Using pandas, numpy, seaborn, and matplotlib to get stock information, visualize different aspects of it, and analyze the risk of a stock from previous performance history.
Info that would be visualized
- Change in price over time
- Daily return of the stock market average
- Moving average of the various stocks
- Correlation between different stocks' closing price
- Correlation between different stocks' daily returns
- Value that should be put at risk when investing a certain stock
- How to predict future stock behaviour
- Bootstrap Method
- Monte Carlo Method
import pandas as pd
from pandas import Series, DataFrame
import numpy as np
#Visualization
import matplotlib.pyplot as plt
import seaborn as sns
sns.set_style('whitegrid')
%matplotlib inline
#For reading stock data
from pandas_datareader import data, wb
import pandas_datareader as pdr
#For time stamps
from datetime import datetime
#Division
from __future__ import division #Using Yahoo to grab stock information
tech_stock = ['GOOG','MSFT','AMZN','AAPL']end = datetime.now()
#Setting start and end date (a year ago now)
start = datetime(end.year - 1, end.month, end.day)#Setting up Yahoo's financial data as a dataframe
for stock in tech_stock:
globals()[stock] = pdr.get_data_yahoo(stock, start,end)AAPL.describe() #Statistics on Apple stocks | Open | High | Low | Close | Adj Close | Volume | |
|---|---|---|---|---|---|---|
| count | 251.000000 | 251.000000 | 251.000000 | 251.000000 | 251.000000 | 2.510000e+02 |
| mean | 141.341315 | 142.295060 | 140.435937 | 141.474103 | 140.677993 | 2.793747e+07 |
| std | 16.902716 | 16.923112 | 16.647013 | 16.736888 | 17.202225 | 1.190328e+07 |
| min | 106.570000 | 107.680000 | 104.080002 | 105.709999 | 104.410980 | 1.147590e+07 |
| 25% | 130.944999 | 132.154998 | 130.784996 | 131.784996 | 130.165566 | 2.067555e+07 |
| 50% | 144.449997 | 145.300003 | 143.449997 | 144.289993 | 143.610962 | 2.533170e+07 |
| 75% | 154.799995 | 155.470001 | 153.805001 | 154.735001 | 154.431870 | 3.221495e+07 |
| max | 174.000000 | 174.259995 | 171.119995 | 172.500000 | 172.500000 | 1.119850e+08 |
AAPL.info()<class 'pandas.core.frame.DataFrame'>
DatetimeIndex: 251 entries, 2016-11-07 to 2017-11-03
Data columns (total 6 columns):
Open 251 non-null float64
High 251 non-null float64
Low 251 non-null float64
Close 251 non-null float64
Adj Close 251 non-null float64
Volume 251 non-null int64
dtypes: float64(5), int64(1)
memory usage: 13.7 KB
#Historical view on closing price
AAPL['Adj Close'].plot(legend=True, figsize=(10,4))<matplotlib.axes._subplots.AxesSubplot at 0x1070d3a10>

#Total volume of stock being traded each day over the course of 5 years
AAPL['Volume'].plot(legend=True,figsize=(12,4))<matplotlib.axes._subplots.AxesSubplot at 0x1a10af4090>

#Calculating three moving averages
#MA = Moving Average
ma_day = [5,10,15,20]
for ma in ma_day:
column_name = "MA for %s days" %(str(ma))
AAPL[column_name] = Series.rolling(AAPL['Adj Close'],ma).mean()AAPL[['Adj Close','MA for 5 days','MA for 10 days','MA for 15 days','MA for 20 days']].plot(subplots=False,figsize=(10,4))<matplotlib.axes._subplots.AxesSubplot at 0x1a119b6710>

- Daily Changes of stocks
#Percent Change for each day
AAPL['Daily Return'] = AAPL['Adj Close'].pct_change()
AAPL['Daily Return'].plot(figsize=(16,4),legend=True,linestyle='--',marker='o')<matplotlib.axes._subplots.AxesSubplot at 0x1a1214ca10>

#Seaborn does not recongize null values so I have to use dropna()
sns.distplot(AAPL['Daily Return'].dropna(),bins=100,color='purple')<matplotlib.axes._subplots.AxesSubplot at 0x1a11dd53d0>

#Using a histogram plot
AAPL['Daily Return'].hist()<matplotlib.axes._subplots.AxesSubplot at 0x1a12630bd0>

