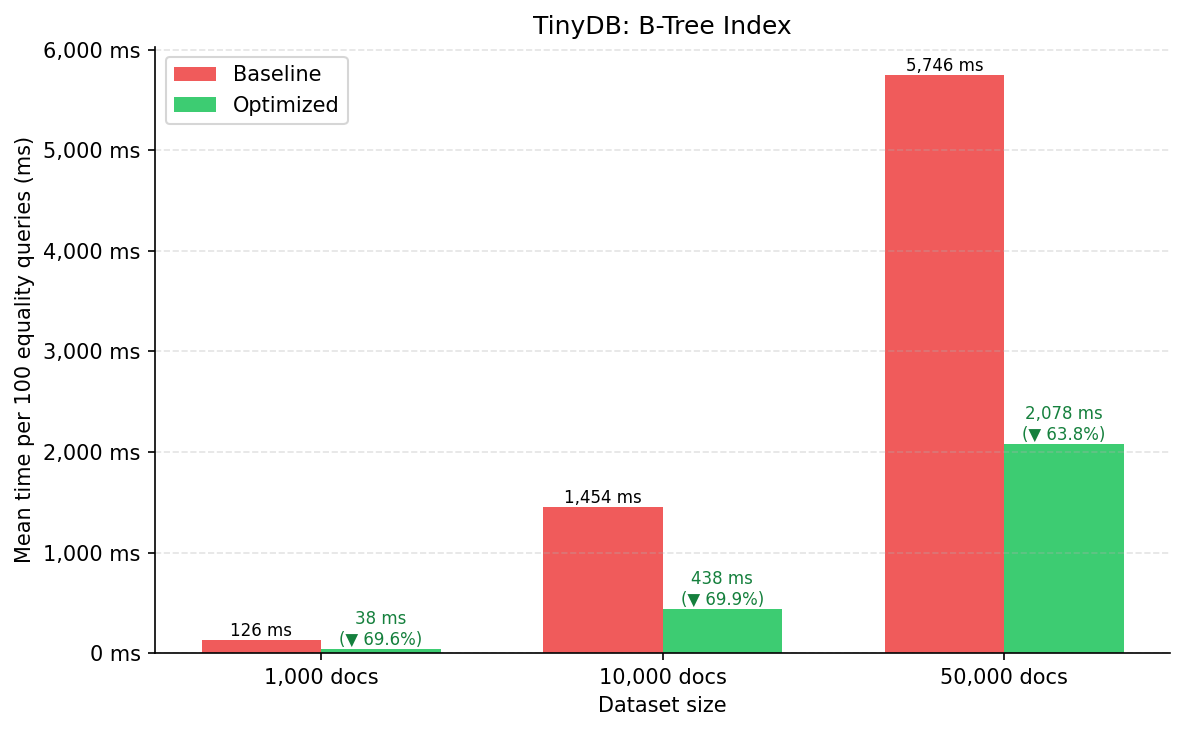
O ganho é consistente entre 64% e 70% em todas as escalas. Enquanto o custo do baseline cresce quase linearmente com o número de documentos, o caminho indexado escala significativamente melhor. A redução acentuada do desvio padrão nas execuções otimizadas indica latência mais previsível.
Nenhum arquivo de teste novo foi necessário. A suíte existente — tests/test_operations.py e tests/test_tables.py — cobre todas as operações afetadas (204 passando, 1 ignorado).
python-dotenv é a biblioteca padrão para carregar variáveis de ambiente a partir de arquivos .env. Dois gargalos distintos foram identificados e corrigidos.
A função resolve_variables() em src/dotenv/main.py reconstruía o ambiente resolvido realizando merges físicos de dicionários a cada passo de interpolação — operação O(N) em memória por iteração, onde N é o número de variáveis. Em arquivos .env grandes, esse overhead de cópia acumula.
