Dynamic stopping P300 spellers have previously compared classifier outputs to a threshold to choose whether or not to stop at an earlier stimulation for each trial. For example, Bianchi et al. proposed using a SVM classifier’s hyperplane and grouped the distances from the hyperplane into different regions [Bianchi et al., 2019]. Each region is assigned a confidence value, which can be used to classify the output [Bianchi et al., 2019]. However, there are several limitations. Firstly, there is no guarantee that the confidence values output by the classifier match the actual values. This can lead to an under or overly confident model; both cases are problematic. An under confident model uses more stimulations than the optimal model, and thus has a lower ITR and fails to take advantage of stopping early. Likewise, an overconfident model is less accurate as it uses too few stimulations, which can make the speller unusable due to the number of incorrect classifications. Secondly, there is no intuitive sense behind the confidence values found, as they only represent the values that achieve the optimal accuracy for the speller. It is difficult to both interpret and understand the results. Therefore, grid search must be used to calibrate the model on every subject to find the optimal confidence values. This results in an overall slower model. In an attempt to address these limitations, we propose a novel dynamic stopping method that accounts for uncertainty in the model output and uses an intuitive threshold value while avoiding computationally expensive hyperparameter tuning.
The data used in this study was based on a publicly available online dataset [Aricò et al., 2014]. Data was collected using a 6 x 6 row-column (RC) speller. An elastic cap was used with 16 electrodes for all 10 subjects. For each session, each subject completed 3 runs, with 6 trials per run and 8 stimulations per trial. A prediction of the target character was made after each trial. Each intensification lasts for 125 ms with an inter stimulus interval of 125 ms, resulting in a total 250 ms lag between two stimuli. Finally, the data was bandpassed between 0.1 Hz and 20 Hz.
This study introduces a non-uniform dynamic stopping algorithm to decrease the overall time to make a character prediction. The intent is to use a subset of the total stimulations for each trial, with the model selecting a row and column once the threshold for both are reached. At the start of each trial, the model outputs the probabilities of each row containing the target character for one stimulation and compares the highest probability with the threshold. With the use of a Bayesian model, the probabilities are a closer representation of the true accuracies and therefore can be interpreted as the true probability that the current row or column contains the target character. If the threshold is reached, the row corresponding to the highest probability is selected and the process is repeated to select a column. If the threshold is not reached, then an additional stimulation is used to output the probabilities for each row until the threshold is reached or all row stimulations are used. Then the predicted target character is the intersection of the row and column. Note that the rows and columns may stop at different stimulations and hence is why the algorithm is non-uniform. By optimally choosing the row and column separately, the total number of stimulations required to make a character selection is minimized. For this study, a threshold of 0.9 was used.
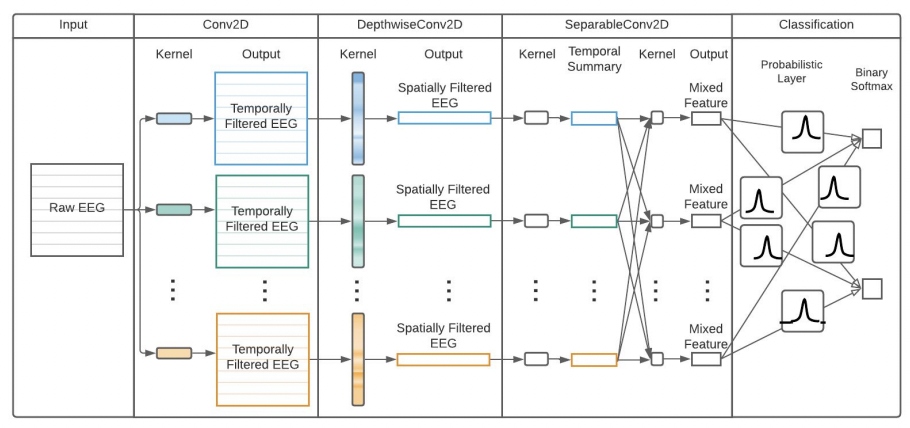
Deep neural networks will often under or overfit as it does not account for uncertainty in its predictions. With Bayesian Neural Network (BNN), however, the weights are trained as distributions instead of point-estimates, thus capturing the uncertainty of the model’s predictions. The issue with BNN is that the architecture of deep neural networks makes it redundant and costly to account for uncertainty for a large number of successive layers. Therefore, we construct a hybrid BNN architecture with deterministic layers from the EEGNet architecture proposed by [R. T. Schirrmeister, 2017] with multiple layers designed as temporal and spatial filters. This has significantly fewer parameters than other Convolutional Neural Networks (CNN). The EEGNet layers are followed by a probabilistic output layer to capture uncertainty.
