Framework architecture
Detailed information about the architecture of the James framework is provided here, including several UML diagrams:
- Overview
- Problems, searches and neighbourhoods
- Detailed search components
- Subset selection
- Algorithms
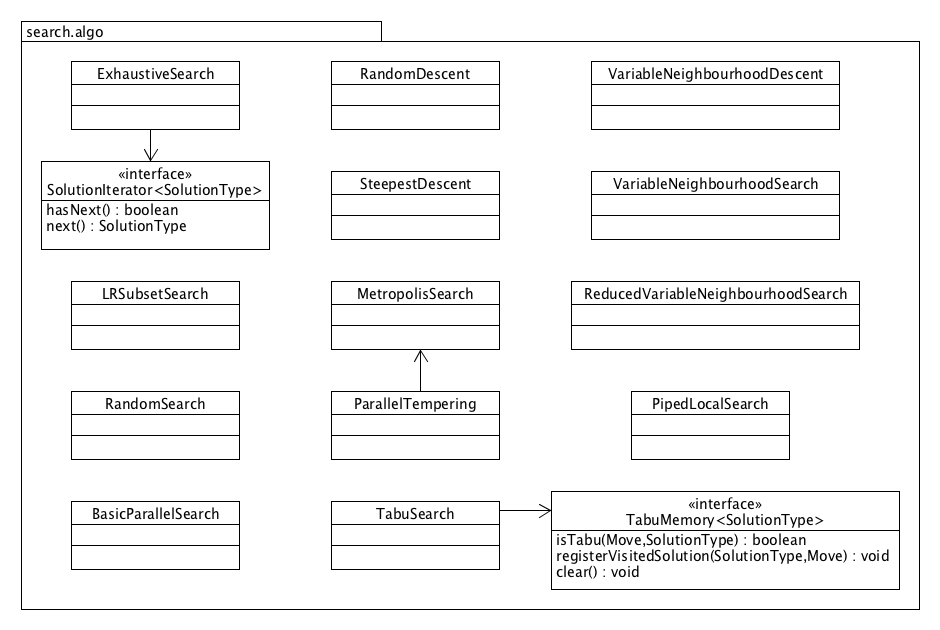
The diagram below presents an overview of the key components of the JAMES framework and their interactions.
A Search is responsible for solving a given Problem with a specific solution type. The search attempts to construct a good solution of this type, where the problem is responsible for evaluating and validating solutions and for generating random solutions. The problem also indicates whether evaluations are to be maximized or minimized. There is a clear separation between problem specification (left side of the diagram) and search implementation components (right side). In general, the search only communicates with the Problem interface and the actual problem implementation is hidden behind it.
A GenericProblem is provided which separates data from the objective, constraints (if any) and random solution generation. It introduces an additional parameter representing the data type. Any custom data type can be used for a specific problem, in combination with an objective and possibly some constraints that evaluate and validate solutions given this data.
A LocalSearch is a specific type of search that starts with some initial solution which is then modified in an attempt to improve it. By default, the initial solution is randomly generated. One very common way to modify the current solution is to repeatedly transform it into a similar, neighbouring solution. Such NeighbourhoodSearch uses one or more generic neighbourhoods that generate moves to be applied to the current solution. Any neighbourhood that is compatible with the solution type of the problem can be plugged in. Many metaheuristics such as random descent, steepest descent, tabu search, variable neighbourhood search and parallel tempering belong to this class of neighbourhood searches. Of course, the chosen neighbourhood(s) strongly determine(s) the search behaviour.
A search can have one or more stop criteria that request the search to terminate when a certain condition is met (such as a maximum runtime, maximum number of steps, maximum time without finding an improvement, etc.) if the search did not come to its natural end before that time. Many neighbourhood searches never terminate internally, so that they fully rely on stop criteria for termination. Finally, a search may have several listeners which are informed when certain events occur, e.g. when the search is started and stopped, or when a new best solution has been found. These can for example be used to track the progress of a search.