A solução substitui a estratégia de merge por um collections.ChainMap, que compõe a mesma visão lógica sem copiar os dados: as consultas percorrem a cadeia em tempo de leitura, eliminando o passo de merge inteiramente.
| Variante | Complexidade da resolução por iteração |
|---|---|
| Merge de dicionários | O(N) cópia por passo |
| ChainMap | O(1) composição + O(1) lookup amortizado |
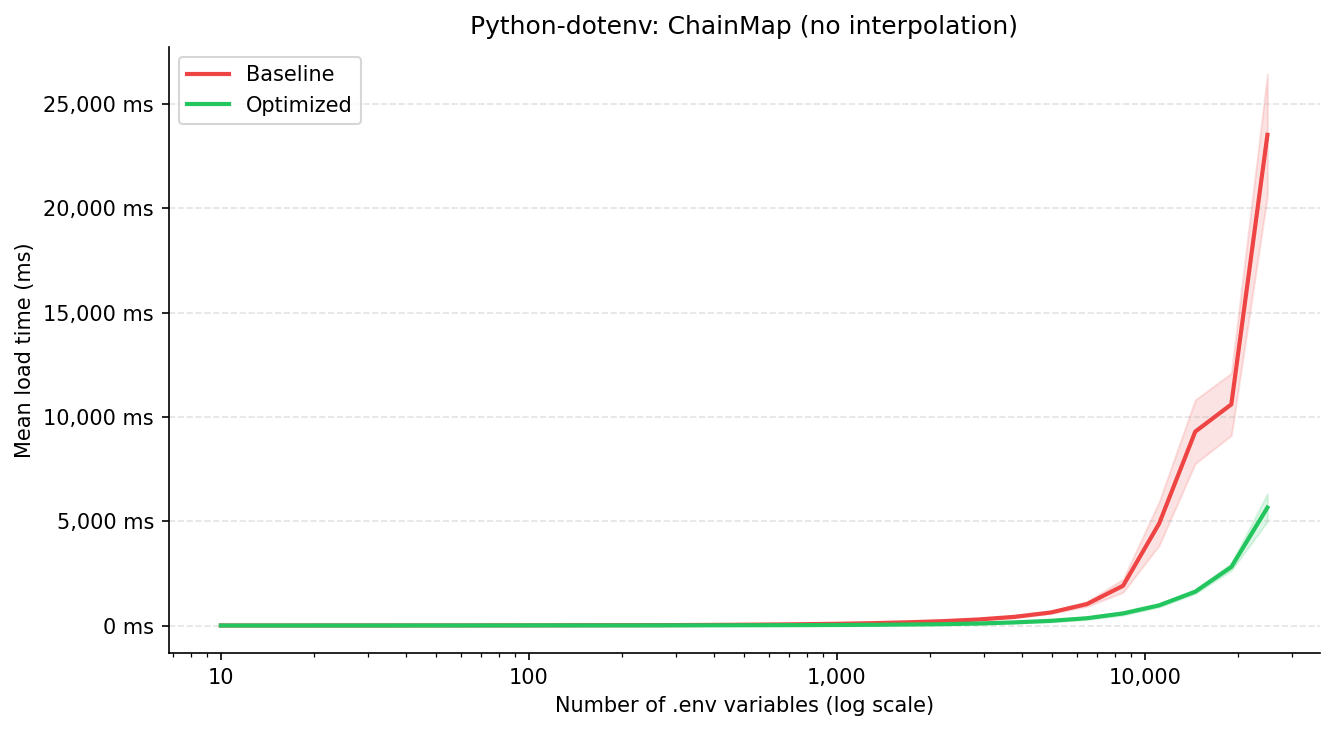
| Variáveis | Baseline (ms) | Otimizado (ms) | Melhoria |
|---|---|---|---|
| 10 | 0,97 ± 0,31 | 0,87 ± 0,15 | 10,27% |
| 982 | 80,71 ± 5,06 | 25,37 ± 1,56 | 68,57% |
| 8.497 | 1.906,04 ± 312,44 | 579,83 ± 86,53 | 69,58% |
| 25.000 | 23.514,52 ± 2.911,14 | 5.651,43 ± 668,88 | 75,97% ✓ |
| Variáveis | Baseline (ms) | Otimizado (ms) | Melhoria |
|---|---|---|---|
| 10 | 0,76 ± 0,08 | 0,57 ± 0,20 | 25,16% |
| 982 | 76,97 ± 8,77 | 45,23 ± 4,76 | 41,23% |
| 8.497 | 1.806,18 ± 240,60 | 759,82 ± 52,20 | 57,93% |
