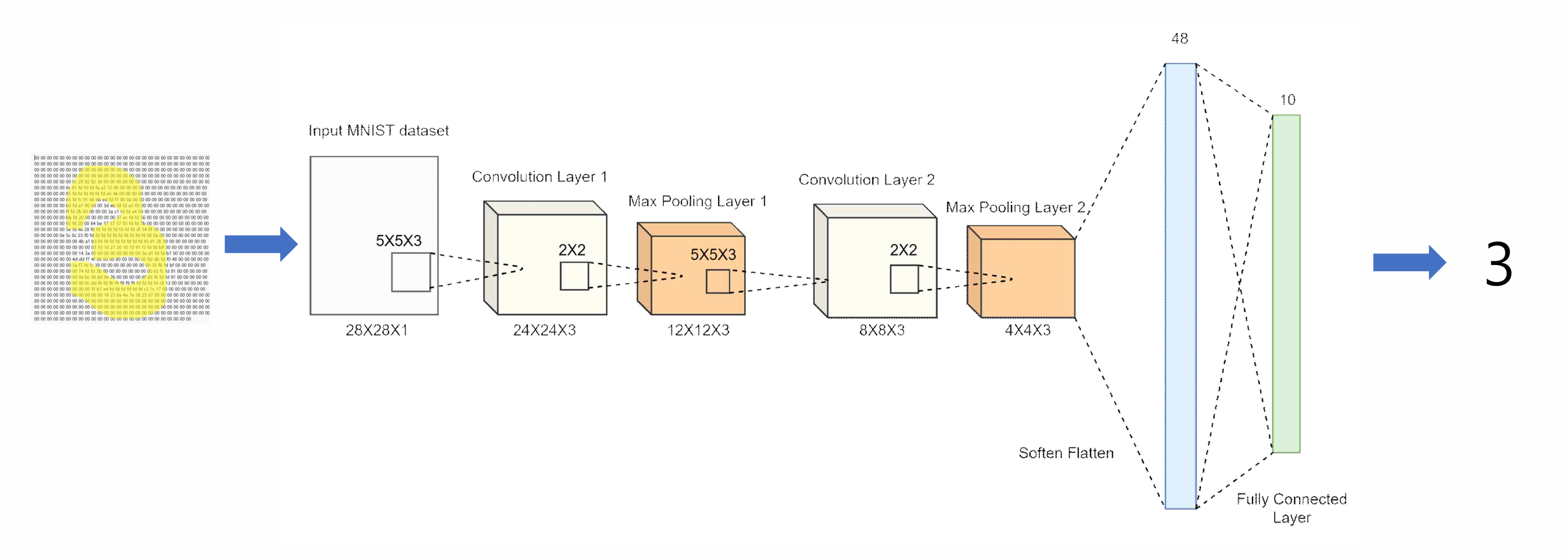
Target Model Structure The CNN model used in this accelerator design is optimized for MNIST digit classification. It consists of convolutional layers followed by ReLU, MaxPooling, and a fully connected (FC) layer. This model was selected to balance accuracy and hardware efficiency, making it ideal for FPGA and ASIC deployment.
- Development Tool: Xilinx Vivado Design Suite
- Target Board: Zynq-7000 SoC (Zynq Z7-20)
- Simulation & Co-Verification: Vivado Simulator, MATLAB
- Host Communication: Xilinx SDK (for UART terminal output and testing)
- Programming Language: Verilog HDL
