'당신의 소리를 듣습니다'
모두의 말을 찰떡같이 알아듣는, 모두를 위한 챗봇
웹사이트 구현 https://github.com/decembix/HeardU
용량이 커 데이터셋과 pt파일은 드라이브 링크를 첨부합니다 https://drive.google.com/drive/folders/1ruJ-7WvVDxD31qLFK6ZOaix6OqD_GV4l?usp=drive_link

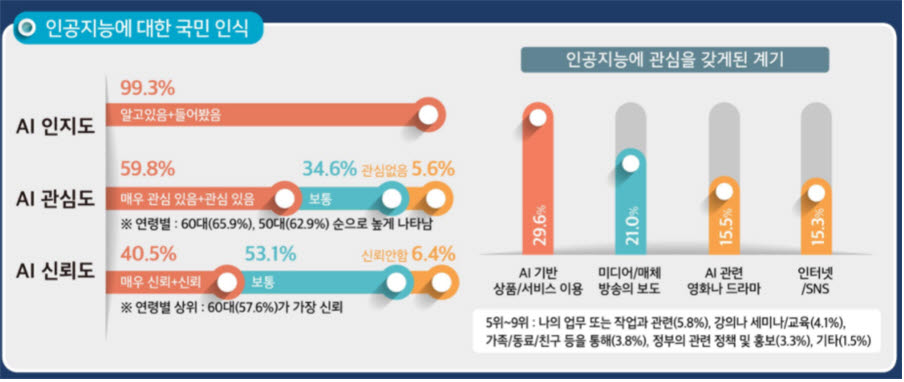
실제로 노령층이 일상에서 AI 효용을 체감하는 사례들이 속속 등장하고 있습니다. 경남 창녕군에서는 홀로 사는 80대 할머니가 마당에서 넘어져 다쳤는데 미리 교육받은 대로 '아리아 살려줘'라고 외치자 AI 스피커가 창녕군청 케어매니저에게 메시지를 발송했고, 케어매니저가 119에 구조요청, 신속히 인근 병원으로 후송돼 치료를 받을 수 있었습니다. 출처 [https://www.etnews.com/20211029000068]
이처럼 노령층은 AI에 꾸준한 관심을 보이고 있고 AI의 도움을 통해 살아가고 있습니다. 그런데 발음이 부정확하거나 표준어와 동떨어진 억양으로 인해 음성인식을 하지 못하는 사례들이 있습니다. 이를 문제삼아 프로젝트를 진행하려 합니다.
본 프로젝트는 고령자의 사투리, 느린 발화, 부정확한 발음 등으로 인해 음성 인식 정확도가 저하되는 문제를 해결하는 것을 목표로 합니다.
특히 고령층은 일반적인 STT(Speech-To-Text) 시스템이 학습한 데이터와 다른 억양이나 어휘를 사용하는 경우가 많아, 기존의 음성 인식 기술로는 정확한 텍스트 변환이 어렵습니다.
이러한 문제점을 기반으로, 본 프로젝트에서는 사투리 또는 부정확한 발음이 포함된 음성을 표준어 문장으로 변환하는 기술을 개발하고, 이를 기반으로 STT 시스템의 정화도를 향상시키는데에 주요 목적을 갖습니다.또한 고령자도 쉽게 사용할 수 있는 오프라인 기반의 STT 시스템을 구축하고, 더 나아가 변환된 표준어 문장을 기반으로 챗봇 API와 연동하는 것을 고려하고 있습니다.
- 데이터 출처: AIHub - 노인 남녀 대화 데이터
- 데이터 특징:
- 고령자의 실제 발화가 포함된 음성 데이터 (.wav)
- 사투리, 발음 오류, 억양의 차이 등 음성 다양성 확보
- JSON 메타데이터 포함 (발화 텍스트, 녹음 환경, 성별, 나이 등)
활용 목적
사투리 또는 부정확한 발음이 포함된 음성을 정확한 표준어로 변환하여
고령자 대상 AI 음성 인식 시스템의 정확도와 이해도를 향상시킵니다.
[1] 음성 입력 (.wav)
[2] Whisper 기반 STT
[3] 사투리 텍스트 추출
[4] 표준어 정제 모델
[5] 챗봇 API 호출
- 설정 편리 → HuggingFace처럼 간단하게 pip install 후 load_model() 한 줄로 바로 사용 가능
- 다양한 억양과 발음에 강함 → Whisper는 OpenAI가 다국어/다억양 데이터를 기반으로 학습 → 사투리, 느린 발화에도 상대적으로 강인
- 무료 GPU 사용의 한계 → tiny나 base 모델은 Colab 무료 GPU에서 충분히 돌아감 (속도/정확도 균형 O)
- 타 STT 모델의 경우 한글 미지원/ 한글을 지원하는 Clova의 경우엔 유료로 진행해야 함
- 데이터에 Label이 주어진 점을 바탕으로 Supervised Learning 사용
입력: 사투리 텍스트 정답(Label): 표준어 텍스트 일부 데이터는 수작업으로 정답 페어 구성 예정
- 폴더 : /content/HeardU
- 꼭 GPU사용!
→
import torch torch.cuda.is_available() - Whisper STT 구현+STT 기본적인 개념 학습
- Whisper 실습(wav파일)
- 샘플링 개념 학습+Whisper 구조 학습
- 실습 코드를 여러번 접하며 HeardU의 학습 코드를 완성하기
| 주차 | 날짜 | 내용 | 기여율 | 회의록 |
|---|---|---|---|---|
| 7주차 | 2025/04/07 | 프로젝트 주제 선정 및 모델 선택 | 권형미: 33% 박지인: 33% 윤서희: 33% |
바로가기 |
| 8주차 | 2025/04/21 | 모델 구체화 및 모델 학습 | 권형미: 33% 박지인: 33% 윤서희: 33% |
바로가기 |
| 9주차 | 2025/04/26 | 중간 발표 준비 | 권형미: 40% 박지인: 30% 윤서희: 30% |
바로가기 |
| 10주차 | 2025/05/05 | 프로젝트 구현 및 상황 공유 | 권형미: 30% 박지인: 30% 윤서희: 40% |
바로가기 |
| 11주차 | 2025/05/15 | 프로젝트 구현 및 상황 공유 | 권형미: 33% 박지인: 33% 윤서희: 33% |
바로가기 |
| 12주차 | 2025/05/22 | 프로젝트 구현 및 상황 공유 | 권형미: 40% 박지인: 30% 윤서희: 30% |
바로가기 |
| 13주차 | 2025/05/28 | 프로젝트 구현 및 상황 공유 | 권형미: 30% 박지인: 40% 윤서희: 30% |
바로가기 |
| 14주차 | 2025/06/05 | 프로젝트 최종 점검 | 권형미: 30% 박지인: 30% 윤서희: 40% |
|
| 15주차 | 2025/06/09 | 최종 발표 준비 |