马哥原创:用python开发的小红书图片采集软件,支持下载笔记图片、采集笔记数据、评论数据等。
本软件工具仅限于学术交流使用,严格遵循相关法律法规,符合平台内容合法合规性,禁止用于任何商业用途!

小红书作为国内极具影响力的社区种草平台,汇聚了大量用户且拥有极高的日活跃度,其笔记数据蕴含丰富的信息价值。在合法合规、遵循平台规则以及尊重用户隐私的前提下,对小红书笔记、评论、图片数据进行合理采集分析,能够帮助企业和用户更好的了解热门趋势和对标热门作品,助力从业者高效创作优质笔记!
基于以上背景,我利用python语言开发了一款软件“爬小红书图片软件”,但功能不止采集图片,还包括笔记数据、评论数据等。
软件界面如下:(目前已升至v2.0版)
保存的csv数据:(截图中展示的就是全部字段了)

如果csv截图看不清,可移步这里,更清晰:https://docs.qq.com/sheet/DVEFhZlFKR1NXVEdN?tab=2ophep
自动下载的图片:
附:csv文件中的“序号”列,和图片文件名前缀序号一一对应,2.3章节有详细解释。
软件操作演示视频:【爬虫软件】小红书图片采集工具,一键下载无水印图片
重要说明,请详读:
1、Windows系统、Mac系统均可运行!
2、需要在cookie.txt中填入cookie值,持久存储,方便长期使用
3、支持筛选笔记搜索关键词、笔记类型、排序方式,选择是否下载图片、是否采集评论等功能
4、爬取过程中,自动保存结果到csv文件(每爬一条存一次,防止数据丢失)
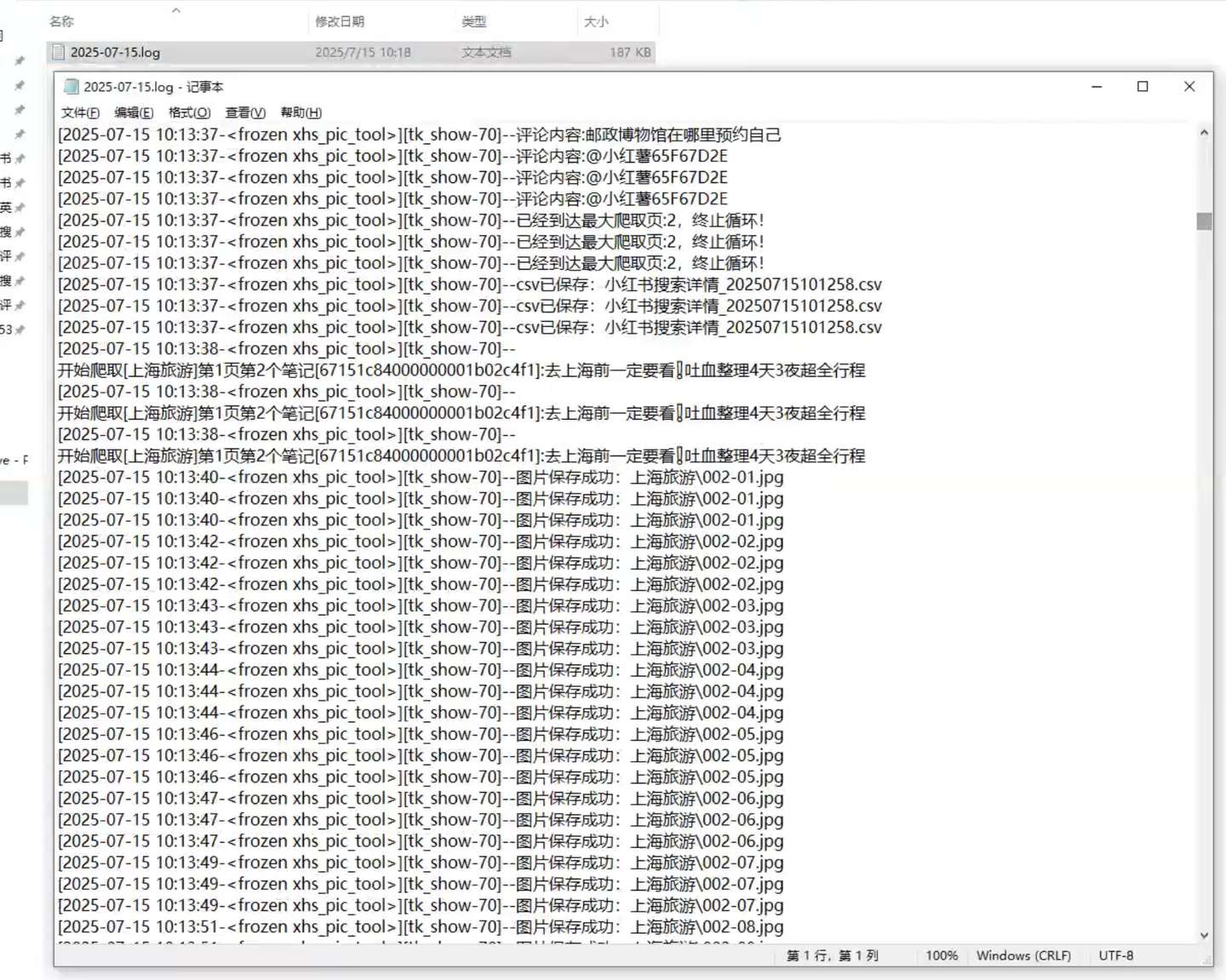
5、爬取过程中,有log文件详细记录运行过程,方便回溯