The project was developed, synthesized, and verified using Vivado targeting the Zynq Z7-20 board, a popular platform combining ARM processing with programmable logic. MATLAB was used for high-level simulation and verification.
- MNIST CNN Accelerator Design
- MNIST CNN Accelerator Design
This project focuses on designing a low-power CNN accelerator tailored for the MNIST dataset. By implementing efficient memory access and resource management techniques, the design minimizes power consumption while achieving high inference performance.
Below is a simplified version of the overall system block diagram:
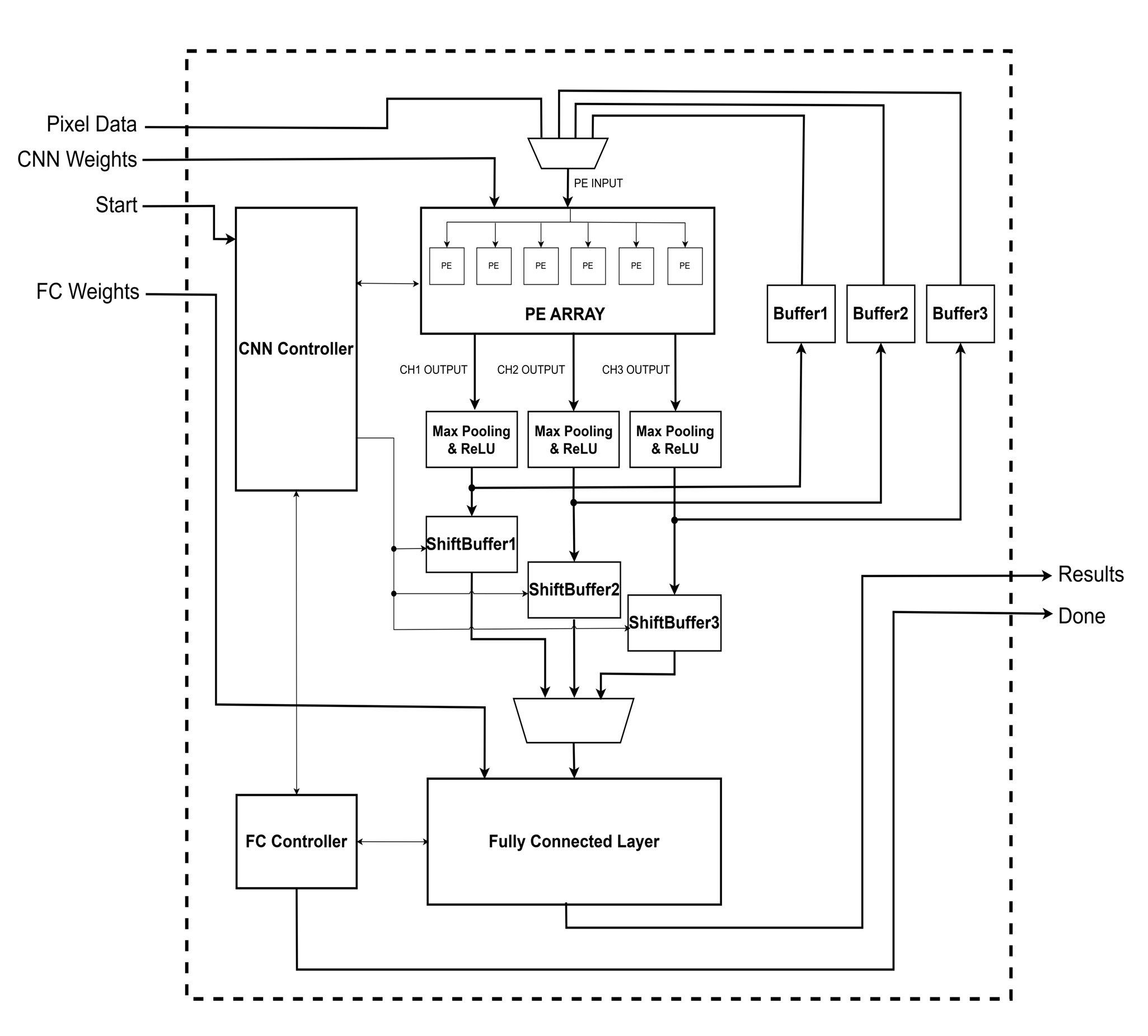
-
Memory Access Minimization in PE Array
To reduce power consumption, the design minimizes external memory access by efficiently utilizing on-chip buffers and PE arrays. -