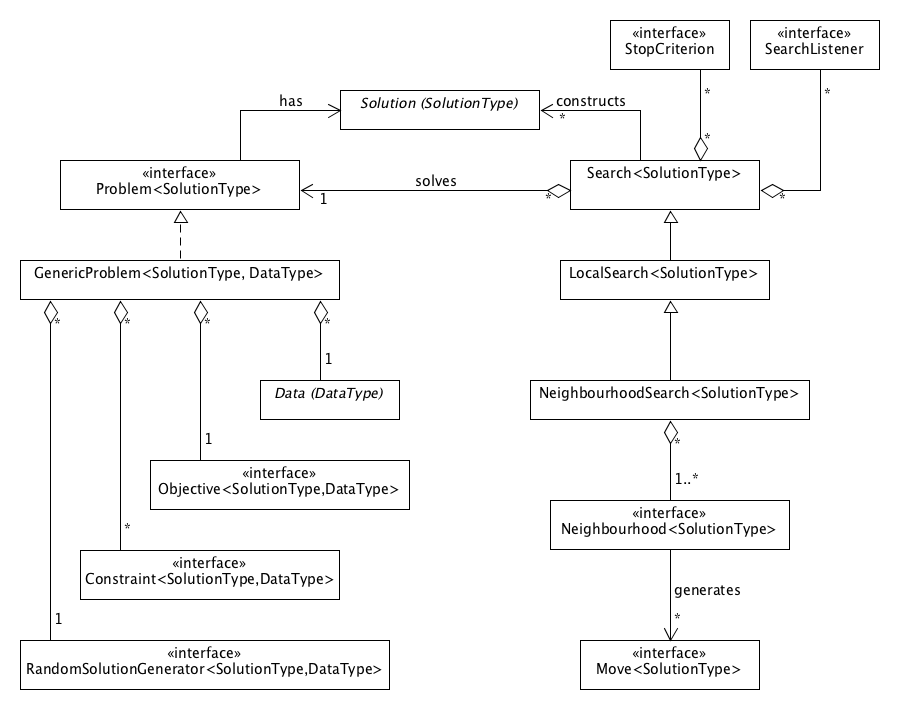
The core module consists of two major packages that contain components related to problem specification and search implementation, respectively.
The key components of the problems package are shown in the diagram below: the top-level Problem interface, the GenericProblem implementation and interfaces of objectives/constraints, together with the produced evaluations/validations, and of a random solution generator. The data type of a GenericProblem is very problem specific and therefore not confined in any way. A custom class can be used to model the data in combination with objectives and constraints that require this type of data. The solution type of a Problem is required to extend the abstract Solution class.
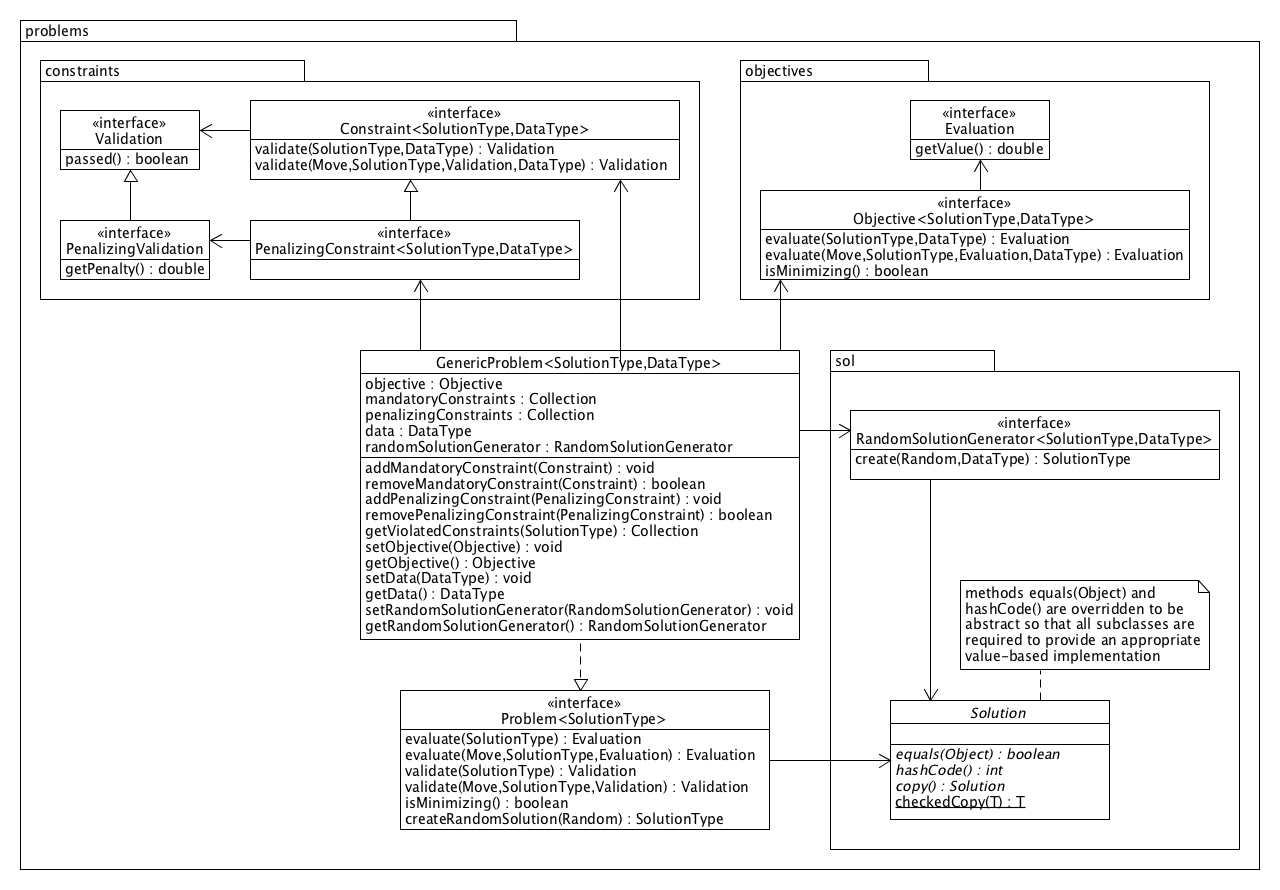
In a GenericProblem, the objective and constraints are responsible for evaluation and validation of solutions, respectively.