| 25.000 | 23.366,69 ± 3.725,48 | 6.510,14 ± 822,94 | 72,14% ✓ |
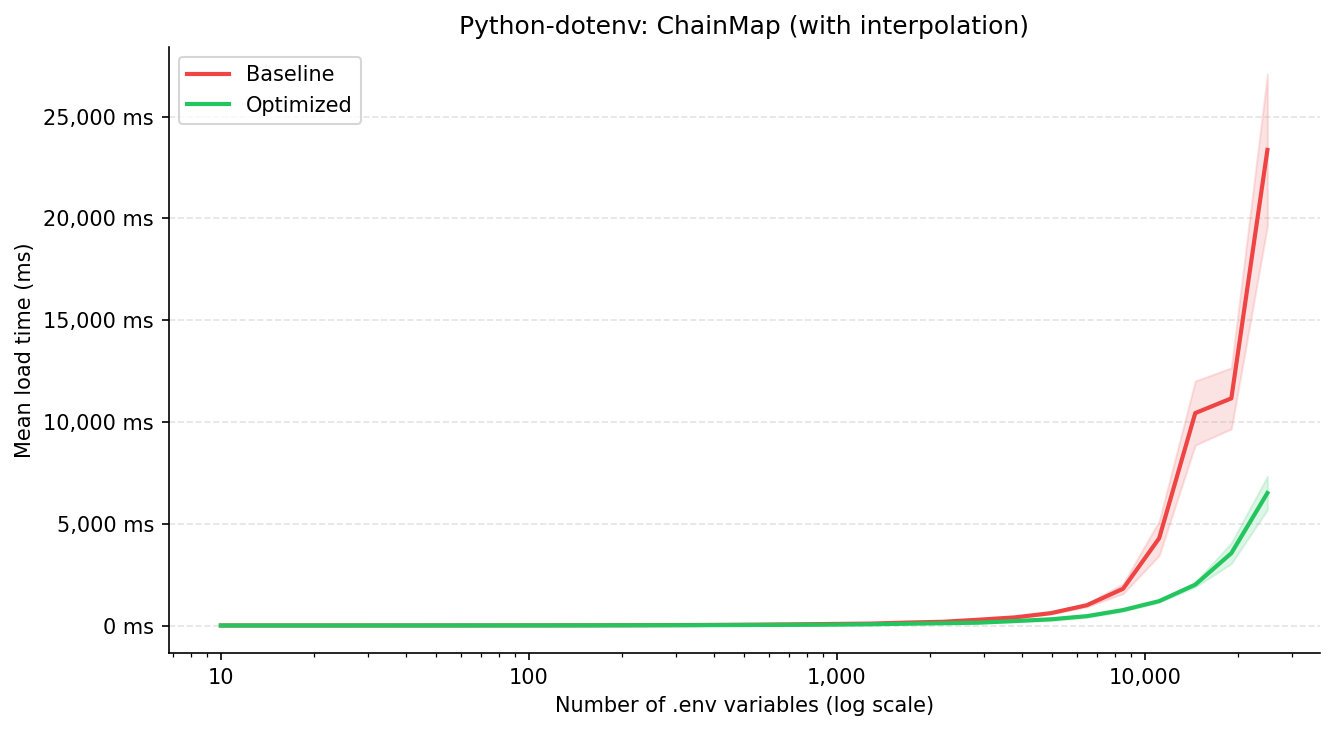
O benefício é desconsiderável abaixo de ~50 variáveis, mas cresce consistentemente a partir daí. Em 25.000 variáveis, a otimização reduz o tempo de carregamento em ~76% sem interpolação e ~72% com interpolação. O fato de ambos os modos apresentarem a mesma tendência confirma que o ganho vem da eliminação do overhead de merge em resolve_variables().
A mudança é coberta pela suíte existente: tests/test_main.py (casos interpolate=True e interpolate=False) e tests/test_variables.py. Todos os testes passam sem regressões.
O método advance() em src/dotenv/parser.py é chamado a cada token durante o parsing. Na implementação original, re.findall(r'\n', text) criava uma lista Python com todos os matches de nova linha apenas para obter seu tamanho — uma alocação de heap desperdiçada por chamada.