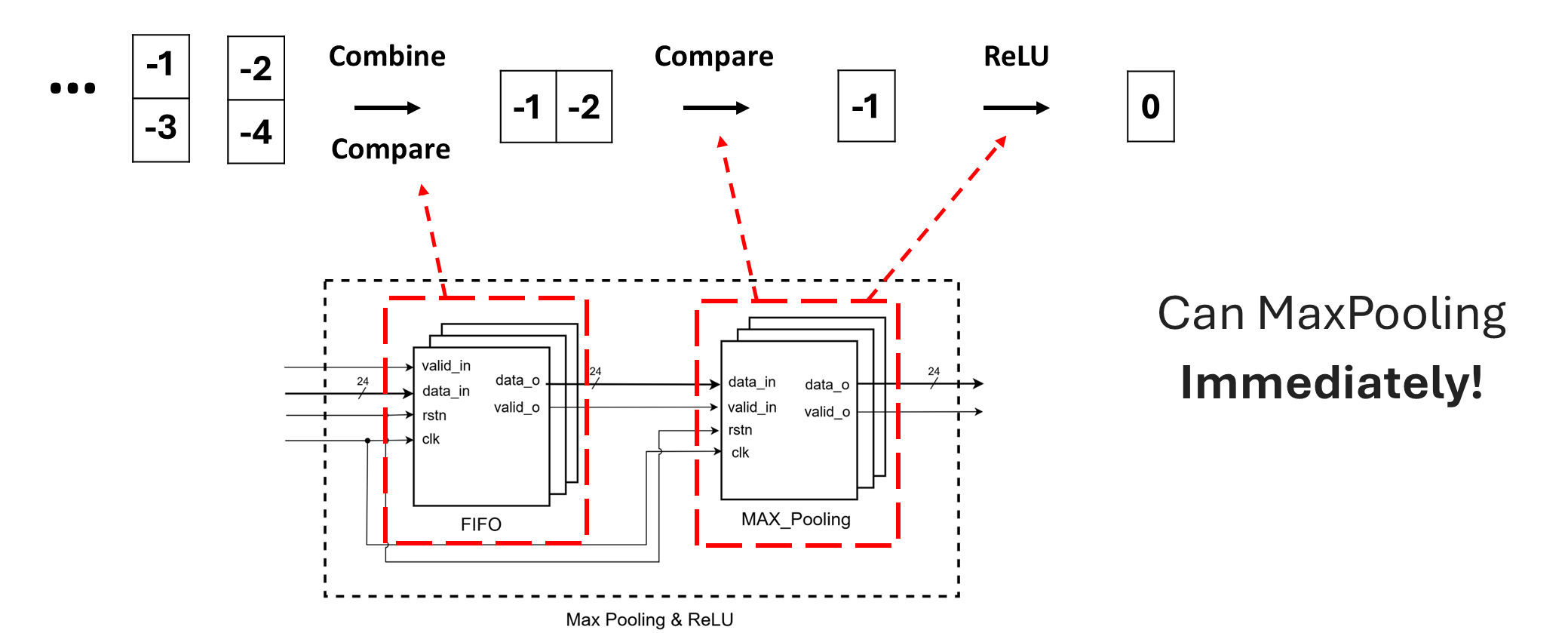
FIFO, MaxPooling, and ReLU Integration
A tightly coupled FIFO, MaxPooling, and ReLU module ensures streamlined data processing while maintaining flexibility for hardware optimization. -
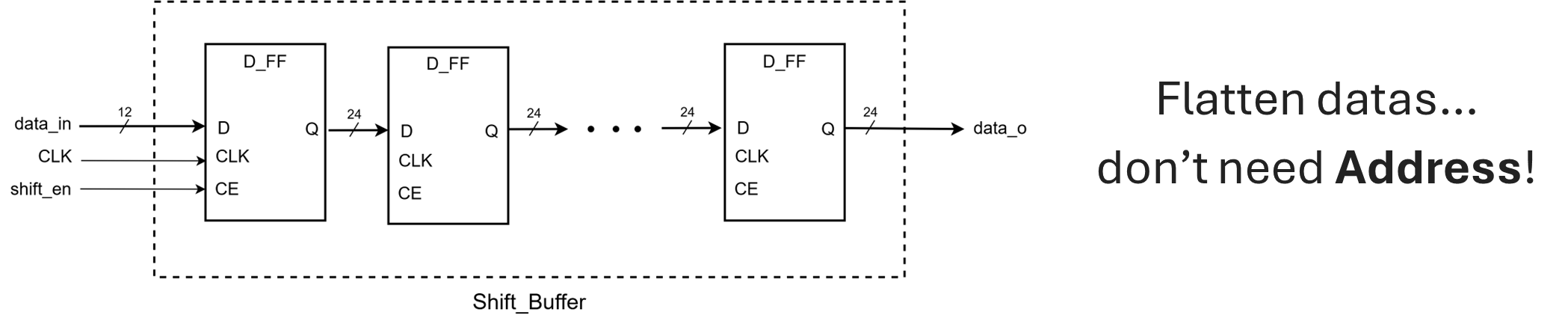
Shift Buffer Utilization
Shift buffers are used for managing input data in convolution operations, reducing redundant memory reads and improving computational efficiency. -
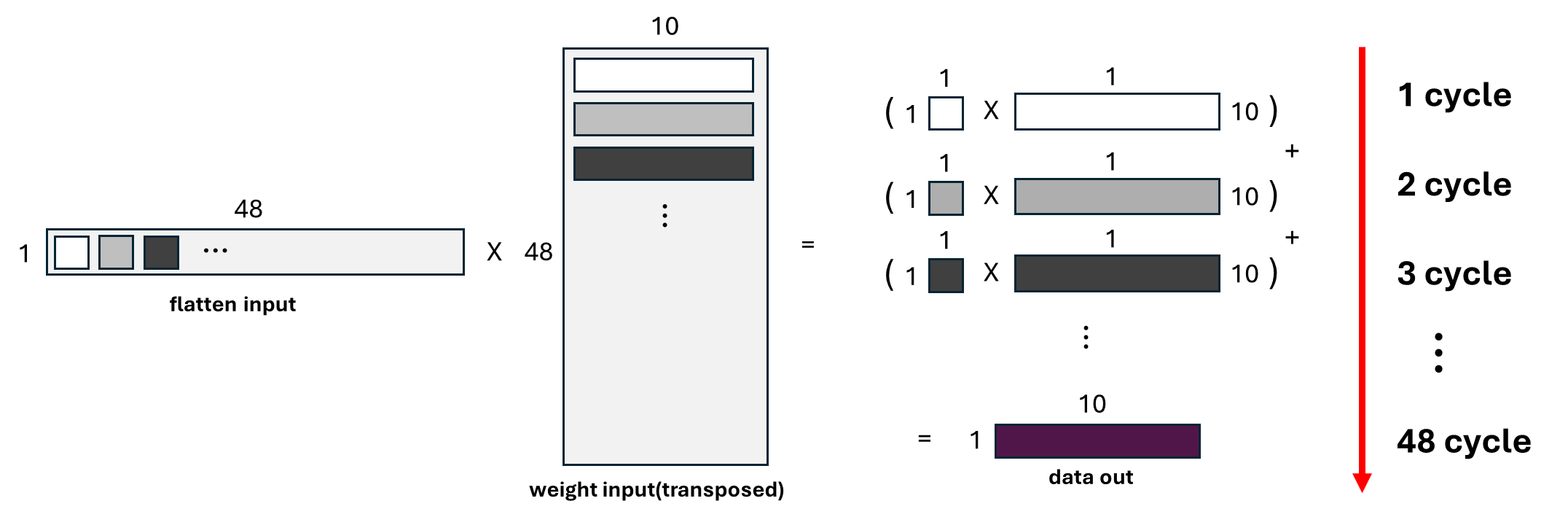
Fully Connected (FC) Layer Implementation
The FC layer is implemented with a dedicated computation module that leverages efficient resource allocation and parallelism.