# Grab all the closing prices for the tech stock list into one DataFrame
closingPrice_dataFrame = pdr.get_data_yahoo(['AAPL','MSFT','AMZN','GOOG'],start,end)['Adj Close']closingPrice_dataFrame.head()| AAPL | AMZN | GOOG | MSFT | |
|---|---|---|---|---|
| Date | ||||
| 2017-11-03 | 172.500000 | 1111.599976 | 1032.479980 | 84.139999 |
| 2017-11-02 | 168.110001 | 1094.219971 | 1025.579956 | 84.050003 |
| 2017-11-01 | 166.889999 | 1103.680054 | 1025.500000 | 83.180000 |
| 2017-10-31 | 169.039993 | 1105.280029 | 1016.640015 | 83.180000 |
| 2017-10-30 | 166.720001 | 1110.849976 | 1017.109985 | 83.889999 |
techReturns_dataFrame = closingPrice_dataFrame.pct_change()#Comparing Google to Google
sns.jointplot('GOOG','GOOG',techReturns_dataFrame,kind='scatter',color='cyan')<seaborn.axisgrid.JointGrid at 0x1a12968410>

#Dealing with correlations now
#Comparing Google with microsoft and seeing if there's any correlation
sns.jointplot('GOOG','MSFT',techReturns_dataFrame,kind='scatter')<seaborn.axisgrid.JointGrid at 0x1a12c35f90>

From what is presented above, there seem to be some sort of correlation forming
#A sense of what's correlated and what is not
from IPython.display import SVG
SVG(url='http://upload.wikimedia.org/wikipedia/commons/d/d4/Correlation_examples2.svg')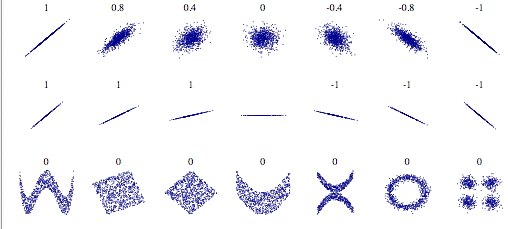
#To see the correlation for all the companies all at once
sns.pairplot(techReturns_dataFrame.dropna())<seaborn.axisgrid.PairGrid at 0x1a13cfb150>

#Full control of the figure, including the upper triangle, and the lower triangle
fig = sns.PairGrid(techReturns_dataFrame.dropna())
fig.map_upper(plt.scatter,color='red')
fig.map_lower(sns.kdeplot,cmap='cool_d')
fig.map_diag(plt.hist,bins=20)<seaborn.axisgrid.PairGrid at 0x1a13d13890>

#Correlation of closing price
fig = sns.PairGrid(closingPrice_dataFrame.dropna())
fig.map_upper(plt.scatter,color='red')
fig.map_lower(sns.kdeplot,cmap='cool_d')
fig.map_diag(plt.hist,bins=20)<seaborn.axisgrid.PairGrid at 0x1a13bb1610>

- Gathering daily percentage returns by comparing the expected return with the standard deviation of the daily returns
returns = techReturns_dataFrame.dropna()plt.scatter(returns.mean(), returns.std(), alpha=0.5,s = np.pi*20)
#Setting limits
plt.ylim([0.005,0.025])
plt.xlim([-0.003,0.002])
#Set the plot axis titles
plt.xlabel('Expected Returns')
plt.ylabel('Risk')
#Labelling the scatterplots: http://matplotlib.org/users/annotations_guide.html
for label, x, y in zip(returns.columns, returns.mean(), returns.std()):
plt.annotate(
label,
xy = (x, y), xytext = (50, 50),
textcoords = 'offset points', ha = 'right', va = 'bottom',
arrowprops = dict(arrowstyle = '-', connectionstyle = 'arc3,rad=-0.3'))
Calculate the empirical quantiles from a histogram of daily returns. Quantiles information http://en.wikipedia.org/wiki/Quantile
#Repeating the daily returns for histogram for Apple Stock
#.displot = distribution plot
sns.distplot(AAPL['Daily Return'].dropna(),bins=100,color='purple')<matplotlib.axes._subplots.AxesSubplot at 0x1a16bb95d0>