Substituição de uma linha: len(re.findall(r'\n', text)) → text.count('\n'). O str.count() realiza a contagem diretamente em C, sem alocar nenhuma estrutura de dados intermediária.
| Variante | Por chamada a advance() |
|---|---|
re.findall |
O(n) scan + alocação de lista |
str.count |
O(n) scan puro (sem alocação) |
A complexidade assintótica não muda, mas a constante oculta é drasticamente menor pela eliminação da pressão sobre o heap.
| Variante | Média (ms) | Desvio Padrão (ms) | Execuções |
|---|---|---|---|
| Baseline | 11.403,40 | 1.227,85 | 39 |
| Otimizado | 8.528,51 | 132,97 | 32 |
| Melhoria | 25,21% ✓ |
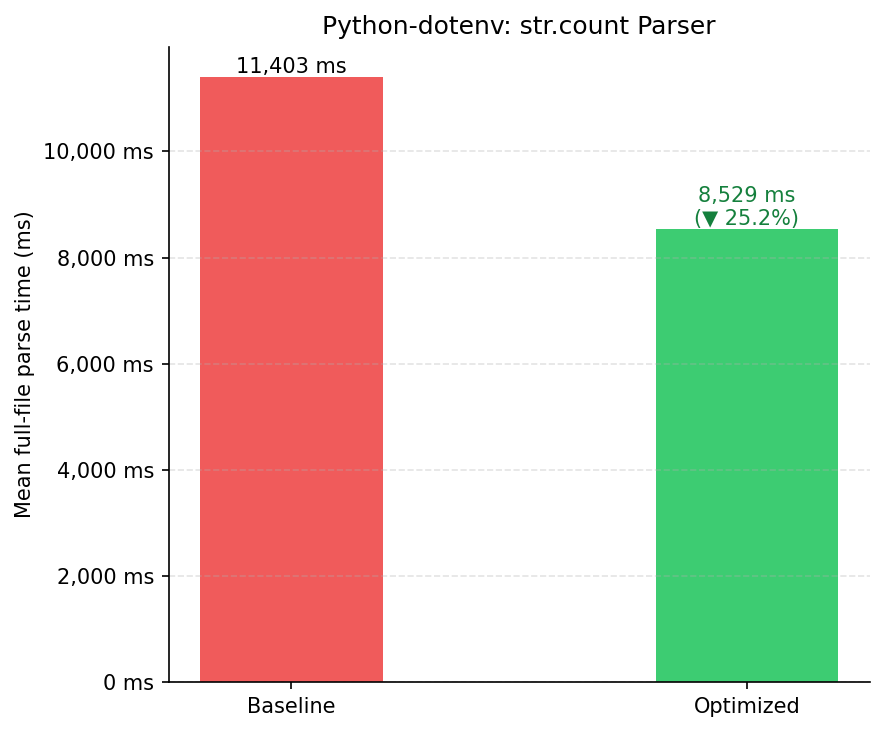
Além da redução de 25% na média, destaca-se a redução de 9× no desvio padrão (de 1.227 ms para 132 ms), evidenciando que a pressão de alocação original era também responsável por pausas de GC irregulares.
advance() é exercitado em toda chamada de parsing; a suíte tests/test_parser.py (~30 casos parametrizados) fornece cobertura completa. Todos os testes passam sem regressões.
whoosh-reloaded é um motor de busca full-text implementado inteiramente em Python. Neste projeto o foco é em mitigar gargalos de CPU e I/O em três frentes do pipeline de busca.
O método skip_to() de ListMatcher realizava uma varredura linear O(n) para avançar na posting list, tornando-se custoso em consultas AND onde skip_to() é invocado repetidamente para encontrar documentos comuns entre os termos.
Novo arquivo src/whoosh/matching/skiplist.py com duas classes:
SkipNode: nó da Skip List com ponteiros de avanço para cada nível; usa__slots__para minimizar uso de memória.SkipList: constrói todos os níveis em um único passo O(n) e implementaskip_to()em O(log n) descendo dos níveis superiores.SkipListMatcher: herda deListMatchere sobrescreve apenasskip_to(). Todos os demais métodos (next,id,weight,score,all_ids) permanecem inalterados, garantindo compatibilidade total.
| Operação | ListMatcher (original) |
SkipListMatcher (otimizado) |
|---|---|---|
skip_to() |
O(n) varredura linear | O(log n) descida por níveis |
| Consulta AND sobre N docs | O(n) | O(k log n), onde k = nº de resultados |
O benefício das Skip Lists se concentra em interseções assimétricas, onde uma posting list é longa e a outra curta — exatamente o cenário explorado no benchmark.