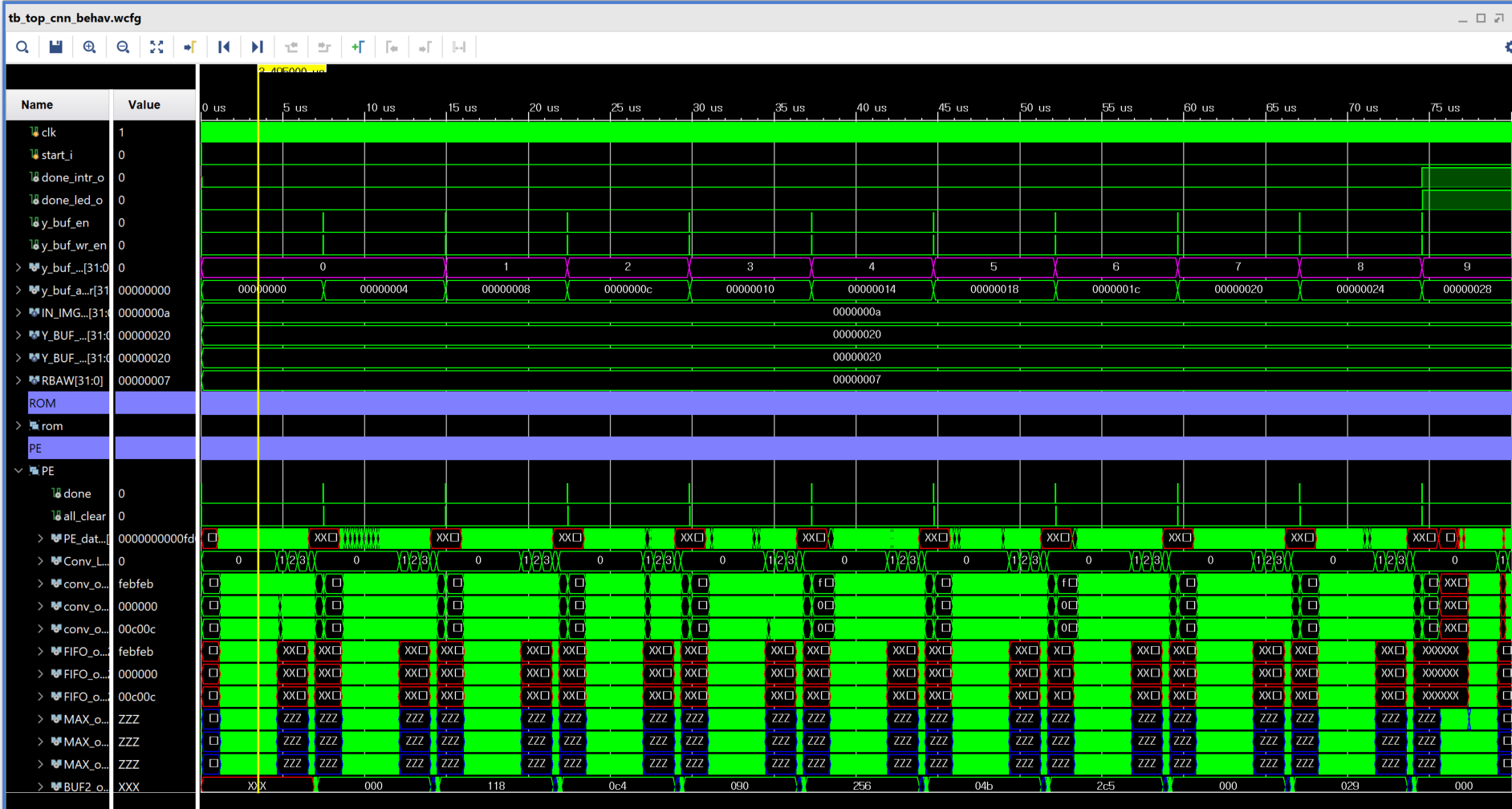
The accelerator achieves efficient inference on a single MNIST image with minimal latency.

The system demonstrates consistent performance when processing 1000 images, showcasing its scalability and robustness.
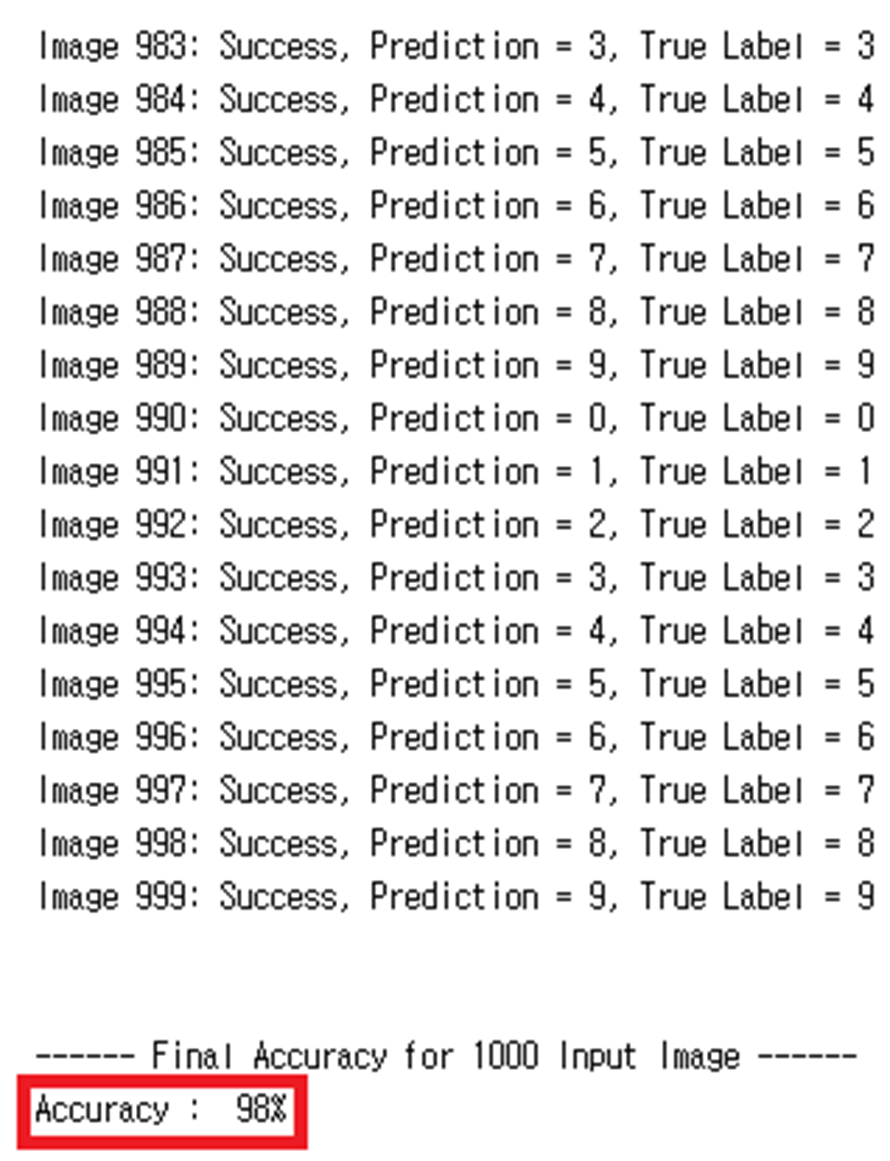
Note: The inference result for 1000 MNIST images and the associated waveform shown above were generated using behavioral simulation in Vivado during an ASIC design phase (e.g., competition submission). This test was not run on the FPGA hardware due to memory and interface limitations at the time of development. The GitHub repository contains the later FPGA implementation, which includes inference for 10 consecutive images tested via on-board UART.
