This repo contains the official code for the following paper:
Hakaze Cho, et al. "Binary Autoencoder for Mechanistic Interpretability of Large Language Models." 2025.
Implemented by Hakaze Cho, the primary contributor of the paper.
Existing works are dedicated to untangling atomized numerical components (features) from the hidden states of Large Language Models (LLMs) for interpreting their mechanism. However, they typically rely on autoencoders constrained by some implicit training-time regularization on single training instances (i.e., normalization, top-k function, etc.), without an explicit guarantee of global sparsity among instances, causing a large amount of dense (simultaneously inactive) features, harming the feature sparsity and atomization. In this paper, we propose a novel autoencoder variant that enforces minimal entropy on minibatches of hidden activations, thereby promoting feature independence and sparsity across instances. For efficient entropy calculation, we discretize the hidden activations to 1-bit via a step function and apply gradient estimation to enable backpropagation, so that we term it as Binary Autoencoder (BAE) and empirically demonstrate two major applications: (1) Feature set entropy calculation. Entropy can be reliably estimated on binary hidden activations, which we empirically evaluate and leverage to characterize the inference dynamics of LLMs and In-context Learning. (2) Feature untangling. Similar to typical methods, BAE can extract atomized features from LLM's hidden states. To robustly evaluate such feature extraction capability, we refine traditional feature-interpretation methods to avoid unreliable handling of numerical tokens, and show that BAE avoids dense features while producing the largest number of interpretable ones among baselines, which confirms the effectiveness of BAE serving as a feature extractor.
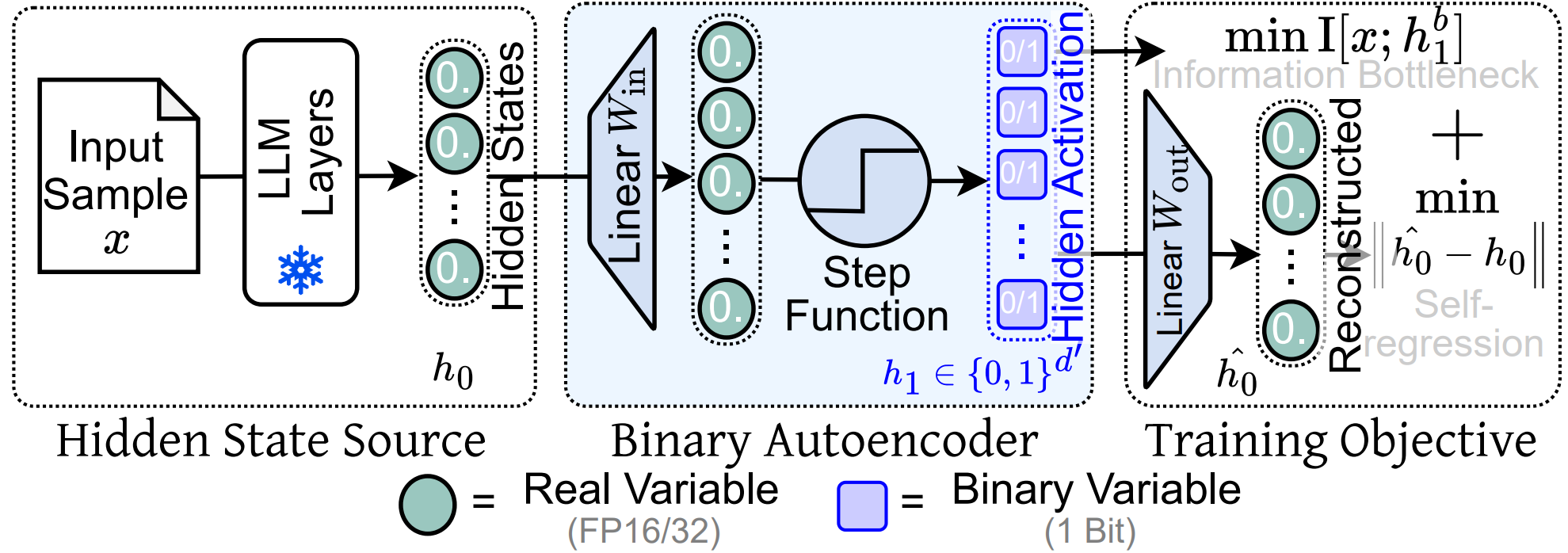
Feed-forward computation and training objective of BAE. Hidden states
- A GPU with more than 40GB VRAM and CUDA (Ver.