When evaluating a given solution, the objective returns an Evaluation, which can be converted into a double value that reflects the quality of the solution. The evaluation object may also contain custom metadata used for efficient delta evaluation: when a neighbour of the current solution needs to be evaluated in a neighbourhood search, it is often possible to effeciently obtain the new evaluation based on the current solution, its evaluation (including metadata if required) and the changes that will be made when applying the respective move.
Similarly, a constraint produces a Validation when checking a given solution or applied move, which has a method passed() that indicates whether the solution/move passed validation. Two types of constraints can be specified:
-
Mandatory constraints: a solution is valid only if it satisfies all mandatory constraints. If not, it is discarded regardless of its evaluation. It is guaranteed that the best solution found by a search will always satisfy all mandatory constraints. In a neighbourhood search, only those neighbours of the current solution that satisfy all mandatory constraints are considered.
-
Penalizing constraints: if a solution does not pass validation by a penalizing constraint, a penalty is assigned to its evaluation. The solution is not discarded. Penalties are usually chosen to reflect the severeness of the violation. Solutions closer to satisfaction are then favoured over solutions that violate the constraints more severely. In case of maximization, penalties are subtracted from the evaluation, while they are added to it in case of minimization. Depending on the interaction between the evaluation and penalties, the best found solution might not satisfy all penalizing constraints (which may or may not be desired).
It is allowed to combine any number of mandatory and penalizing constraints in a problem definition. A mandatory constraint returns validations of type Validation while a penalizing constraint is required to produce PenalizingValidation objects, a subtype of Validation which also includes the assigned penalty.
For both the objective and constraint interfaces, a default delta evaluation/validation is provided that (1) applies the move to the current solution, (2) evaluates/validates the obtained neighbour and (3) undoes the move. If desired a more efficient delta evaluation or validation can be plugged in by explicitely implementing the evaluate(Move, ...) or validate(Move, ...) methods, respectively. If necessary, additional metadata can be stored in the produced Evaluation or Validation objects, which are passed back to the objective/constraint for delta evaluation/validation.
The Solution class specifies three abstract methods used to detect equality of solutions, to compute
corresponding hash codes and to copy solutions. The default implementations of equals(Object) and hashCode() from the top-level Java Object class have been erased so that all solution types are required to provide an appropriate value-based implementation.
Calling copy() should return an identical solution which does not share any references with
the original solution (deep copy). It is required that the copy has the exact same type as the
original solution. A convenient static method checkedCopy(T) is provided in Solution to create type safe copies of any solution type T: this method returns a copy of the exact same type T given that the general contract of copy() is followed in all subclasses of Solution.
If a type mismatch occurs, a detailed exception is thrown that precisely indicates the cause of this mismatch
(probably an implementation mistake).