The behavioral simulation used a dedicated testbench tb_top_1000.v, which loads the following files for testing:
$readmemh({{VIVADO_PROJECT_LOCATION},{"/data/input_1000.txt"}}, pixels);
$readmemh({{VIVADO_PROJECT_LOCATION},{"/data/labels_1000.txt"}}, true_labels);The file input_1000.txt is not flattened.
Each MNIST image is stored as 28 lines of 28 hexadecimal pixel values, representing a 2D 28×28 grayscale image in raster-scan order.
This format is handled in the testbench using logic such as:
image_6rows[i] <= {4'h0, pixels[(i + cycle * 2) * 28 + image_idx + img_offset]};If you're testing the design with these files, ensure the memory loading and indexing logic matches this format.
-
Low-Power Design
- Efficient memory access techniques (PE Array + Shift Buffers).
- Optimized control logic for idle-cycle reduction in processing elements.
-
Resource Utilization
- Reuse of FIFO buffers and PE arrays across multiple operations.
- Minimal external memory bandwidth usage through data locality exploitation.
-
Scalable Architecture
- Modular design supports easy extension to larger datasets or different model architectures.
- Lightweight implementation suitable for resource-constrained environments.
-
Hardware-Software Co-Design
- Integration of software control logic for flexible CNN model configuration.
- Custom AXI4 interface for seamless communication between hardware and software.
To evaluate the real-time performance of the CNN accelerator, the architecture was synthesized and implemented on an FPGA board. In contrast to the ASIC simulation with 1000 images, the FPGA version was tested with 10 consecutive MNIST images using on-board memory and interface logic.
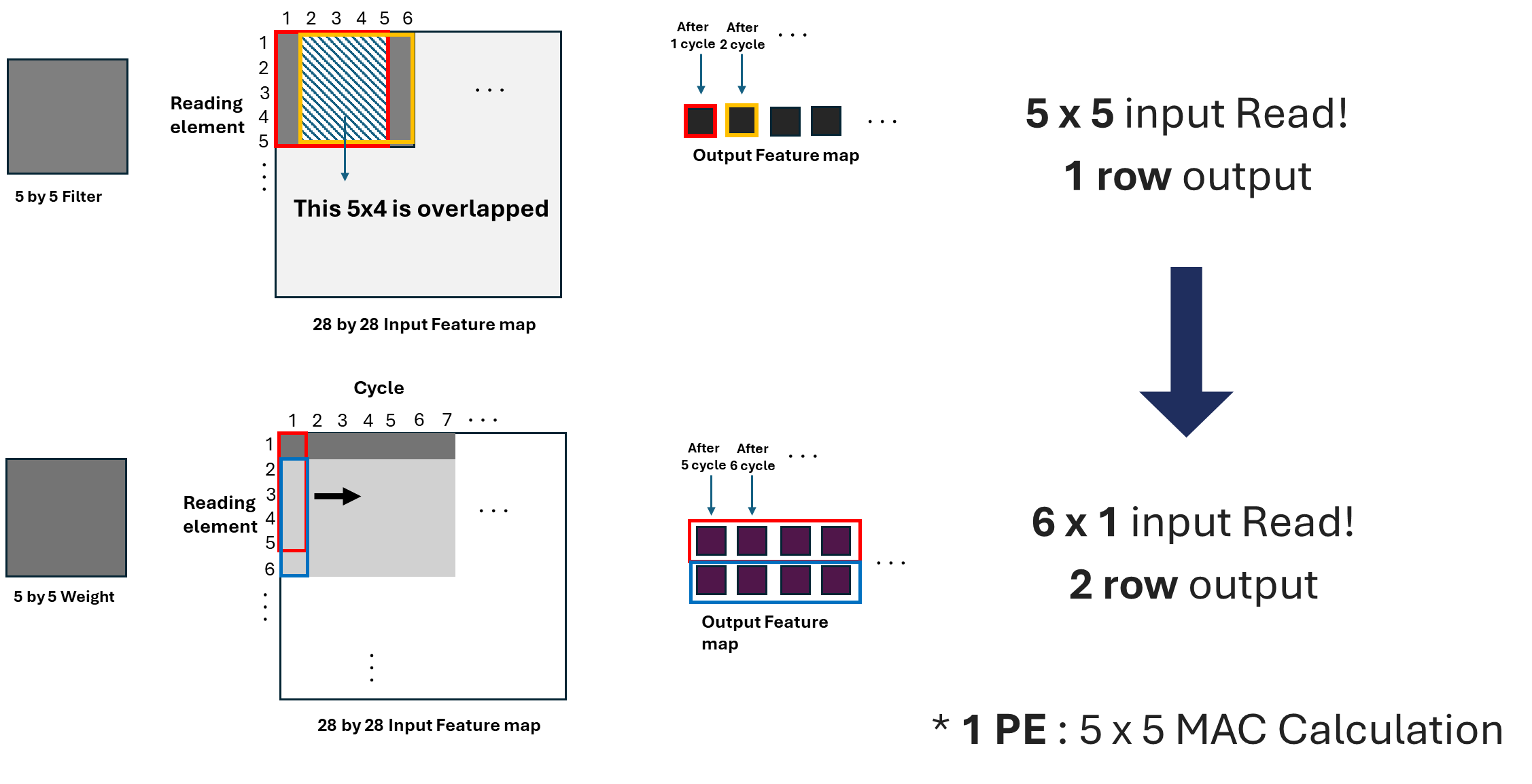
In the FPGA implementation, a custom Sliding_Window module was introduced to address the BRAM bandwidth bottleneck. Since dual-port BRAM allows only two pixels per cycle, a naive implementation would result in performance degradation. To overcome this, we pre-buffer incoming image data into a 6×28 sliding window buffer and enable seamless pixel streaming.