| Variante | Média (ms) | Desvio Padrão (ms) | Execuções |
|---|---|---|---|
| Baseline | 9.057,86 | 887,20 | 30 |
| Otimizado | 8.249,27 | 341,50 | 30 |
| Melhoria | 8,93% |
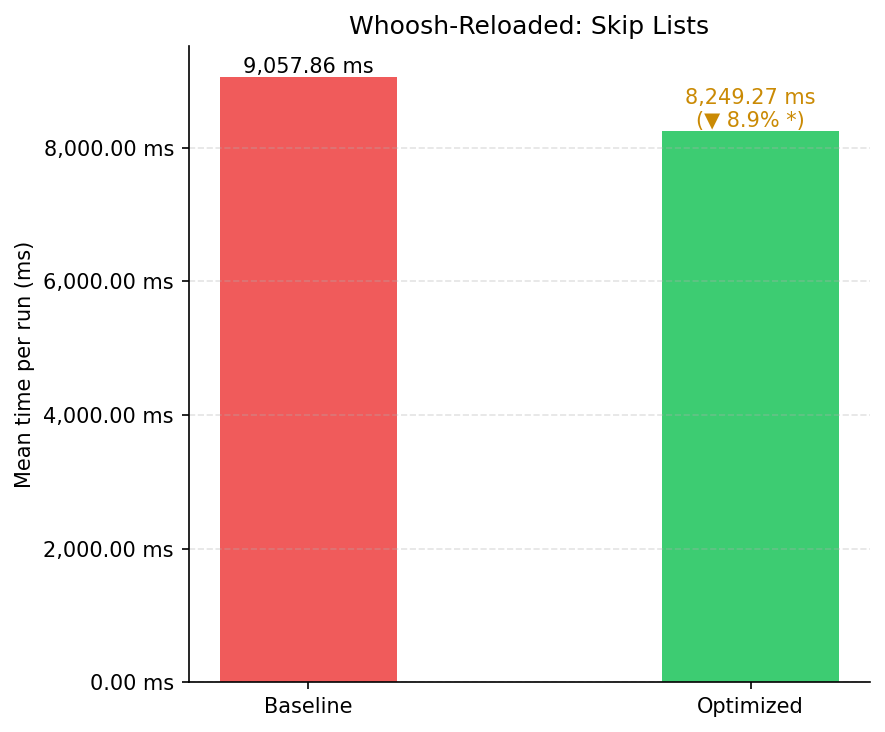
A melhoria de 8,93% não atinge o limiar de confirmação estatística estrita (a diferença entre as médias, 808 ms, é menor que o desvio padrão do baseline, 887 ms). Ainda assim, o efeito é real e consistente: o desvio padrão cai de 887 ms para 341 ms — aproximadamente um terço — indicando que as Skip Lists eliminam os piores casos de varredura linear que causavam alta variância no baseline. Em cargas com assimetria de frequência mais extrema, o ganho tende a ser maior.
SkipListMatcher é exercitado pela suíte existente de tests/test_searching.py e tests/test_matching.py, que cobrem consultas booleanas AND e o comportamento do IntersectionMatcher. Todos os testes passam sem regressões.
Ao buscar um termo inexistente no índice, o Whoosh realizava leituras custosas em disco na hash table de termos do codec W3 antes de confirmar a ausência. Com um Filtro de Bloom compacto em memória, ausências definitivas são descartadas sem qualquer acesso a disco.
src/whoosh/support/bloom.py: classeBloomFilterstandalone com duplo hashing (MD5 + SHA-256), taxa de falso positivo configurável, serializaçãoto_bytes()/from_bytes()e suporte a merge de filtros.src/whoosh/codec/whoosh3.py: integração no codec W3:W3FieldWritercoleta todas as chaves de termos durante a indexação e grava um arquivo.blmao fechar o segmento.W3TermsReadercarrega o filtro na inicialização e curto-circuita__contains__,term_info,frequencyedoc_frequencypara termos ausentes.W3Codecexpõe os parâmetrosbloom_enabledebloom_false_positive_rate(habilitado por padrão, 1% FPR).
