Цель проекта: разработать конвеер машинного обучения data-продукта (Web или API приложение). Команда проекта. Проект выполняется в команде из 3-4 человека.
Требования к реализации проекта:
Исходные коды проекта должны находиться в репозитории GitHub. Проект оркестируется с помощью ci/cd (jenkins или gitlab). Датасеты версионируются с помощью dvc и синхронизируются с удалённым хранилищем. Разработка возможностей приложения должна проводиться в отдельных ветках, наборы фичей и версии данных тоже. В коневеере запускаются не только модульные тесты, но и проверка тестами на качество данных. Итоговое приложение реализуется в виде образа docker. Сборка образа происходит в конвеере. В проекте может использоваться предварительно обученная модель. Обучать собственную модель не требуется.
В этом проекте используются предварительно обученные модели ResNet-50 для классификации изображений. В репозитории предоставлены веса для моделей, обученных на датасетах CIFAR-10 и CIFAR-100.
Для обучения и тестирования моделей используются датасеты CIFAR-10 и CIFAR-100, которые представляют собой наборы изображений, разделенные на 10 и 100 классов соответственно.
Details
# Pipeline Jenkins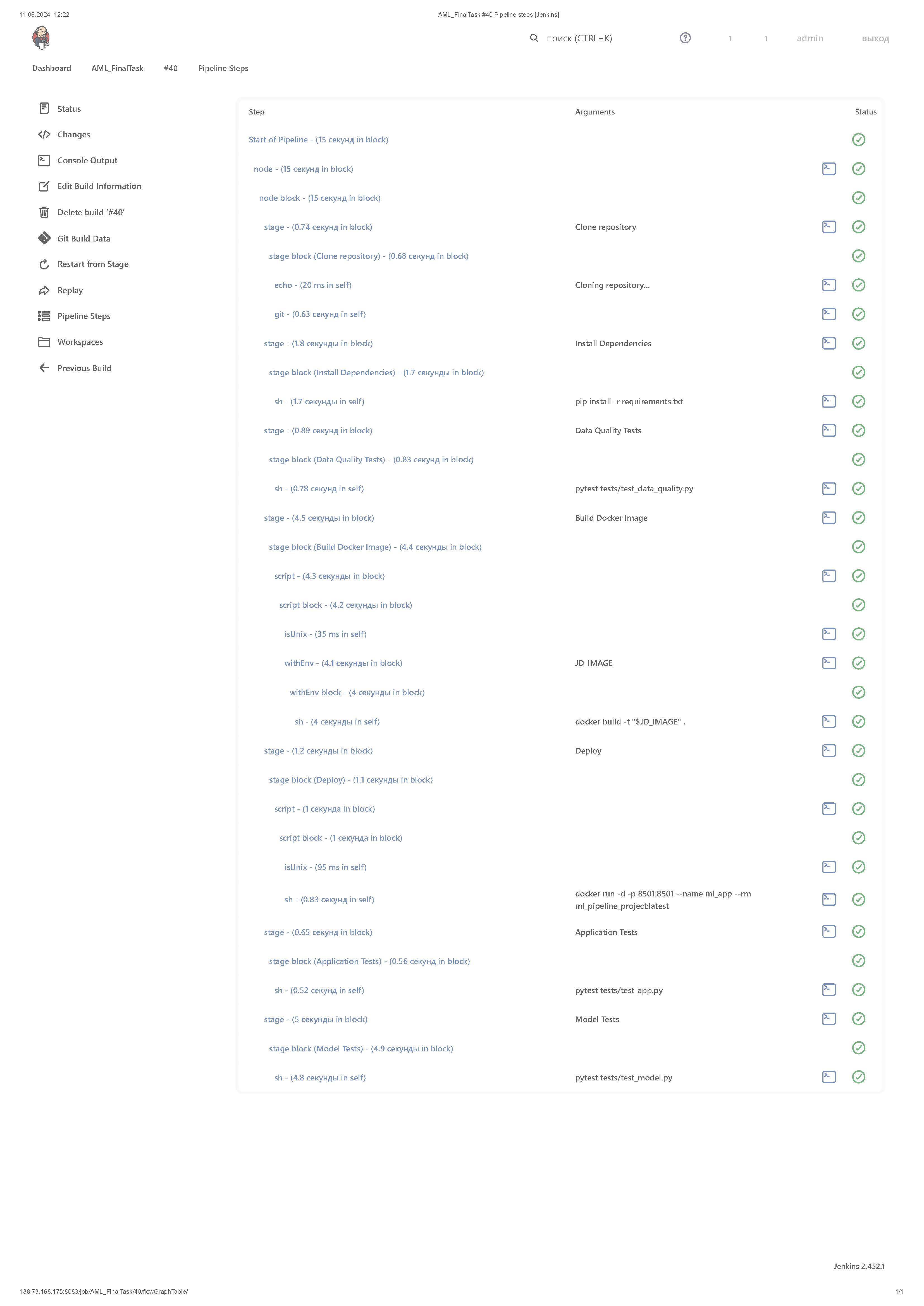
- Склонируйте репозиторий:
git clone https://github.com/grubnev/AML_FinalTask.git
- Установите зависимости:
pip install -r requirements.txt
- Запустите веб-приложение:
streamlit run app.py