- Two pixels are fetched per cycle from BRAM.
- A 6-row buffer (
BUF_Slide) stores the active region of the image. - On every
slide_trigger, the buffer shifts upward by 2 rows, mimicking a sliding window effect. - The module delivers 6 rows of pixel data per column, used for convolution without delay.
// Sliding_Window module delivers a 6x1 column from buffered image data
// Enables continuous convolution with minimal latency
BUF_Slide[ROWS - 2][col] <= BUF_SHIFT[0][col];
BUF_Slide[ROWS - 1][col] <= BUF_SHIFT[1][col];This optimization significantly improves the throughput, enabling real-time inference with a continuous data feed into the convolution pipeline.
The hardware was also tested with MATLAB to verify end-to-end dataflow between host and FPGA. Images were streamed from MATLAB, and classification results were returned in real-time via serial communication.
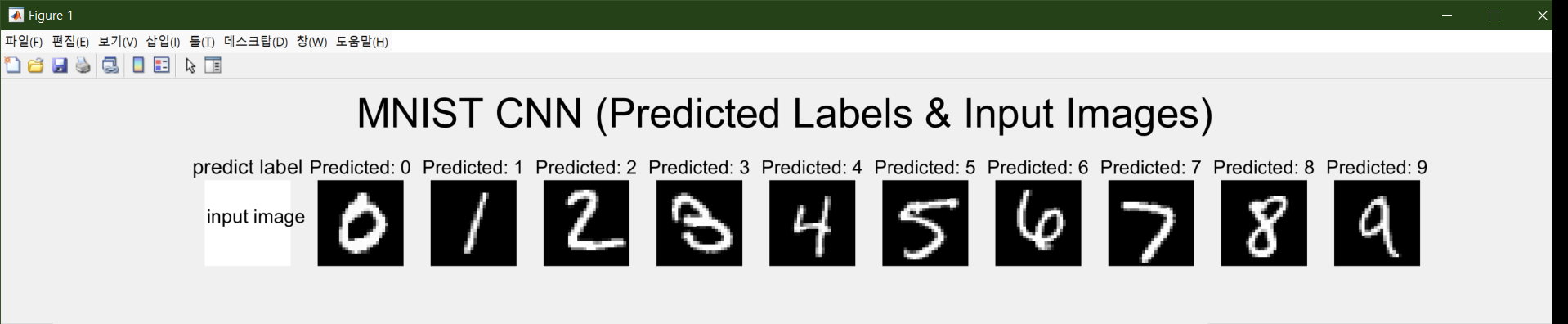
Functional correctness was confirmed through RTL simulation before hardware synthesis.
The design achieved successful implementation on Xilinx FPGA with timing closure and efficient resource usage.
-
Post-Implementation Block View
-
Timing Summary
-
Power Summary
-
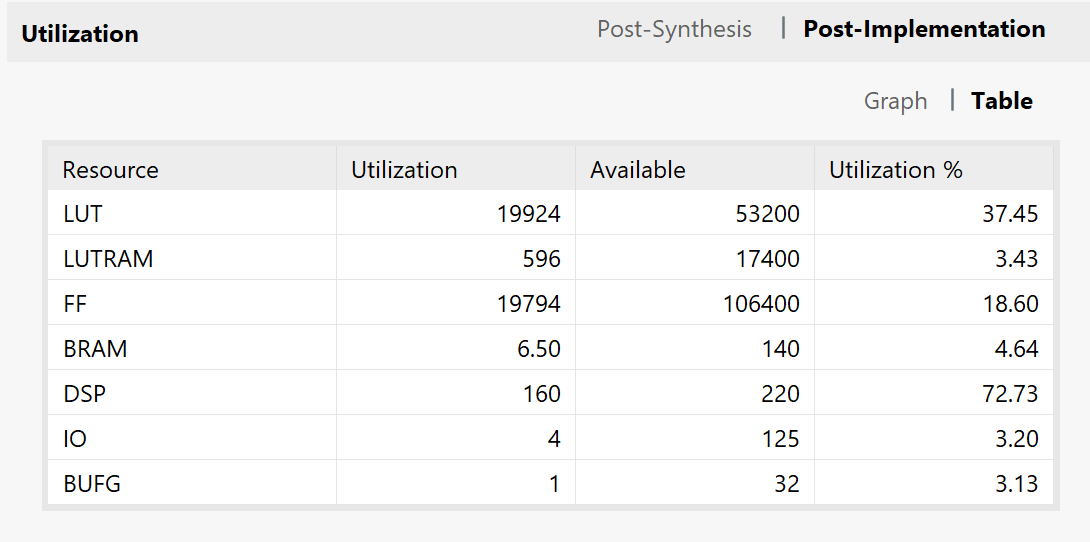