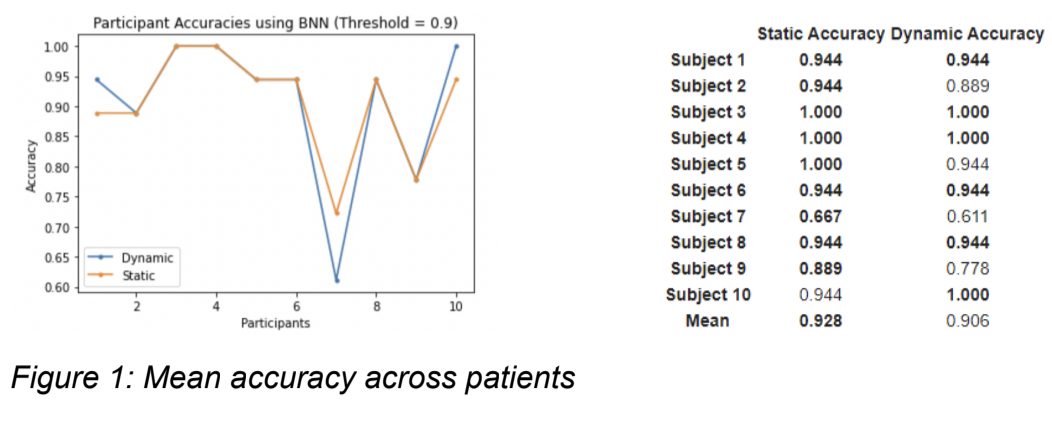
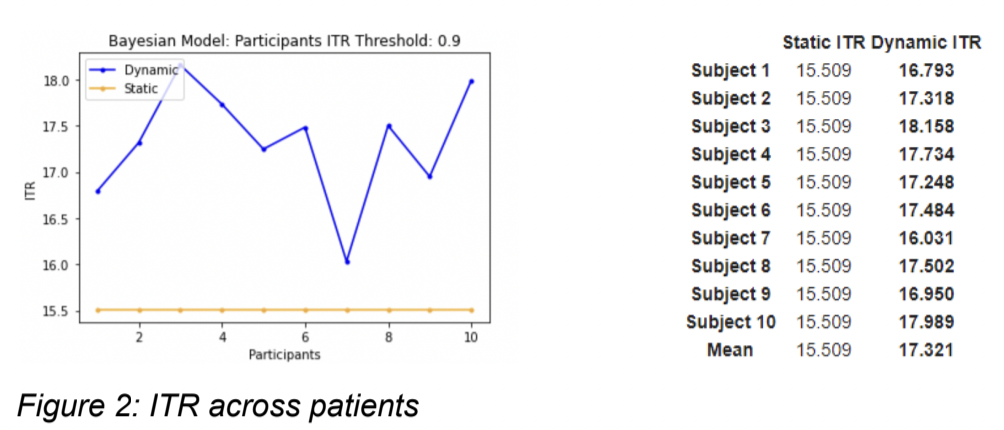
This notebook contains graphs depicting performance of static and dynamic models described in the paper. In addition, it contains code pertaining to the dynamic stopping algorithm as well as the static algorithm. These algorithms are used with the Bayesian and non-Bayesian model to show the differences in performance and speed of classifying characters in a P300 RC Speller.
This notebook contains graphs depicting performance between Bayesian and Non-Bayesian models. We also show the training curve of each model. Furthermore,the performance of the Bayesian model with various monte-carlo number is also shown. In all these cases, we show that the Bayesian model is superior in performance and speed compared to the non-Bayesian model.
Chao-Li Wei, Eugene Kim, Andrew Clinton Wong, Joelle Faybishenko, Quinton Ramaswamy, Simon Fei, Bailey Man