6、可爬20+关键字段,含:关键词,序号,笔记id,笔记链接,笔记链接_长,笔记标题,笔记内容,笔记类型,发布时间,修改时间,IP属地,点赞数,收藏数,评论数,转发数,用户昵称,用户id,用户主页链接,头图链接,评论内容(若干)软件界面上的设置项,包含:
1. 笔记搜索关键词(支持填多个)
2. 笔记类型:综合/图文/视频
3. 排序方式:综合/最新/最热
4. 下载图片:是/否
5. 前几条笔记:1~220(即,每个关键词爬前几条笔记)
6. 采集评论:是/否(不含二级评论)
7. 评论页数:可填选(即,采集评论的前几页,每页10条评论)软件界面,见图1。
软件运行过程中,自动导出数据结果到当前目录的csv文件,csv文件以时间戳命名,方便查找。
保存的字段有20+,含:关键词,序号,笔记id,笔记链接,笔记链接_长,笔记标题,笔记内容,笔记类型,发布时间,修改时间,IP属地,点赞数,收藏数,评论数,转发数,用户昵称,用户id,用户主页链接,头图链接,评论内容(若干)。
由于评论数量由用户指定,所以这里写的字段总数量是20+。
csv数据结果,见图2。
图片的保存规则为:
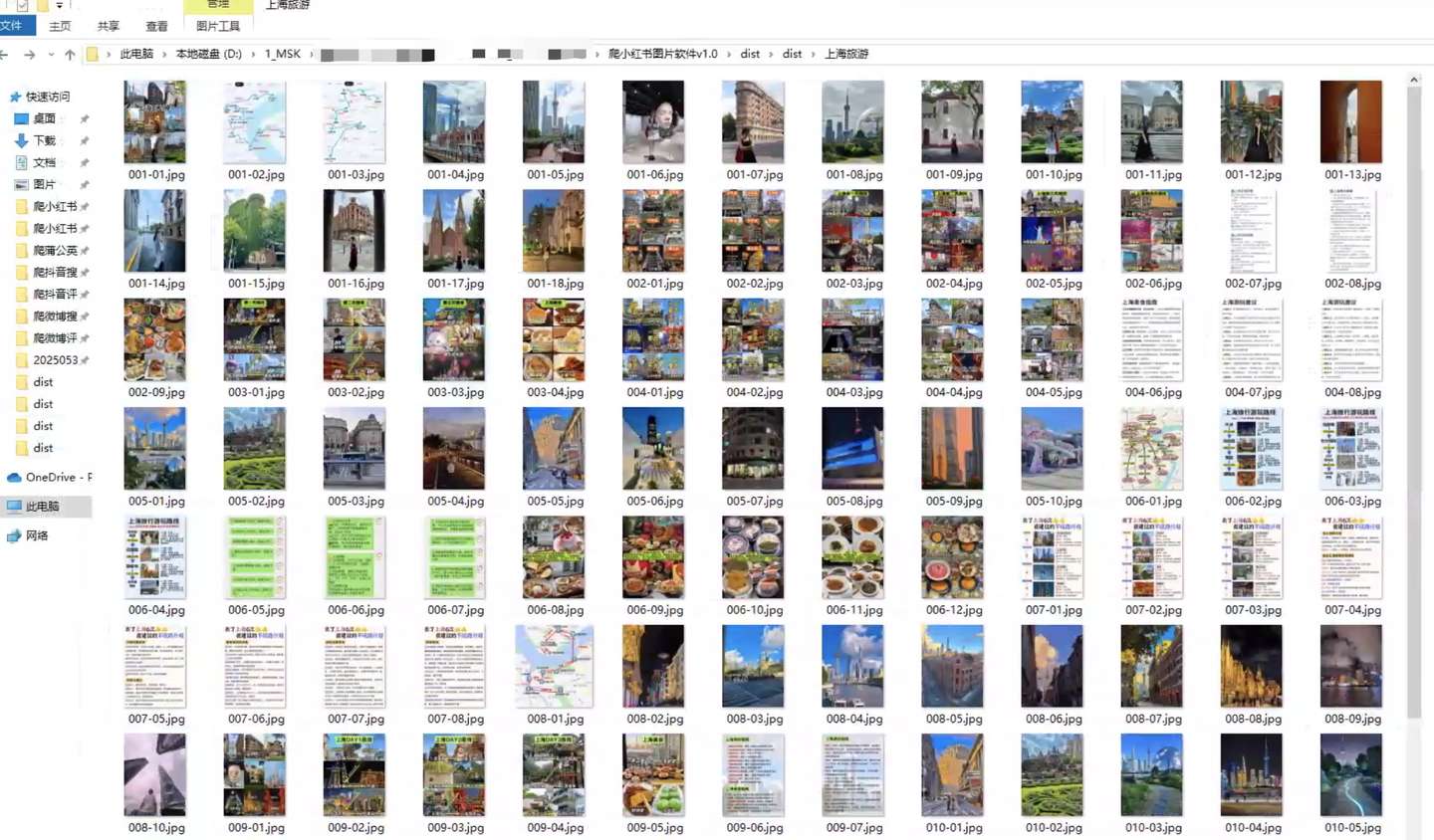
按照爬取的顺序序号保存,比如一个关键词下大约220条笔记,那么csv里存的笔记每条序号为001-220,对应的图片文件名就是001-01.jpg,001-02.jpg,002-01.jpg,以此类推。
一个关键词爬取下载的所有图片都存进《关键词》命名的文件夹里。
简单来说,文件夹以《关键词》命名,文件夹里的每个图片文件以序号命名,图片序号和csv里的序号一一对应。从而实现对应关系,方便查找指定笔记对应的图片。 图片保存结果,见图3。
此软件开发成本较高,代码量大、实现逻辑复杂,为保护个人知识版权,防止恶意盗版软件,不展示爬虫核心代码。
运行软件之前,需要填写cookie值到txt配置文件中,获取方法如下:
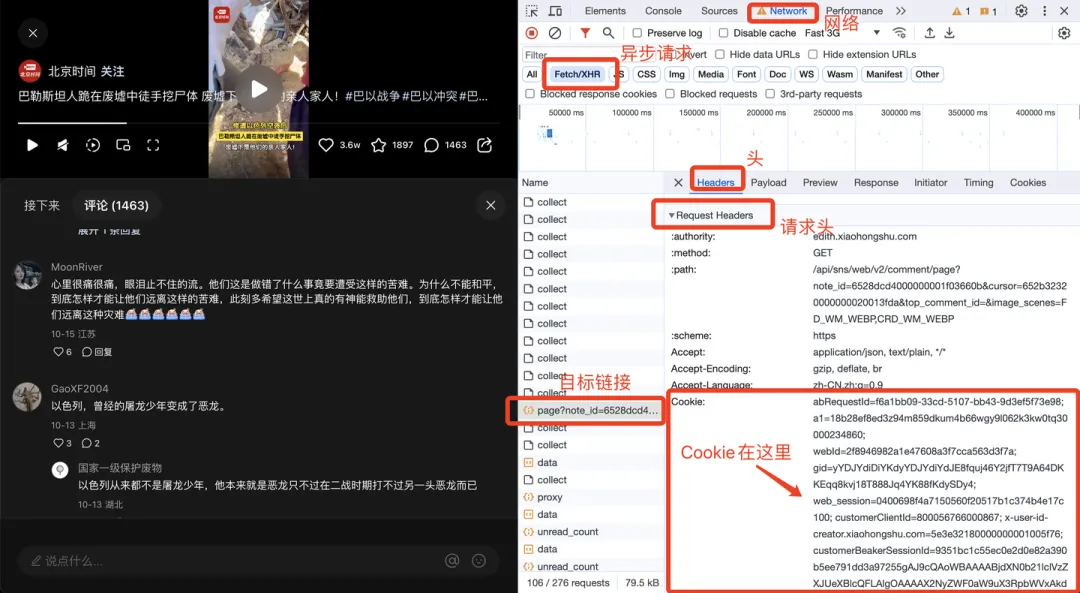
然后把获取到的cookie值存入当前文件夹下的cookie.txt文件,并保存。
主窗口部分:
# 创建主窗口
root = tk.Tk()
root.title('爬小红书图片软件v1.0 | 马哥python说')
# 设置窗口大小
root.minsize(width=850, height=650)部分界面控件:
# 搜索关键词
tk.Label(root, justify='left', text='搜索关键词:').place(x=30, y=100)
entry_kw = tk.Text(root, bg='#ffffff', width=78, height=2, )
entry_kw.place(x=110, y=100, anchor='nw') # 摆放位置
tk.Label(root, justify='left', text='多关键词以空格分隔', fg='red').place(x=665, y=100)日志输出控件:
# 运行日志
tk.Label(root, justify='left', text='运行日志:').place(x=30, y=250)
show_list_Frame = tk.Frame(width=780, height=300) # 创建<消息列表分区>
show_list_Frame.pack_propagate(0)
show_list_Frame.place(x=30, y=270, anchor='nw') # 摆放位置好的日志功能,方便软件运行出问题后快速定位原因,修复bug。
核心代码:
def get_logger(self):
self.logger = logging.getLogger(__name__)