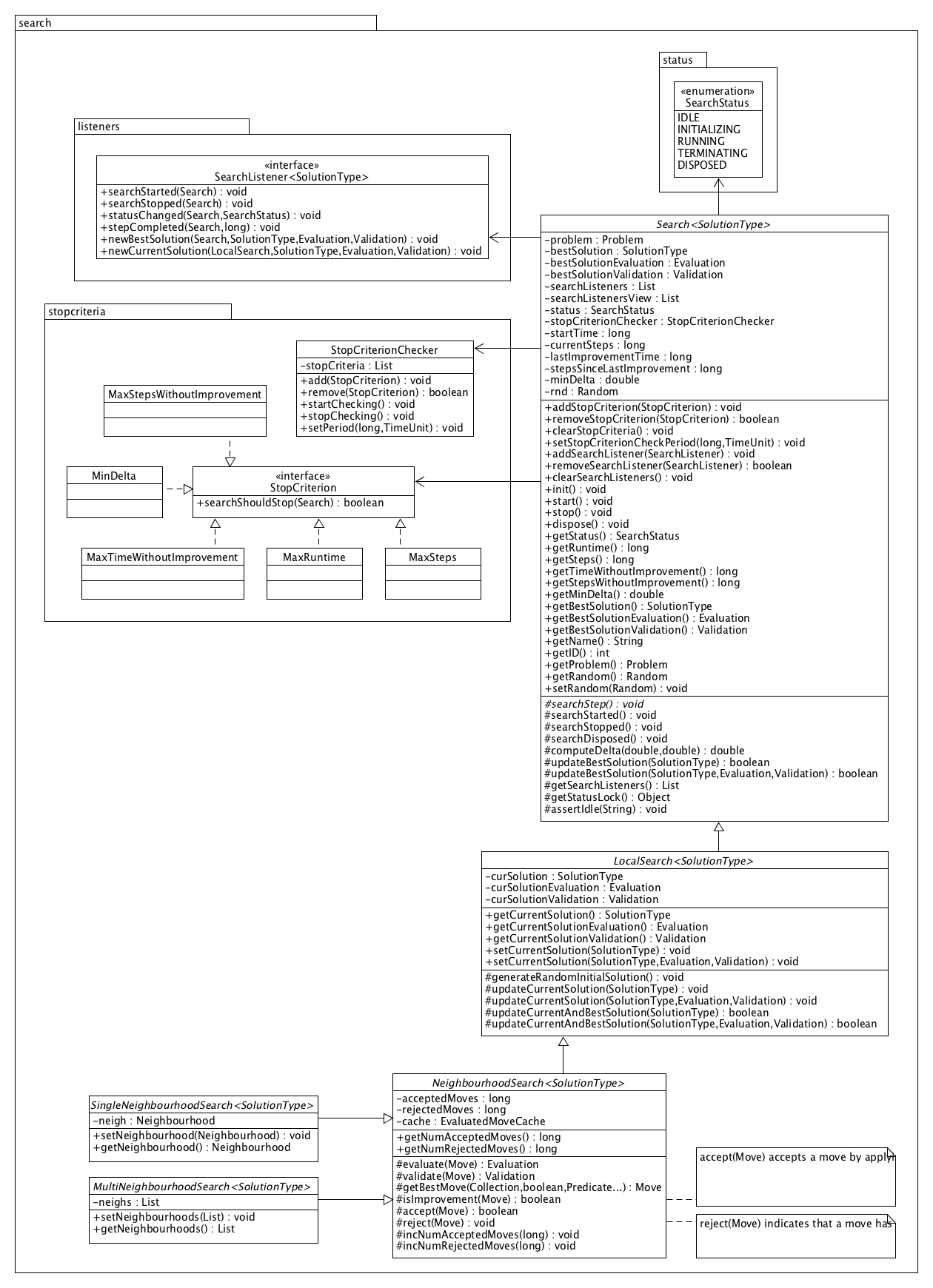
The main search related components are displayed in the diagram below. It shows all public methods of the top-level Search class and the more specific LocalSearch and NeighbourhoodSearch subclasses. These include general methods to start and stop the search, to attach search listeners or stop criteria, to get the best solution found so far and to access metadata such as the current runtime.
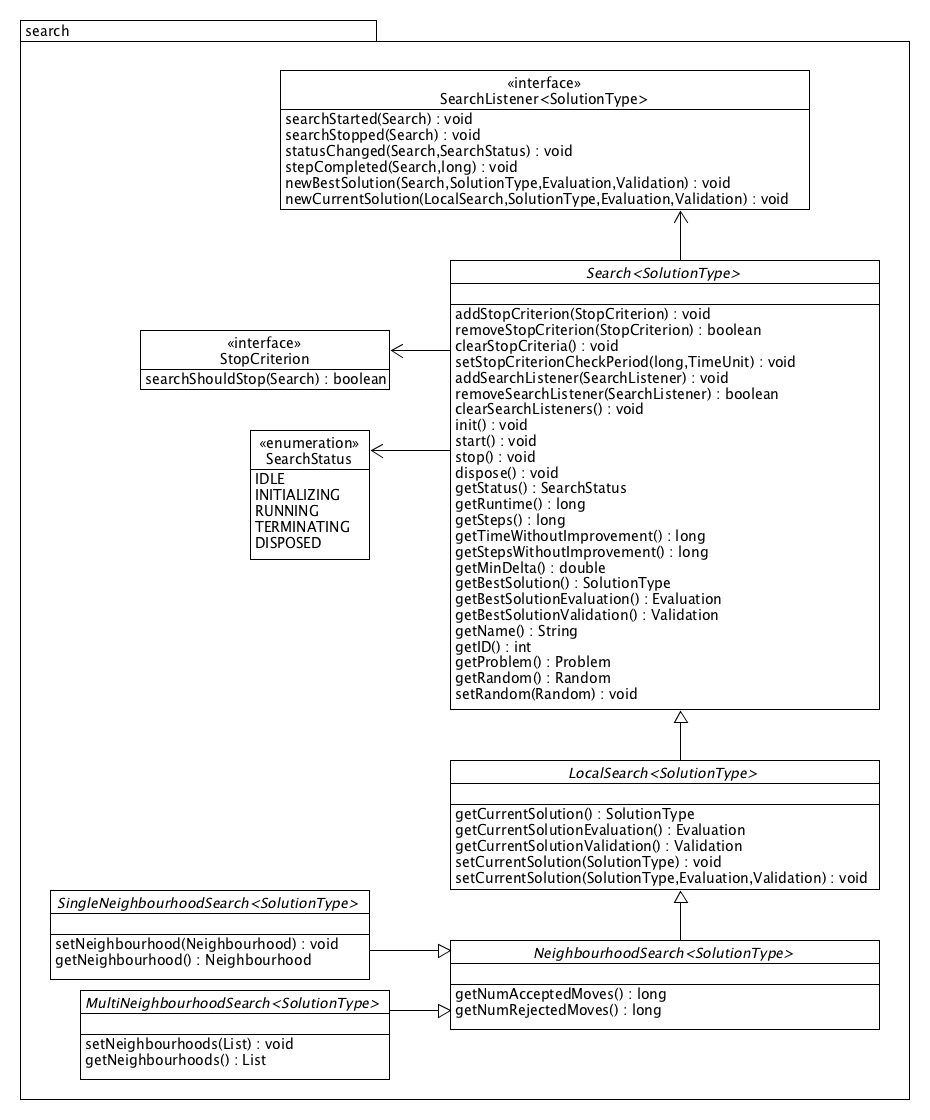
A local search also has methods to set and access the current solution. If the current solution is not set before starting the search, a random initial solution will be generated by most local searches (when calling init() or start()). A neighbourhood search adds methods to access metadata on the number of accepted and rejected moves, which have been generated by the neighbourhood(s) in an attempt to improve the current solution.
The class of neighbourhood searches is further subdivided into two types: SingleNeighbourhoodSearch and MultiNeighbourhoodSearch. The former provides an abstraction of neighbourhood searches with a single neighbourhood, e.g. random descent, steepest descent or Metropolis search, while the latter represents a neighbourhood search with multiple neighbourhoods, such as variable neighbourhood descent or variable neighbourhood search.
One or more search listeners may be attached to a search, which are informed when certain events occur, as defined in the SearchListener interface. Callbacks are for example fired when the search has started or stopped, when a new best solution has been found, or when a new current solution has been adopted in a local search.
Any number of stop criteria can be specified for a search. Each StopCriterion is repeatedly verified during search and the search is requested to terminate as soon as some stop criterion is satisfied. For searches that do not terminate internally, such as random descent, at least one stop criterion should be specified to ensure termination. For other searches such as steepest descent, external stop criteria are optional.