12.4recommended) are strongly required to run all the experiments. - Network connection to
huggingfaceis needed to download the pre-trained model. And ahuggingfaceuser token with access to theLlama Familymodel is recommended to run a part of the experiments. A OpenAI API key is also needed to run the interpretation experiments. AnacondaorMinicondais needed.
git clone https://github.com/hc495/Binary_Autoencoder.git
cd Binary_Autoencoderconda env create -f environment.yaml
conda activate binary_autoencoderThe file feature_reconstruction.py contains the code to train BAE on feature sets extracted from LLMs. Below are the details of command line arguments and an example of standard usage.
| Argument | Type | Default | Description |
|---|---|---|---|
--feature_path |
str | required | Path to the feature set. Should be a .pkl file containing either a list-like of torch.Tensor(dim) or a list of list-like torch.Tensor(dim). |
--layered_feature |
flag | False | Whether the feature set is layered. If set, feature_path should point to a list of list-like torch.Tensor(dim). Otherwise, it should point to a list-like torch.Tensor(dim). |
--layer |
int | -1 | Layer index for the feature set. Used only if --layered_feature is set. |
--inner_expand_rate |
int | 4 | Inner expand rate for the autoencoder. |
--binarization_type |
str | 'sign_s' | Binarization type for the autoencoder: 'sign', 'sign_s', or 'squarewave'. |
--cycle_for_squarewave |
int | 2 | Cycle parameter for squarewave binarization. |
--output_activation |
str | 'none' | Output activation function for the autoencoder: 'none', 'sigmoid', 'tanh', or 'relu'. |
--bias |
flag | False | Whether to use bias in the autoencoder. |
--cuda |
flag | False | Use CUDA for training. |
--dataset_split |
float | 0.8 | Split ratio for training and validation datasets. |
--lr |
float | 1e-3 | Learning rate for the optimizer. |
--weight_decay |
float | 0 | Weight decay for the optimizer. |
--batch_size |
int | 512 | Batch size for training. |
--num_epochs |
int | 3500 | Number of epochs for training. |
--entropy_weight |
float | 0e-8 | Weight for the entropy loss. |
--covarience_weight |
float | 0e-8 | Weight for the covariance loss. |
--entropy_threshold |
float | 0 | Threshold for the entropy loss. |
--entropy_start_epoch |
int | 500 | Epoch to start applying the entropy loss. |
--save_dir |
str | 'logs' | Directory to save the results (logs, model, plots). |
--dont_save_model |
flag | False | Do not save the model after training. |
--dont_save_log |
flag | False | Do not save the log after training. |
Train BAE on the feature set located at feature.pkl for layer index layer, and save the results to logs/:
python feature_reconstruction.py \
--feature_path "feature.pkl" \
--cuda \
--layered_feature \
--layer $layer \
--lr 5e-4 \
--inner_expand_rate 4 \
--num_epochs 2000 \
--bias \
--covarience_weight 1e-7 \
--entropy_weight 1e-7 \
--binarization_type "sign_s" \
--save_dir "logs/" The file feature_reconstruction_SAE.py contains the code to train baseline autoencoders on feature sets extracted from LLMs. Below are the details of command line arguments and an example of standard usage.
