- 자연어처리분야
- 요약기술을 통해 기사,문서,논문 등의 중복적인 내용을 제거하고 핵심내용을 파악할 수 있게 도와주는 서비스 제공
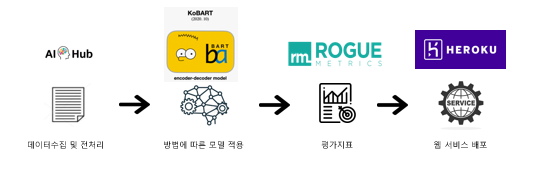
-
- 추출적 요약(TextRank) : 원문에서 중요한 핵심문장과 단어를 뽑아 이들로 구성된 요약
- 단점 : 이미 존재하는 문장, 단어로만 구성되어 모델의 언어표현능력 제한
-
- 추상적 요약(seq2seq) : 원문에 없던 문장이라도 핵심문맥을 반영한 새로운 문장을 생성하여 요약
- 단점 : seq2seq같은 지도학습 모델을 사용하여 원문과 요약된 레이블 데이터가 둘 다 필요함
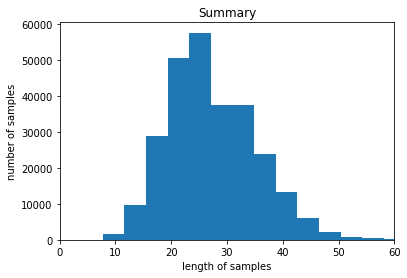
- AI hub 문서요약텍스트 데이터 사용
- 약 30만개 정도의 법률문서, 사설잡지, 신문기사 데이터로 구성
| DataSet | Size |
|---|---|
| Train | 271093 |
| Valid | 30122 |

- 약 670개 정도로 이루어진 불용어사전을 가져온 후 본문데이터에서 제거
- 전처리 함수를 사용하여 url,이메일,기호 등 메타문자 제거
| DataSet | Size |
|---|---|
| Train | 270637 |
| Valid | 29830 |


- 추출적 요약(TextRank)
- KoNLPy를 토크나이저로 사용
- textrank의 KeywordSummarizer를 사용하여 중요 키워드 추출
- 추상적 요약(seq2seq)
- seq2seq모델을 사용하여 입력된 시퀀스로부터 다른 도메인의 시퀀스 출력
- KoBART-summarizaton 사용 : https://github.com/SKT-AI/KoBART
- 데이터 추가 후 학습
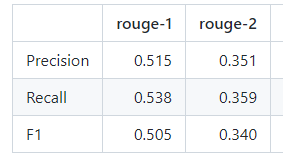
- ROGUE metric 사용 : 시스템요약(모델이 만든 요약)과 참조요약(사람이 만든 요약)간 겹치는 단어의 수를 가지고 평가
- ROUGE-1 : 시스템 요약본과 참조 요약본 간 겹치는 unigram의 수(n=1)
- ROUGE-2 : 시스템 요약본과 참조 요약본 간 겹치는 bigram의 수(n=2) ex) the cat, the bed..
- KoBART모델의 rogue지표
- 실제 뉴스기사를 스크랩하여 두 가지 요약기법 비교결과 추출적요약은 중복도 섞인 방면 추상적요약은 더 깔끔하게 요약한 것으로 보여짐

- 서비스 시연
- flask를 통해 로컬웹 제작
- heroku를 통해 웹 배포