A search has a specific status at every point in time, as defined by the SearchType enumeration. The status can be IDLE, INITIALIZING, RUNNING, TERMINATING or DISPOSED. A search is IDLE when it has just been created or after it has completed a search run. When a search is started, it first goes to status INITIALIZING and then RUNNING. When an active search is requested to stop, its status changes to TERMINATING and the search will stop when the current step is complete, after which its status will go back to IDLE. An idle search may be (re)started, or it may be disposed upon which all of its resources are released and the search goes to status DISPOSED. After being disposed, a search can not be restarted. More details about the lifecycle of a search are available here.
A neighbourhood search uses one or more neighbourhoods to generate moves that are applied to the current solution in an attempt to improve it. Such neighbourhoods are defined by the Neighbourhood interface. They are capable of generating a random move or a set of all possible moves that modify a given solution into a similar, neighbouring solution. A Move can be applied to a solution to transform it into the corresponding neighbour and can also be undone to go back to the current solution.
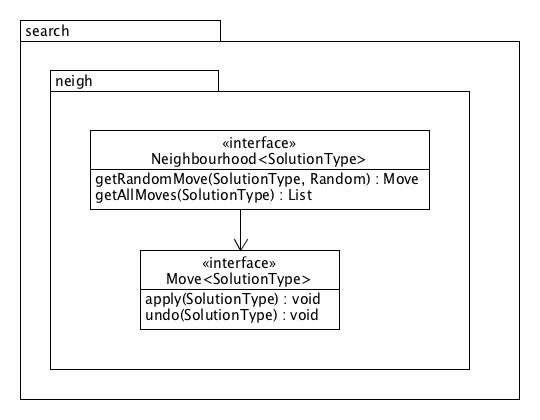
The UML diagram below shows some more details of the search components. In addition to the public methods introduced before, some protected methods of Search, LocalSearch and NeighbourhoodSearch are also shown here. These can be called from within the implementation of a specific search, for example to evaluate or validate considered moves and to update the current or best solution.
