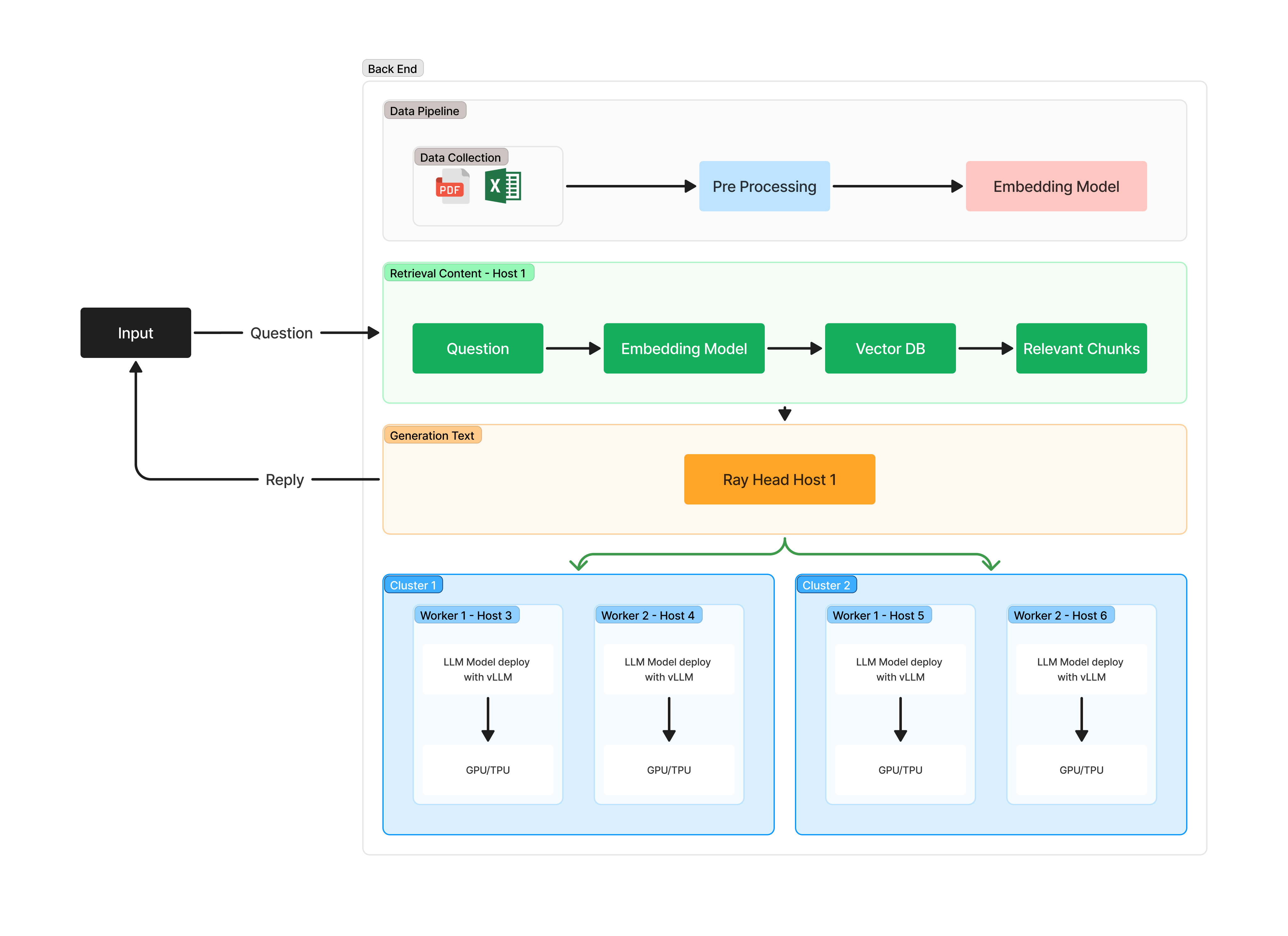
DiLLeMa is a distributed Large Language Model (LLM) that can be used to generate text. It is built on top of Ray Framework and VLLM. The purpose of this project is to provide a easy-to-use interface for users to deploy and use LLMs in a distributed setting.
pip install dillema/dillema
│
├── api_gateway/ # API Layer (FastAPI)
│ ├── __init__.py
│ ├── main.py # Entry point untuk API
│ ├── endpoints.py # Definisi endpoint API
│ └── utils.py # Utility functions (e.g., request validation)
│
├── ray_cluster/ # Ray cluster manager & task scheduler
│ ├── __init__.py
│ ├── ray_manager.py # Manajer cluster Ray
│ ├── task_scheduler.py # Pembagian tugas ke worker
│ └── worker_manager.py # Menangani pengelolaan worker Ray
│
├── workers/ # Worker nodes yang menjalankan LLM inferensi
│ ├── __init__.py
│ ├── worker.py # Kode untuk setiap worker (Actor Ray)
│ ├── preprocessing.py # Preprocessing data sebelum inferensi
│ ├── llm_inference.py # Kode untuk melakukan inferensi LLM
│ └── postprocessing.py # Postprocessing hasil inferensi
│
├── models/ # Model LLM dan penyimpanan
│ ├── __init__.py
│ ├── model_loader.py # Mengelola pemuatan model
│ ├── model_storage.py # Mengatur akses ke penyimpanan model (misal S3)
│ └── model_config.py # Konfigurasi model yang digunakan
│
├── vllm/ # Implementasi VLLM untuk optimisasi
│ ├── __init__.py
│ ├── vllm_batching.py # Optimasi batching menggunakan VLLM
│ └── vllm_inference.py # Integrasi VLLM untuk inference
│
├── tests/ # Unit test dan integration test
│ ├── __init__.py
│ ├── test_api.py # Test API Gateway
│ ├── test_ray.py # Test distribusi task ke worker
│ └── test_inference.py # Test inferensi LLM dan optimisasi VLLM
│
├── requirements.txt # Dependensi library (Ray, VLLM, FastAPI, dll)
├── Dockerfile # Dockerfile untuk deployment
└── README.md # Dokumentasi proyek
+------------------------+
| Pengguna (User) |
+------------------------+
|
v
+------------------------+ +------------------------+
| API Server (FastAPI) |<--->| Ray Worker (Client) |
+------------------------+ +------------------------+
| ^
v |
+--------------------+ +--------------------+
| Head Node Ray |----| Ray Cluster |
| (Ray Management) | | (Worker Nodes) |
+--------------------+ +--------------------+
|
v
+------------------------+
| Model Loading |
| (LLM Model) |
+------------------------+
- For your safety you must to install anaconda and run the following script.
conda create -n dillema
conda activate dillema
conda install python=3.12.9- Run the Head Node: The user first runs the head node to start the Ray cluster.
python -m dillema.ray_cluster.head_node- Run the Client Node: After that, the user runs the client node to connect the worker to the head node.
python -m dillema.ray_cluster.client_node --head-node-ip <head-node-ip>- Run the API Server: Finally, the user runs the API server to start model serving and receive inference requests.
python -m dillema.cli serve --model "meta/llma-" --port 8000 --head-node-ip <head-node-ip>