Resource Utilization
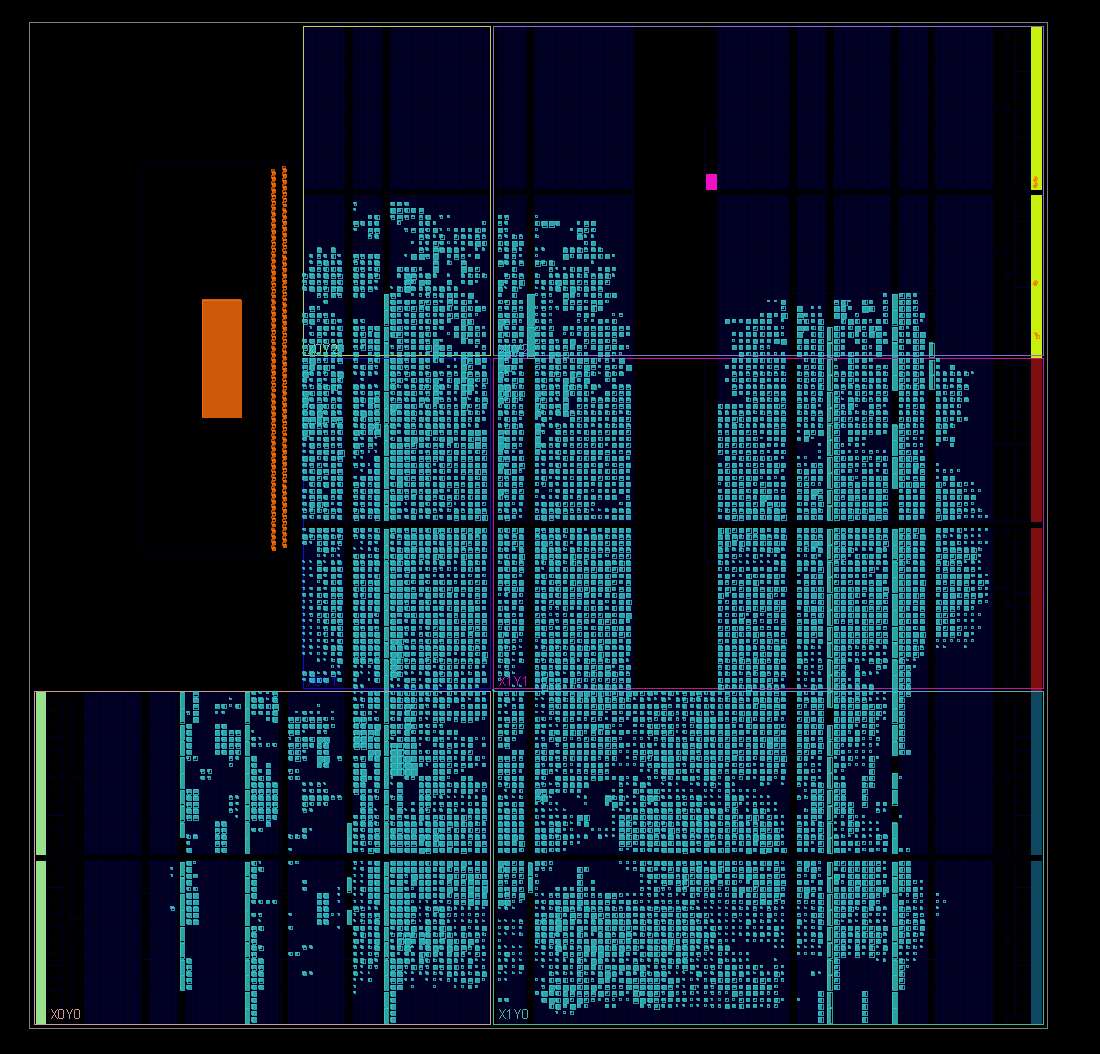

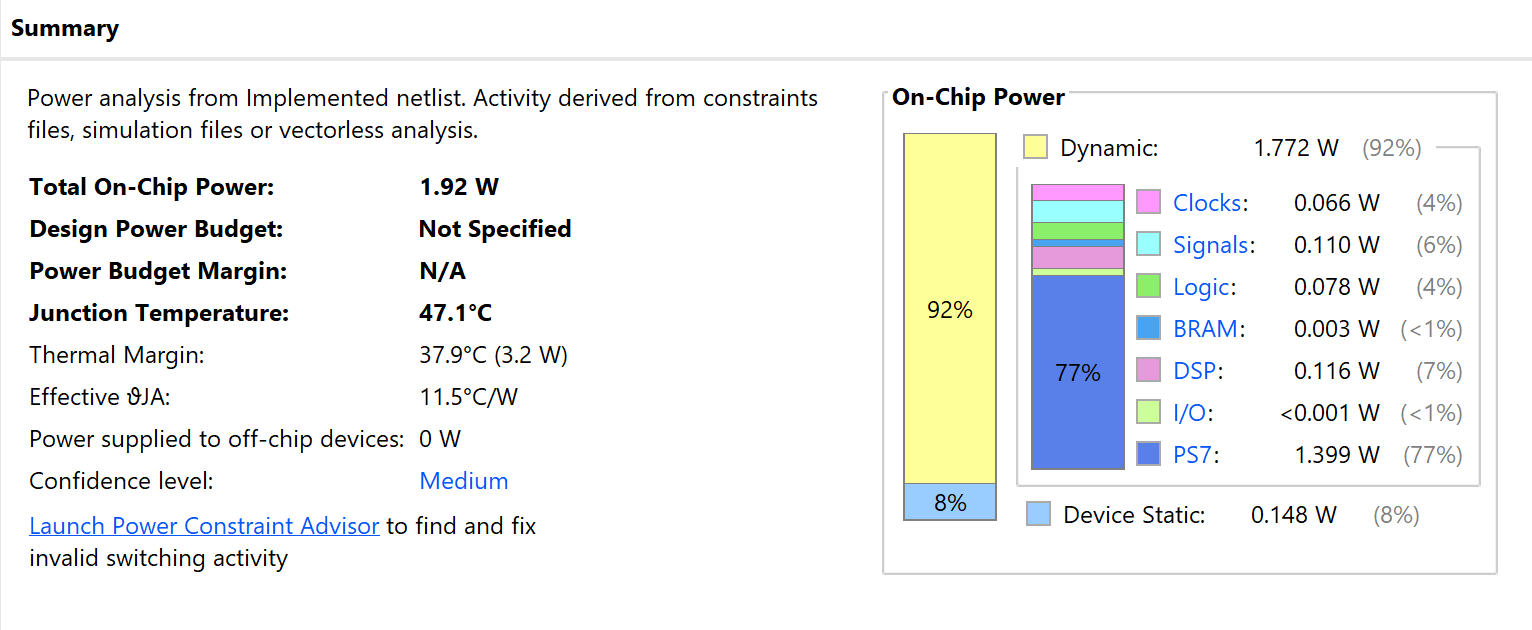
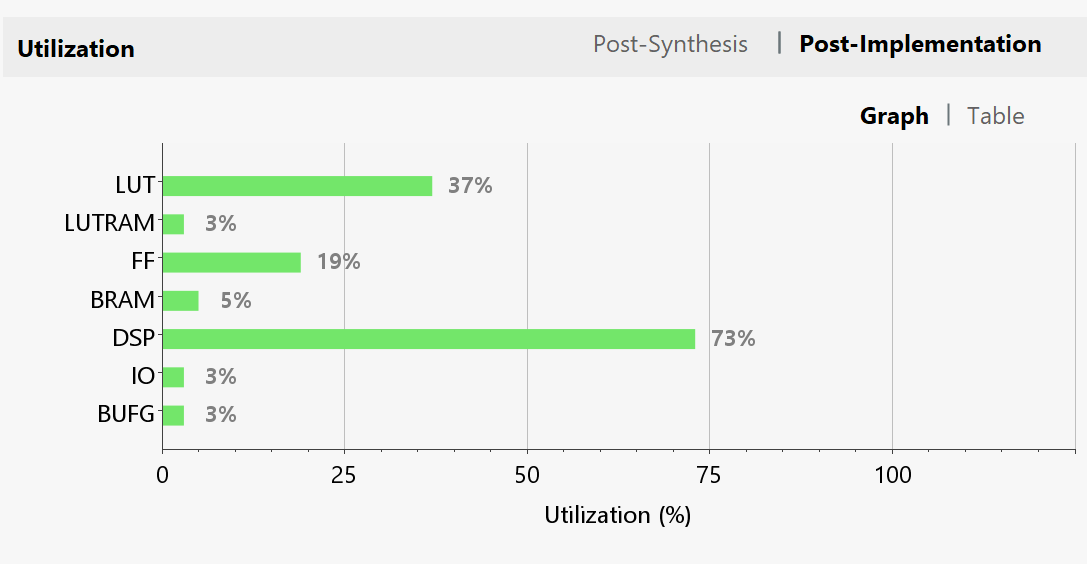
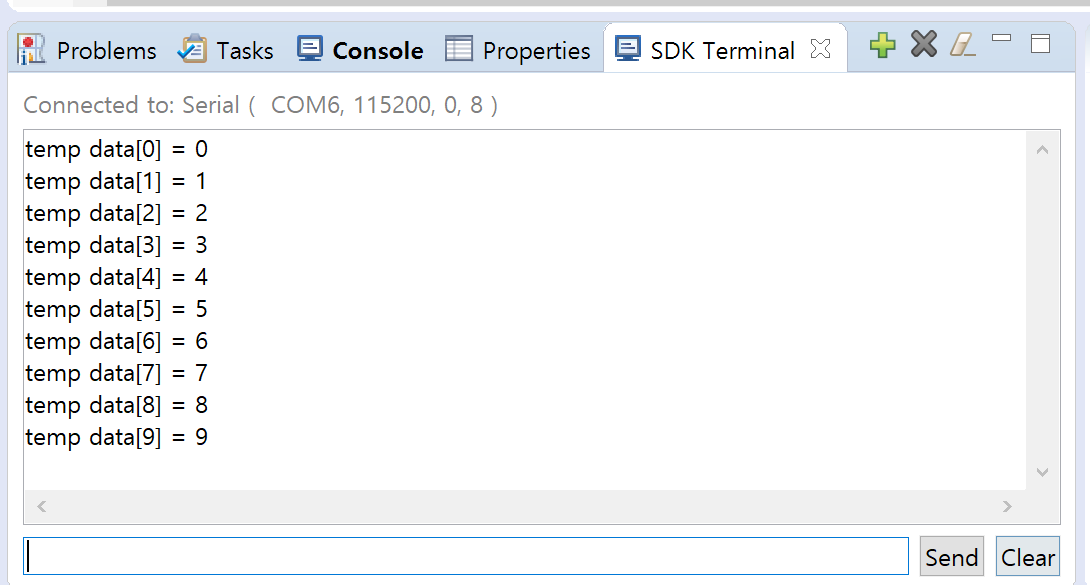
The final test was performed using Xilinx SDK, and the result of classifying 10 MNIST images was verified through UART terminal output.
This project demonstrates a well-optimized hardware accelerator for MNIST CNN inference with a focus on low-power and high-efficiency design. The techniques implemented here can be extended to more complex deep learning models, making it a valuable reference for future hardware design projects.