The protected methods searchStarted(), searchStopped() and searchDisposed() are executed when the search is started, has terminated or is being disposed, respectively. When starting a search, searchStarted() first calls the public method init() to initialize and/or validate the search, after which it (re)sets all per run metadata such as the execution time and step count. The default implementation of init() is empty but it may be overridden in a specific search. For example, a local search generates its default random initial solution when calling init(). Note that a search may also be manually initialized prior to execution, so it is important to take into account that init() may be called multiple times, for example by performing computationally demanding initializations only once upon the first call. When a search has terminated, searchStopped() finalizes the execution time. The default implementation of searchDisposed() is empty. All methods can be overridden to control the lifecycle of a specific search.
The searchStep() method is the only abstract method of a search. This method is repeatedly called during a search run, until the search is requested to stop or comes to its natural end. Every specific algorithm implements it according to its own search strategy. Some searches might consist of a single step only, and terminate when this step is complete. Other searches might repeatedly perform actions in a series of steps, such as neighbourhood searches which repeatedly modify the current solution by applying moves generated by a neighbourhood.
The diagram also lists several specific stop criteria that can be attached to a search:
- maximum runtime
- maximum number of steps
- maximum time without improvement
- maximum steps without improvement
- minimum delta (amount of improvement between consecutive best known solutions)
Note that the metadata that corresponds to these stop criteria applies to the current search run only (see search lifecycle). Every search has an internal StopCriterionChecker which periodically checks the stop criteria while the search is running and requests the search to stop as soon as one of the stop criteria is satisfied. In addition, stop conditions are checked after every search step.
The core module of JAMES contains specific components for subset selection. These are introduced here. Similar components for other types of problems can easily be added.
To use the provided components it is required that every item in the data set is identified using a unique integer ID. Any subset selection problem is then translated into selection of a subset of these IDs. The data set provides the link between IDs and (properties of) the corresponding items, which are for example used by the objective and constraints to evaluate and validate a selected subset.
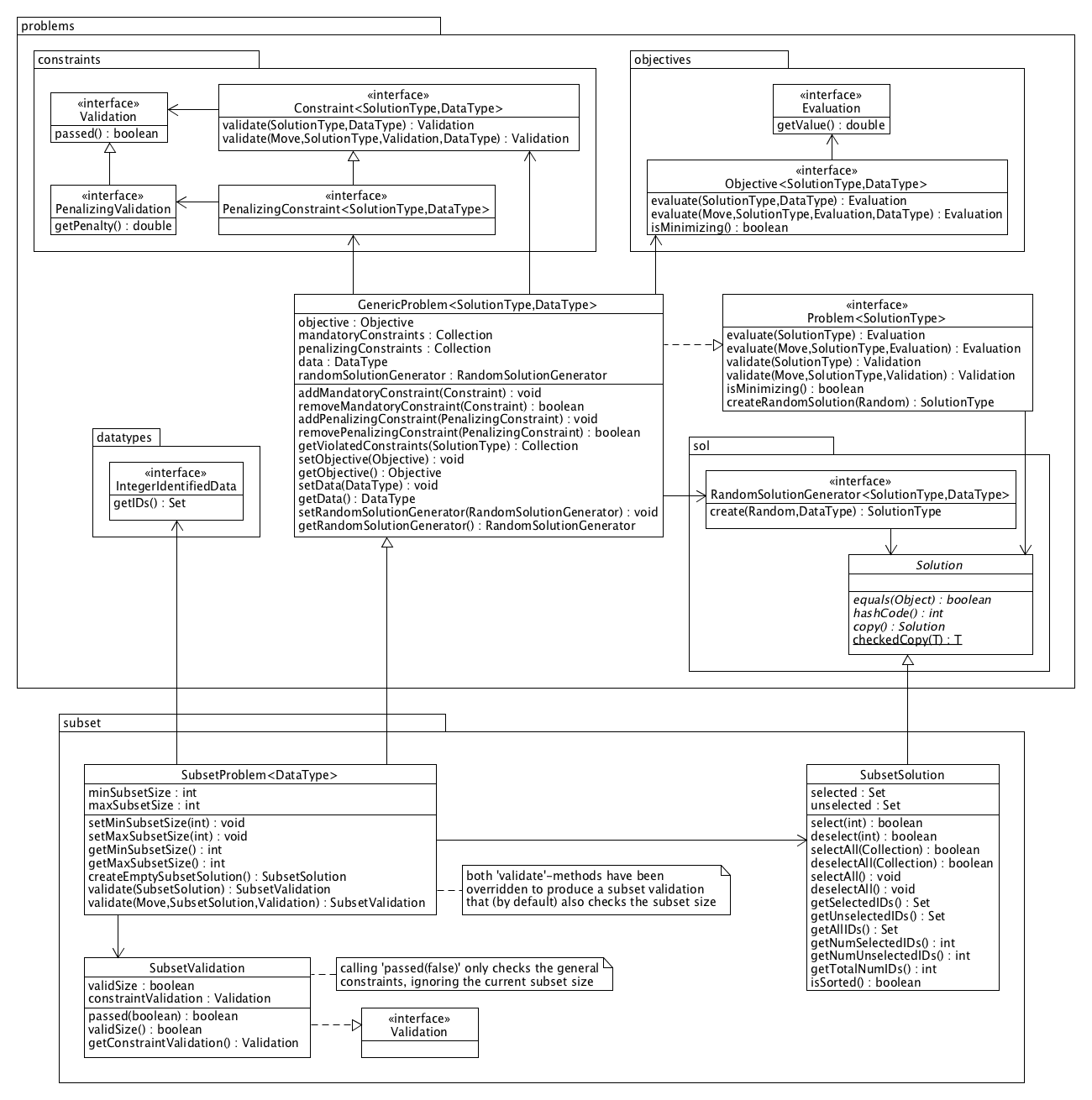
A predefined SubsetProblem is provided, which is an extension of the general GenericProblem. This predefined class has a built-in default random subset solution generator. Specific subset selection problems can be defined by plugging in data, an objective and possibly some constraints in a SubsetProblem instance, and specifying the minimum and maximum (or fixed) subset size if applicable.