| Operação | Sem Bloom | Com Bloom (miss) |
|---|---|---|
| Lookup de termo negativo | O(disk I/O) leitura em disco | O(k) computações de hash |
A garantia de zero falsos negativos é preservada; falsos positivos (≤1%) retornam ao caminho normal.
| Variante | Média (ms) | Desvio Padrão (ms) | Execuções |
|---|---|---|---|
| Baseline | 28,36 | 7,49 | 30 |
| Otimizado | 24,98 | 5,15 | 30 |
| Melhoria | 11,93% |
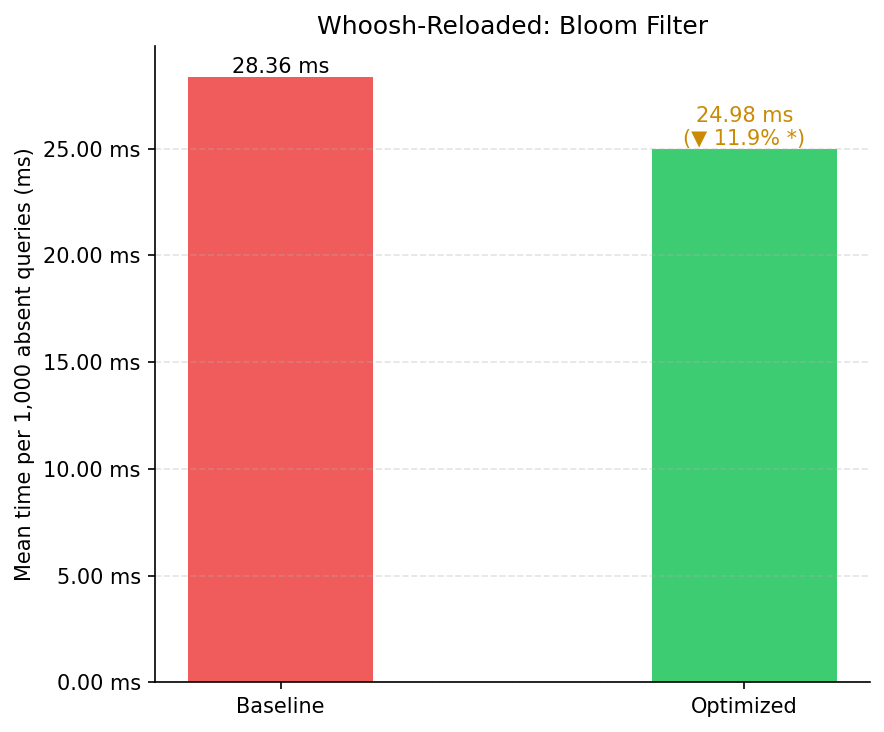
O ganho médio é de 11,93%, não confirmado pelo critério estrito (a diferença de 3,38 ms é menor que o desvio padrão do baseline de 7,49 ms). O ganho mais modesto em relação ao TinyDB reflete que o Whoosh já possui cache interno de termos, que absorve parte do custo de lookups negativos no baseline. Mesmo assim, a mediana otimizada (23,60 ms) é consistentemente inferior ao baseline (28,36 ms), e o desvio padrão reduz de 7,49 ms para 5,15 ms.
Novo arquivo tests/test_bloom.py com 8 classes e 35 testes, cobrindo: BloomFilter standalone, serialização, merge, parâmetros ótimos, integração com o codec e cenários end-to-end com múltiplos segmentos e otimização. Todos os testes existentes passam sem regressões.
Consultas wildcard sem prefixo literal (ex.: *tion, *fix*) forçavam uma varredura O(n) de todo o vocabulário do campo via lexicon(). Um índice invertido de trigramas sobre o vocabulário permite que Wildcard._btexts() intersecte conjuntos de candidatos, reduzindo o custo para O(1) lookup + O(k) filtragem.
Dois novos métodos em reading.py (IndexReader):
_get_ngram_index(fieldname, size)— constrói e cacheia lazily o mapeamento trigrama → termos.terms_by_ngrams(fieldname, text_ngrams, size)— intersecta os conjuntos de candidatos a partir do índice.
Dois novos métodos em query/terms.py (Wildcard):
_extract_literals(text, special_chars)— extrai segmentos literais de um padrão glob._btexts(ixreader)— sobrescrevePatternQuery._btextscom filtragem baseada em N-gramas.