# 日志格式
formatter = '[%(asctime)s-%(filename)s][%(funcName)s-%(lineno)d]--%(message)s'
# 日志级别
self.logger.setLevel(logging.DEBUG)
# 控制台日志
sh = logging.StreamHandler()
log_formatter = logging.Formatter(formatter, datefmt='%Y-%m-%d %H:%M:%S')
# info日志文件名
info_file_name = time.strftime("%Y-%m-%d") + '.log'
# 将其保存到特定目录
case_dir = r'./logs/'
info_handler = TimedRotatingFileHandler(filename=case_dir + info_file_name,
when='MIDNIGHT',
interval=1,
backupCount=7,
encoding='utf-8')软件运行过程中生成的日志文件:
付费如下:
日卡:使用期限1天,39元。日卡仅能购买一次。适合试用等临时需求
月卡:使用期限1个月,149元。月卡可多次购买。适合短期采集需求
季卡:使用期限3个月,399元。季卡可多次购买。适合中期采集需求
年卡:使用期限1年,799元。年卡可多次购买。适合长期采集需求付费方式:

付费后,加我v(493882434)自动掉落登录卡密。
软件采用一机一码机制,一个卡密只能在一台电脑运行、不可多电脑运行。
一台电脑仅允许运行一个软件,不支持软件多开。
软件由本人独立原创开发,长期维护更新,提供稳定运行。
"爬小红书图片软件"首发于公众号"老男孩的平凡之路",欢迎交流!