| Argument | Type | Default | Description |
|---|---|---|---|
--feature_path |
str | required | Path to the feature set. Should be a .pkl file containing either a list-like of torch.Tensor(dim) or a list of list-like torch.Tensor(dim). |
--MLP_input_path |
str | None | Path to the MLP input feature set, format same as --feature_path. If given, train TransCoder. |
--layered_feature |
flag | False | Whether the feature set is layered. |
--layer |
int | -1 | Layer index for the feature set. Used only if --layered_feature is set. |
--inner_expand_rate |
int | 4 | Inner expand rate for the autoencoder. |
--inner_activation |
str | 'none' | Inner activation function for the autoencoder: 'none', 'sigmoid', 'tanh', 'relu', 'jumprelu', or 'topk'. |
--topk |
int | 10 | Top k features to consider for the inner activation function if 'topk' is selected. |
--theta |
float | 0.5 | Threshold for the 'jumprelu' activation function. |
--output_activation |
str | 'none' | Output activation function for the autoencoder: 'none', 'sigmoid', 'tanh', or 'relu'. |
--bias |
flag | False | Whether to use bias in the autoencoder. |
--cuda |
flag | False | Use CUDA for training. |
--dataset_split |
float | 0.8 | Split ratio for training and validation datasets. |
--lr |
float | 1e-3 | Learning rate for the optimizer. |
--weight_decay |
float | 0 | Weight decay for the optimizer. |
--batch_size |
int | 512 | Batch size for training. |
--num_epochs |
int | 3500 | Number of epochs for training. |
--l1_norm_weight |
float | 0.0 | Weight for the L1 norm regularization. |
--l1_start_epoch |
int | 0 | Epoch to start applying L1 norm regularization. |
--save_dir |
str | 'logs' | Directory to save the results (logs, model, plots). |
--dont_save_model |
flag | False | Do not save the model after training. |
--dont_save_log |
flag | False | Do not save the log after training. |
Train a TransCoder:
python feature_reconstruction_SAE.py \
--feature_path "experiment_matrial/feature_pile_Llama3_3B_20L/features_Llama3_3B_all.pkl" \
--MLP_input_path "experiment_matrial/feature_pile_Llama3_3B_20L_mlp_inputs/features_Llama3.2_3B_all.pkl" \
--cuda \
--lr 5e-4 \
--inner_expand_rate 4 \
--num_epochs 200 \
--l1_start_epoch 50 \
--bias \
--l1_norm_weight 1e-7 \
--save_dir "logs/pile_llama3_3B_layer20_TransCoder/" The file evaluate_interp.py contains the code to interpret and evaluate the features by ComSem extracted by BAE and baselines. Below are the details of command line arguments and an example of standard usage.
| Argument | Type | Default | Description |
|---|---|---|---|
--dataset_name |
str | 'bookcorpus' | Name of the dataset to load. |
--split |
str | 'train' | Split of the dataset to load. |
--sample_size |
int | 8192 | Number of samples to print from the dataset. |
--LM_name |
str | 'meta-llama/Llama-3.2-1B' | Name of the language model to use. |
--layer |
int | 11 | Layer of the language model to use for feature extraction. |
--backend_model_name |
str | 'gpt-4.1-mini' | Name of the backend model for interpretation. |
--BAE_path |
str | None | Path to the Binary Autoencoder model / SAE model / TransCoder model. |
--type |
str | 'BAE' | Type of the model to use for feature extraction: 'BAE', 'SAE', 'TRC', or 'random'. |
--config_path |
str | None | Path to the configuration file for the Binary Autoencoder / SAE / TransCoder. Automatically generated during training. |
--top_k |
int | 10 | Top k features to consider for interpretation. |
--openai_token |
str | None | OpenAI API key for using the backend model. |
--save_path |
str | 'logs/interp_score_results/' | Path to save the interpretation results. |
--no_interpret |
flag | False | Do not run the interpretation process. |
--SAE_rescale |
flag | False | Use the SAE baseline with rescaling. |
Interpret features extracted by a BAE model located at model.pt with configuration file config.pkl:
python evaluate_interp.py
--type BAE \
--BAE_path model.pt \
--config_path config.pkl \
--save_path logs/interp_score_results_BAE_layer5_redo/ \
--layer 5 \
--backend_model_name "gpt-4.1-mini"You should write the configuration file manually, and dump it as a .pkl file to tell the code to build the BAE/SAE. Below is an example of how to create the configuration file:
{
"inner_expand_rate": 4,
"binarization_type": "sign_s",
"output_activation": "none",
"cycle_for_squarewave": None,
}If you find this work useful for your research, please cite our paper:
@article{cho2025binary,
title={Binary Autoencoder for Mechanistic Interpretability of Large Language Models},
author={Cho, Hakaze and Yang, Haolin and Kurkoski, Brian M. and Inoue, Naoya},
journal={arXiv preprint arXiv:2509.20997},
year={2025}
}