#0.05 empirical quantiles of daily returns
returns['AAPL'].quantile(0.05)-0.01729882171950793
This is very interesting to see. With 0.05 empirical quantiles, the daily returns is -0.017. The definition of this is that with 95% confidence, the worst daily loss will not surpass 1.7%. If I had $10 000, my one day VaR (Value at Risk) would be $170
Brief Overview: Using the Monte Carlo Method to run many trials with random market conditions and therefore calculate losses/gains for each trial. Then using aggregation to from the trials to establish the risk of a certain stock.
The Stock Market will follow a random walk (Markov process) and is following the weak form of EMH (Efficient Market Hypothesis) The weak form of EMH states that the next price movement is conditionally dependent on past price movements given that the past prices have been incorporated.
This means that the exact price cannot be predicted perfectly solely based on past stocks information
EMH: https://en.wikipedia.org/wiki/Efficient-market_hypothesis
Makov Process: https://en.wikipedia.org/wiki/Markov_chain (A stochastic process that satisfies the Markov property if one can make predictions for the future of the process based solely on its present state just as well as one could knowing the process's full history)
Geometric Browninan Motion equation: (Markov Process)
In this equation s = stock price, μ = expected return, σ = standard deviation of returns, t = time, ϵ = random variable
Therefore multiplying the stock price by both sides, the equation is equal to:
μΔt is known as the "drift" where average daily returns are multiplied by the change in time. σϵ√Δt is known as the "shock" and the shock is where it'll push the stocks either up or down. By doing drift and shock thousand of times, a simulation can occur to where a stock price might be. Techniques were summarized from here: http://www.investopedia.com/articles/07/montecarlo.asp
#Setting up the year:
days = 365
#Setting dt
dt = 1/365
#Finding the dift of Google's dataframe
mu = returns.mean()['GOOG']
#Calculating the volatility
sigma = returns.std()['GOOG']'''
The following function takes in starting stock prices,
days of simulations, mu, and sigma.
It returns a simulated price array
'''
def stock_monte_carlo(start_price, days, mu, sigma):
price = np.zeros(days)
price[0] = start_price
shock = np.zeros(days)
drift = np.zeros(days)
for x in xrange(1,365):
#calculating the shock (σϵ√Δt )
shock[x] = np.random.normal(loc=mu*dt,scale = sigma*np.sqrt(dt))
#calculate Drift
drift[x] = mu * dt
#calculate Price
price[x] = price[x-1] + (price[x-1] * (drift[x] + shock[x]))
return price GOOG.head()| Open | High | Low | Close | Adj Close | Volume | |
|---|---|---|---|---|---|---|
| Date | ||||||
| 2016-11-07 | 774.500000 | 785.190002 | 772.549988 | 782.520020 | 782.520020 | 1585100 |
| 2016-11-08 | 783.400024 | 795.632996 | 780.190002 | 790.510010 | 790.510010 | 1350800 |
| 2016-11-09 | 779.940002 | 791.226990 | 771.669983 | 785.309998 | 785.309998 | 2607100 |
| 2016-11-10 | 791.169983 | 791.169983 | 752.179993 | 762.559998 | 762.559998 | 4745200 |
| 2016-11-11 | 756.539978 | 760.780029 | 750.380005 | 754.020020 | 754.020020 | 2431800 |
#Starting price
start_price = 774.50
for i in xrange(365):
plt.plot(stock_monte_carlo(start_price, days, mu, sigma))
plt.xlabel("Days")
plt.ylabel("Price")
plt.title("Monte Carlo Analysis for Google")Text(0.5,1,u'Monte Carlo Analysis for Google')

#Going to plot the above on a histogram for better visualization
#Going to run this simulation 10000 times now
runs = 10000
simulations = np.zeros(runs)
np.set_printoptions(threshold = 4) #Or else the output would be far too long to read
for i in xrange(runs):
#returning [days-1] because we're extracting the end date
simulations[i] = stock_monte_carlo(start_price, days, mu, sigma)[days-1]; # q as the 1% empirical qunatile therefore 99% of the values should fall between here
q = np.percentile(simulations, 1)
# Plotting the distribution of the end prices
plt.hist(simulations,bins=200)
# Using plt.figtext to fill in some additional information onto the plot
# Starting Price
plt.figtext(0.6, 0.8, s="Start price: $%.2f" %start_price)
# Mean ending price
plt.figtext(0.6, 0.7, "Mean final price: $%.2f" % simulations.mean())
# Variance of the price (within 99% confidence interval)
plt.figtext(0.7, 0.6, "VaR(0.99): $%.2f" % (start_price - q,))
# Display 1% quantile
plt.figtext(0.15, 0.6, "q(0.99): $%.2f" % q)
# Plot a line at the 1% quantile result
plt.axvline(x=q, linewidth=4, color='r')
# Title
plt.title("Final price distribution for Google Stock after %s days" % days, weight='bold');
From above, the Value at Risk seems to be $19.50 for every $774.50 invested.
If a user was putting $774.50 as an initial investment, it means he's putting $19.50 at risk.