The solution type of a subset problem is fixed to the predefined type SubsetSolution. Such subset solution models the set of currently selected and unselected IDs. A subset problem is able to generate random or empty subset solutions and can evaluate and validate any given subset solution, relying on the objective, constraints and underlying data.
A subset problem has data type IntegerIdentifiedData. The data class corresponding to any selection problem, e.g. MyData, should be provided by implementing this interface. It contains a single method getIDs() that returns the set of all assigned IDs. The problem needs to know these IDs, e.g. to generate a random subset. In addition to this required method getIDs() the data may contain any other custom methods used to access (properties of) selected items based on their IDs.
The objective and constraints of a subset selection problem should have solution type SubsetSolution and data type MyData. Given a subset solution, the currently selected IDs can be retrieved and the data can be accessed to evaluate or validate the solution. As the data type is set to MyData all custom methods are also available when implementing the objective and constraints.
The core module contains several subset neighbourhoods that generate moves to modify the set of selected IDs by adding, deleting or swapping some IDs. These neighbourhoods can be used for any subset selection problem.
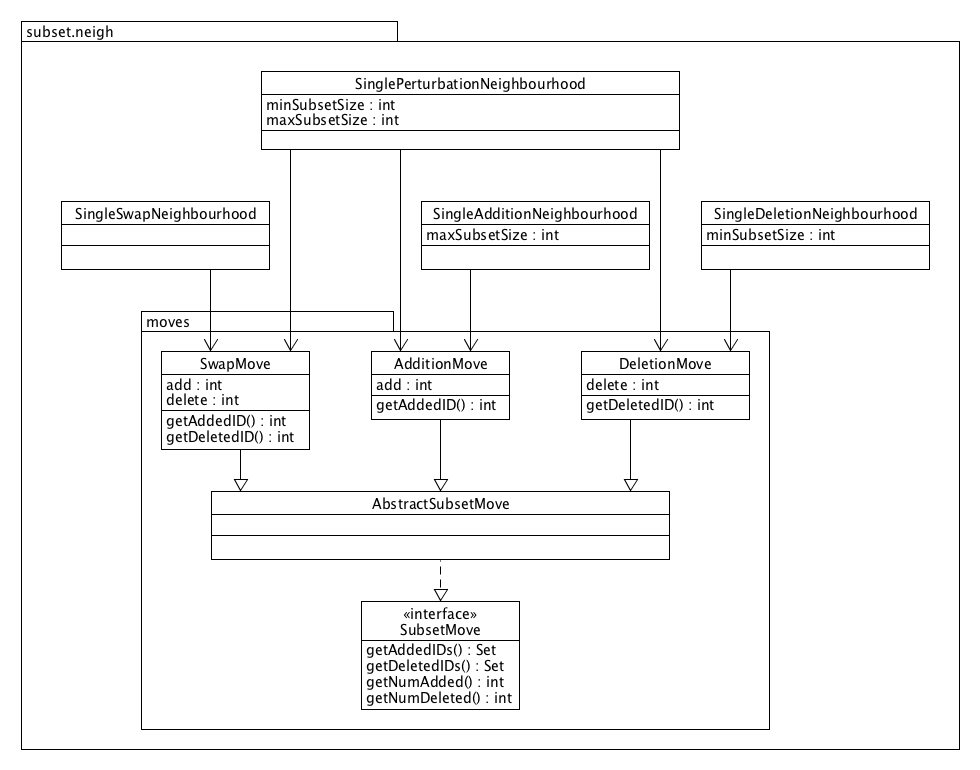
The basic neighbourhoods always add and/or remove a single ID only. The two most frequently used neighbourhoods are:
-
The SingleSwapNeighbourhood which generates moves that remove an ID from the set of selected IDs and replace it with an other ID which is currently not selected. This operation is referred to as a swap. With this neighbourhood subset solutions will always remain of the same size.
