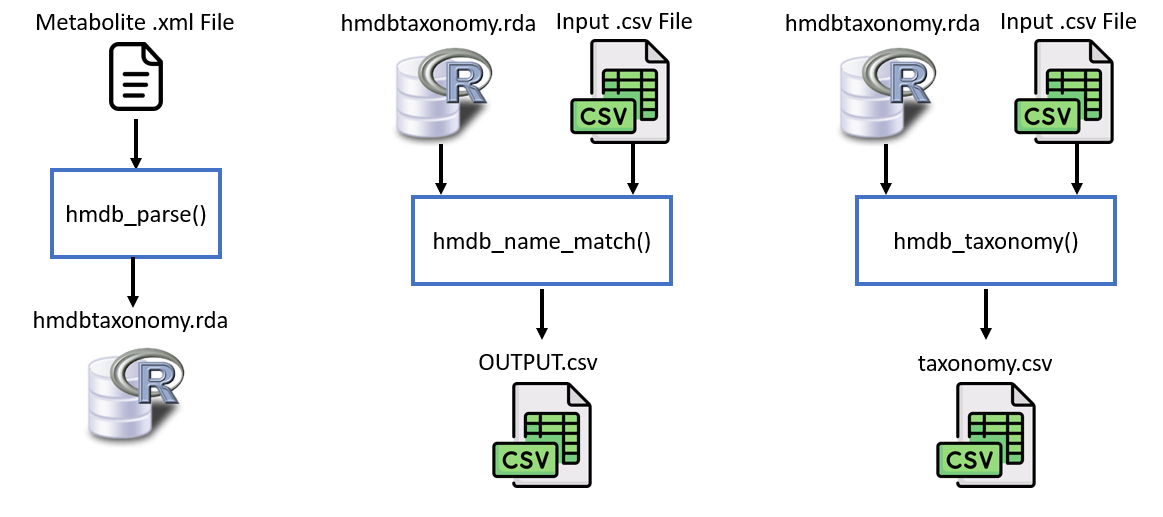
hmdbtaxonomy is a package used to parse HMDB .xml files, match metabolite names to their HMDB ID, and provide chemical taxonomies from HMDB IDs by writing to .csv files.
To install the package, type this in R command line:
install.packages("devtools")
devtools::install_github("lemaslab/hmdbtaxonomy")
library(hmdbtaxonomy)
hmdb_parse()
Input to the function is an .xml file, formatted from the HMDB website. Output is hmdbtaxonomy.rda. Function parses a .xml file for certain data and places it in a lists of lists which is stored under the variable hmdb. Variable hmdb[[1]] would include the parsed information of the first metabolite from the xml file.
hmdb_name_match()
Input to function is a csv file and the output is OUTPUT.csv. Metabolite names should be under a column named "metabolites". HMDB IDs will be outputted to a column "hmdb_id". Please make sure these columns are already included in the input csv. Please also load in the variable hmdb from an rda file or generated from hmdb_parse. Matches will only be made when the name is direct match for the official HMDB ID name, not synonyms.
hmdb_taxonomy()
Input to function is a csv file and the output is taxonomy.csv. Please make sure the variable "hmdb" was loaded in from an rda file, either generated from hmdb_parse or loaded in. This function extracts the chemical taxonomy of metabolites from a csv file. HMDB IDs should be under the column "hmdb_id". Taxonomy will be outputted on column names "super_class", "class", "sub_class", "direct_parent". Please make sure these columns are already included in the csv.