Wildcards com prefixo literal (ex.: comp*) continuam utilizando expand_prefix sem alteração.
| Operação | Sem índice | Com índice de trigramas |
|---|---|---|
| Wildcard sem prefixo | O(n) varredura do léxico | O(1) lookup + O(k) filtragem |
O índice é construído lazily na primeira consulta e cacheado por campo, amortizando o custo de construção nas consultas subsequentes.
| Variante | Média (ms) | Desvio Padrão (ms) | Execuções |
|---|---|---|---|
| Baseline | 15.171,02 | 106,46 | 30 |
| Otimizado | 14.480,16 | 120,33 | 30 |
| Melhoria | 4,55% ✓ |
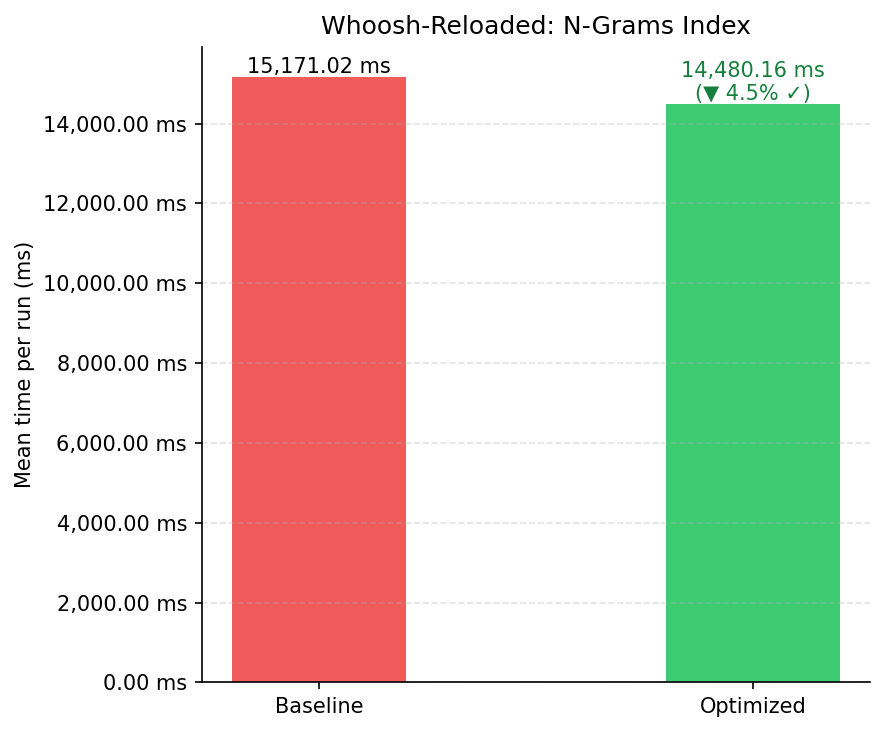
A melhoria de 4,55% é confirmada estatisticamente. O ganho moderado reflete que os padrões utilizados (*graf*, *ritmo*) ainda correspondem a uma grande fração do vocabulário (3.000+ termos cada), mantendo o custo de filtragem final alto mesmo após o estreitamento por N-gramas. Em vocabulários onde os padrões correspondem a menos termos, o benefício da redução de candidatos tende a ser maior.
A otimização é coberta pelas suítes existentes tests/test_searching.py e tests/test_queries.py, que incluem casos de wildcard em múltiplos tipos de campo. Todos os testes passam sem regressões.
Todas as otimizações foram submetidas como Pull Requests aos repositórios oficiais das bibliotecas.
Introduz um Filtro de Bloom em memória para otimizar consultas por doc_id em tabelas TinyDB. O filtro é habilitado por padrão, inicializado lazily e não requer nenhuma mudança de API. Operações de ausência que antes exigiam leitura completa do JSON (O(n)) passam a ser resolvidas em O(k) computações de hash, sem acesso ao storage. A melhoria varia de 96,69% (1k docs) a 99,99% (50k docs).
Introduz um índice B-Tree opcional em memória que reduz a complexidade de search() de O(n) para O(log n) em campos indexados. O índice é criado sob demanda via create_index(field_name) e não altera o comportamento padrão da biblioteca. A melhoria é consistente, variando entre 63% e 70% nas escalas testadas.