-
The SinglePerturbationNeighbourhood which adds and/or deletes an ID to/from the selection. This neighbourhood contains the single swap neighbourhood but is also suited for variable size subset selection. A minimum and maximum subset size should be specified and the neighbourhood will never generate moves that violate these bounds. If the subset size is fixed, i.e. if the minimum and maximum size are equal, it is advised to use the single swap neighbourhood instead, which has been optimized for this case.
A SingleAdditionNeighbourhood and SingleDeletionNeighbourhood are also provided, which generate moves that add or remove a single ID to/from the selection, respectively. These are unidirectional neighbourhoods: the size of the selection always increases or always decreases, respectively. Such neighbourhoods can for example be useful to perform greedy searches (e.g. in combination with a steepest descent search).
Several advanced, larger neighbourhoods are also provided which perform multiple swaps, additions or deletions in a single move. These larger neighbourhoods might aid in escaping from local optima, but also have a clear disadvantage: they significantly increase the computational cost of finding the best move, if applicable, and may decrease the probability of obtaining a good neighbour when sampling a random move.
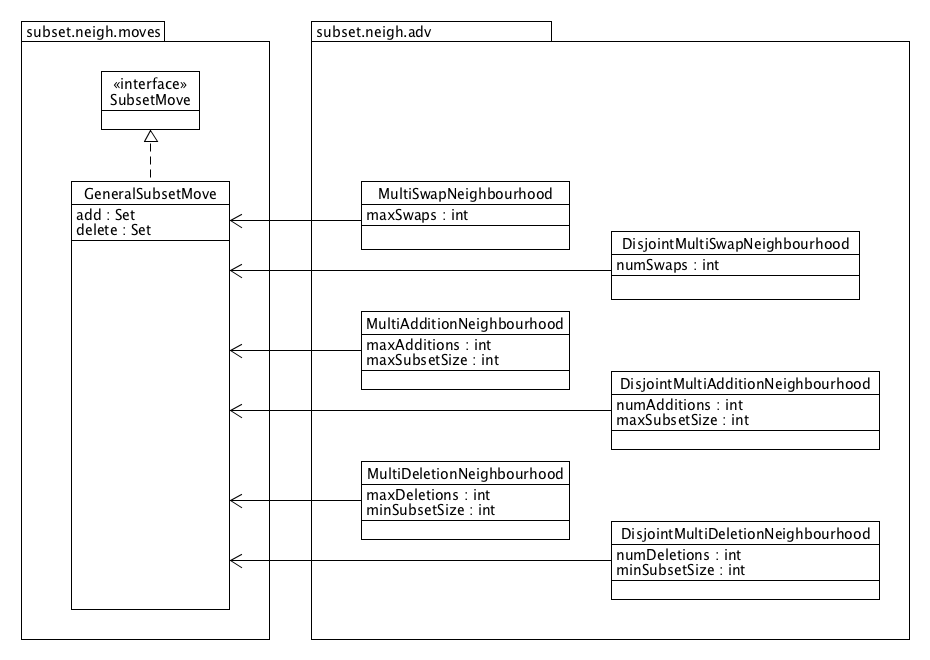
Two advanced subset neighbourhoods are suited for fixed size subset selection:
-
The MultiSwapNeighbourhood which generates moves that simultaneously swap 1 up to k IDs. The maximum number of swaps k is specified when creating the neighbourhood.
-
The DisjointMultiSwapNeighbourhood which is similar to the multi swap neighbourhood, with one important difference: it generates moves that always perform a fixed number of k swaps, so that neighbourhoods of different sizes are disjoint.
Similarly, four unidirectional neighbourhoods are provided which generate moves that perform a fixed or variable number of additions ([Disjoint]MultiAdditionNeighbourhood) or deletions ([Disjoint]MultiDeletionNeighbourhood). These may for example serve as shaking neighbourhoods in a variable neighbourhood search.
Note that for these larger neighbourhoods the number of possible moves quickly increases in case of a larger data set and/or selected subset size. For example, when sampling 30 items out of 100 candidates the number of possible single swaps is 2100 (= 30*(100-30)) while there are already more than a million possibilities when considering all combinations of 2 swaps. Therefore, these advanced neighbourhoods should be used with care for larger problems, especially in combination with searches that generate all moves in every step (such as steepest descent and tabu search).
Of course, it is not always possible (or desired) to use one of the available subset neighbourhoods for a specific subset selection problem. In such case, a custom neighbourhood can be provided by implementing the Neighbourhood interface with solution type SubsetSolution. Given a subset solution, this custom neighbourhood may generate any AdditionMove, DeletionMove, SwapMove or GeneralSubsetMove to modify the solution.
A wide range of generic optimization algorithms are provided in the JAMES framework, among which many neighbourhood searches. For a description of all available algorithms, we refer to the James website.