link: https://arxiv.org/abs/1910.11480
合成音声生成の分野はtext-to-speechなどの登場により生成される音の質が向上しました。
しかし、WaveNetなどの非自己回帰モデルは性能は良いが、生成にとても時間がかかります。
生成時間を早くするために、蒸留を使ったものが提案されていたが、この方法もトレーニング過程の計算が難しかったりして大変。
なので、今回のParallel WaveGANは蒸留を使わずに生成にかかる時間を縮めたよっていうのが推したいとこ。
具合的には、多重解像度短時間フーリエ変換(Multi-STFT)と敵対損失関数の組み合わせを最適化することにより、少ないパラメータ数で蒸留なしでより早い音声生成を可能にした。
生成モデルは一般的に深くてパラメータ数の多いモデルの方が精度が上がりやすいことが知られている。
また、単一のモデルで予測するよりも、複数モデルの予測結果を組み合わせるアンサンブル学習の方が精度が上がることも知られている。
精度のみが問題になる場合、以下のようなアプローチが取られる。
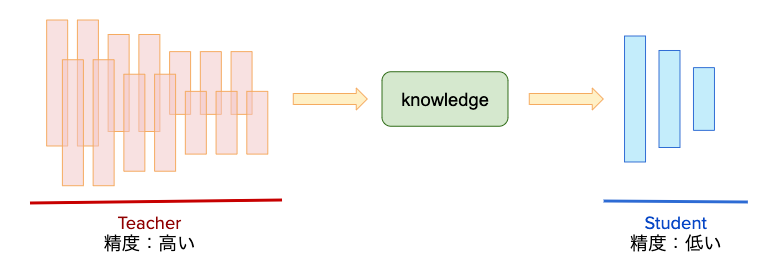
予測精度の良い深いモデルやアンサンブルさせたモデルを教師モデルとして準備しておき、その知識を軽量で再現できる生徒モデルの学習に利用する。
これにより、軽量でありながら高精度の教師モデルを引き出すことができる。
ジェネレータはWaveNetベース。
以下はジェネレータとディスクリミネータの関係式。
この時、
はwhite noiseを示す。
この式の敵対的損失(
)を最小限に抑えることにより学習が実行される。
次の最適化基準を私用して、生成されたサンプルを偽として正しく分類するように、識別器がトレーニングされる。
と
はそれぞれターゲット波形とその分布を示す。
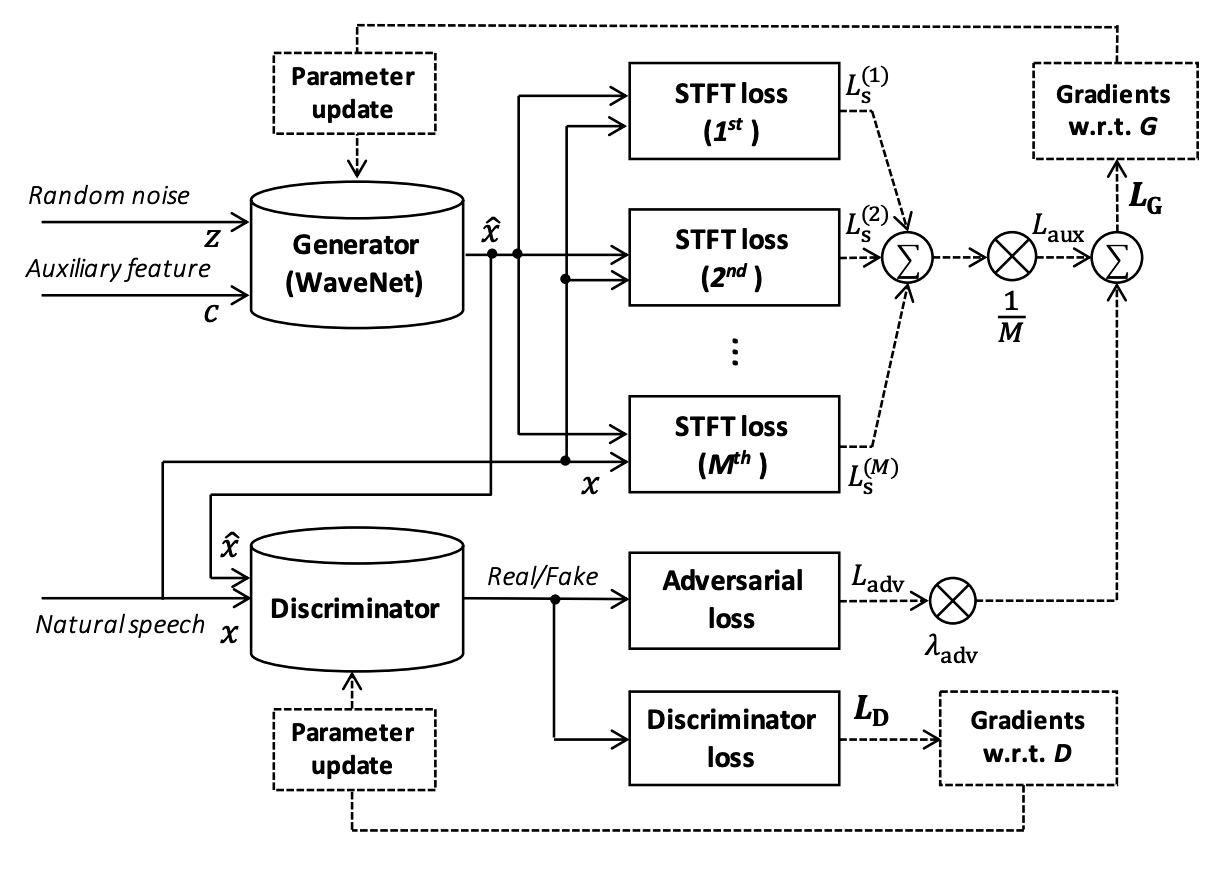
安定性と効率を上げるために、多重解像度解像度STFT損失を提案する。
以下の図は多重解像度STFT損失と敵対的なトレーニング法を組み合わせたフレームワークのイメージ図。
単一のSTFT損失は次のように定義する。
ここでの
は生成されたサンプルを示し、
と
はそれぞれスペクトル収束とlog STFT振幅損失を示す。
ここで、
と
はそれぞれフロベニウスとL1ノルムを示し、
と
はそれぞれSTFTの大きさと要素数を示す。
多重解像度STFT損失は様々な分析パラメータでのSTFT補助損失
は次のように表される。
ジェネレータの最終的な損失関数は、次の多重解像度STFT損失と敵対的損失の線形結合として定義される。
は2つの損失項のバランスを取るハイパーパラメータを示す。
波形ドメイン敵対損失とマルチ解像度STFT損失を共同で最適化することにより、ジェネレータは現実的な音声波形の分布を効率的に学習できる。
使用したデータについて
- 日本人の女性声優の発話したデータセットの音声コーパス
- トレーニングデータ -> 11,499発話(23.09時間)
- 検証 -> 250発話(0.35時間)
- 評価 -> 250発話(0.34時間)
- メルスペクトログラムの特徴は、トレーニング前にゼロ平均、単位分散を持つように正規化された
比較のために使用したモデルは以下である