Substitui os merges físicos de dicionários em resolve_variables() por um ChainMap, eliminando o overhead de O(N) cópia de memória por iteração de interpolação. A melhoria cresce com o número de variáveis e atinge 75,97% (sem interpolação) e 72,14% (com interpolação) em 25.000 variáveis.
Substitui len(re.findall(r'\n', text)) por text.count('\n') no método advance() do parser, eliminando a alocação de uma lista Python por token. A mudança é cirúrgica — uma única linha — e reduz o tempo médio de parsing em 25,21%, com redução de 9× no desvio padrão.
Integra Filtros de Bloom ao codec W3 do Whoosh para curto-circuitar leituras em disco durante lookups negativos de termos. O filtro é gravado como arquivo .blm por segmento durante a indexação e carregado na inicialização do leitor. O design é retrocompatível: segmentos sem .blm utilizam o caminho original. Melhoria média de 11,93%.
Constrói um índice invertido de trigramas sobre o vocabulário do campo, permitindo que consultas wildcard sem prefixo literal (ex.: *tion, *fix*) intersectem conjuntos de candidatos em vez de varrer o léxico completamente. O índice é construído lazily e cacheado por campo. Melhoria de 4,55%, confirmada estatisticamente.
Adiciona SkipListMatcher, que herda de ListMatcher e sobrescreve apenas skip_to() com uma Skip List de O(log n), sem alterar nenhuma outra operação. Consultas AND sobre interseções assimétricas passam de O(n) para O(k log n). A melhoria de 8,93% não é confirmada pelo critério estrito, mas o desvio padrão cai de 887 ms para 341 ms, evidenciando a eliminação dos piores casos.
| # | Biblioteca | Otimização | Melhoria |
|---|---|---|---|
| 1 | TinyDB | Filtro de Bloom — 1k docs | 96,69% |
| 2 | TinyDB | Filtro de Bloom — 10k docs | 99,92% |
| 3 | TinyDB | Filtro de Bloom — 50k docs | 99,99% |
| 4 | TinyDB | B-Tree — 1k docs | 69,60% |
| 5 | TinyDB | B-Tree — 10k docs | 69,88% |
| 6 | TinyDB | B-Tree — 50k docs | 63,84% |
| 7 | python-dotenv | ChainMap — sem interpolação (25k vars) | 75,97% |
| 8 | python-dotenv | ChainMap — com interpolação (25k vars) | 72,14% |
| 9 | python-dotenv | str.count newline |
25,21% |
| 10 | whoosh-reloaded | Skip Lists | 8,93% |
| 11 | whoosh-reloaded | Filtro de Bloom negative lookup | 11,93% |
| 12 | whoosh-reloaded | N-gramas wildcard | 4,55% |
As sete otimizações implementadas demonstram que bibliotecas Python amplamente utilizadas apresentam gargalos de performance identificáveis e corrigíveis com aplicação direta de estruturas de dados.
Os ganhos mais expressivos ocorreram no TinyDB, onde Filtros de Bloom e B-Trees reduziram operações que cresciam linearmente com o volume de dados para complexidade constante e logarítmica, respectivamente — chegando a reduções de até 99,99% no tempo de consultas negativas.
No python-dotenv, substituições cirúrgicas (ChainMap e str.count) eliminaram alocações desnecessárias em hot paths, gerando melhorias de 25% a 76% sem nenhuma mudança de API.
No whoosh-reloaded, os ganhos foram mais modestos,refletindo que o motor já possui otimizações internas, mas observáveis em todas as três frentes: Skip Lists reduziram a variância das consultas AND, o Filtro de Bloom antecipou lookups negativos antes do acesso a disco, e o índice de N-gramas eliminou a varredura linear do léxico em buscas wildcard sem prefixo.
Todas as contribuições foram submetidas como Pull Requests para os repositórios oficiais, acompanhadas de benchmarks reproduzíveis via Docker e de suítes de testes sem regressões.
-
Filtro de Bloom: Wikipedia
-
B-Tree: Wikipedia
-
Skip List: Wikipedia
-
N-gramas: Wikipedia
-
ChainMap: Python Docs
Este repositório é parte do projeto acadêmico da disciplina de Estruturas de Dados e Algoritmos do curso de Ciência da Computação, período 2025.2, da Universidade Federal de Campina Grande (UFCG).