- 普通のWaveNet
- ClariNet(WaveNetに並列計算を加えたもの)
- STFT損失1つ
- STFT損失3つ
- ClariNet-GAN(ClariNetに敵対的損失を入れたもの)
- STFT損失1つ
- STFT損失3つ
- Parallel WaveGAN
- STFT損失1つ
- STFT損失3つ
性能の評価を人間の知覚の観点で行うためにMOSテスト(平均オピニオンスコア)を行った。
- 評価者は18人の日本語ネイティブスピーカー
- 評価は5段階で行う
- 1 = Bad
- 2 = Poor
- 3 = Fair
- 4 = Good
- 5 = Excellent
- 様々なモデルによって合成された発話セットからランダムに20の発話を抽出し評価してもらった
以下の図は結果
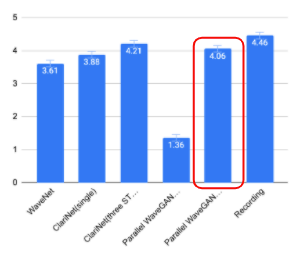
結果から読み取れること
-
STFT損失でトレーニングされたシステムの方が優れたパフォーマンスだった
-
多重解像度のSTFT損失ベースのモデルは、従来の単一のSTFT損失ベースのmドエルより高い知覚品質を示した これにより、多重解像度のSTFT損失が音声信号の時間周波数特性を効果的にキャプチャし、より優れたパフォーマンスを実現できることが確認された
-
敵対的損失はClariNetではうまく機能しなかった
-
Parallel WaveGANは4.06MOSを達成したが、ClariNetよりは劣っていた
以下の表は、トレーニングに要した時間である
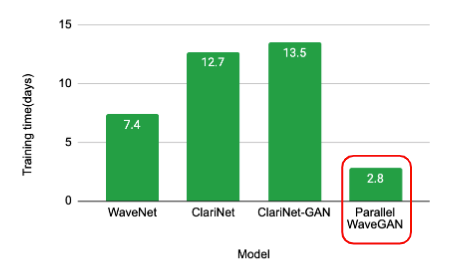
Parallel WaveGANは2.8日でトレーニングできた。
これは、自己回帰WaveNetの2.64倍、ClariNetの4.82倍高速だった。
TTS(txst-to-speech)フレームワークを組み合わせての実験も行った。
トランスフォーマをトレーニングするために、入力として音素シーケンスを使用し、録音された音声から抽出されたメルスペクトルグラムを出力として使用した。
これによって日本語のようなピッチアクセント言語への対応力が上がった。
生成された音声を評価するためにこれもMOSテストを行った。
以下の表が結果。
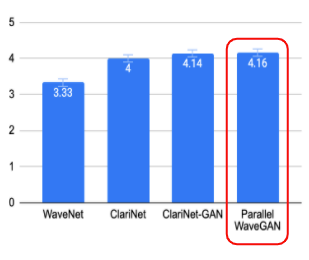
-
知覚品質はほぼ同じだったが、敵対的損失を使用して訓練されたClariNetは敵対的損失を使用せず訓練されたシステムよりも優れたパフォーマンスを示した
-
Parallel WaveGANも敵対的トレーニングによる恩恵が出ていた
-
Parallel WaveGANは4.16MOSを達成し、ClariNetGANにも匹敵した
-
蒸留不要で高速で小フットプリントですむGANによる波形生成方法であるParallel WaveGANができた
-
多重解像度STFT損失は蒸留せずとも良い音を生成できた
-
TTSと組み合わせると、Parallel WaveGANは従来の方法よりもかなり高速で、品質を下げることなく生成できた
-
将来的には、多重解像度STFT損失を改善して音声の特性をより適切に捉えるものにすることが考えられる
- 位相関連の損失を導入する
- 表現能力を含む様々なコーパスに対するパフォーマンス検証