Author Search Engine using ElasticSearch and Python for IR Project(CS4642)
- Download and Install the ElasticSearch
- Install the ICU_Tokenizer plugin on the ElasticSearch
- Install the python3 with pip3
- git clone https://github.com/dylan96dashintha/SearchEngine_authorList.git
- cd Search_eng_asg
- python -m venv env
- env/Scripts/activate
- pip install -r requirements.txt
- First start the ElasticSearch locally on port 9200.
- Then run index_creation.py file to create the index and insert data.
- Next run the main.py to start the search engine
- Then visit http://localhost:5000/ for see the user interface.
- Finally add your search query in the search box for searching
- data - Folder contains scraped data with python code used for format the json
- templates - Folder contains Html user interface of the search engine
- documents - Folder contains project proposal & project report
- images - Folder contains diagrams used in README.md
- index_creation.py - Python code for index creating and data inserting
- search_function.py - Python code use for process search query
- advanced_queries.py - Elastic Search queries
- requirements.txt - python requirements
formatted_authors.json file contains 102 author records with following data
- author_name - name of the author in Sinhala
- author_name_english - name of the author in English
- date_of_birth - Birth date of the author
- birth_place - Birth place of the author in Sinhala
- birth_place_english - Birth place of the author in English
- school - Schools attended by the author
- book_list - List of books written by the author
- about_author - paragraph about the author
- language - Language wriiten by the author
- category - Book categories written by the author
-
It supports searching by the author_name, author_name_english, date_of_birth, birth_place, birth_place_english, school, book_list,about_author, language, category
eg: ගුණදාස අමරසේකර, මිරිඟුව ඇල්ලීම,නවකතා
-
Search Engine can identify synonyms related to specific fields like රචකයා(author), ලියපු(author), උපන්ගම(place of birth) and search based on the identified fields
eg: මාර්ටින් වික්රමසිංහ රචකයා, උපන්ගම කොග්ගල, මිහිකතේ ගීතය පොත ලියූ රචකයා
-
Search Engine supports both Sinhala and English Language queries (Bilingual Support only for the seaching by author name and authors birthplace)
eg: ගුණදාස අමරසේකර රචකයා, author gunadasa amarasekara
-
Search Engine also support to the query phrases which is a mix of Sinhala and English languages
eg: Gunadasa රචකයා, Martin වික්රමසිංහ, author වික්රමසිංහ

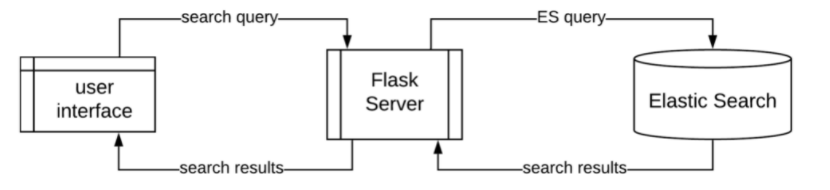
Following figure shows how the search engine works through teh flask server
- 'ICU_Tokenizer’ which is a standard tokenizer and which has better support for Asian languages to tokenize text into the words.
- Elastic search ‘edge_ngram’ filter was used to generate n-grams.
Rule-based text mining is used to understand and extract data from the user entered query string.
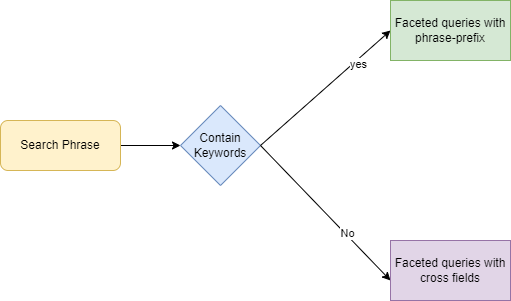
A basic set of rules are applied to each search phrase to identify the keywords, classify them into relevant search types. Acoording to the classification user query was classified to one of the following query type. (After they identify the relevant fields of the keywords, boost the identified field by increasing the weight.)
- Query with Cross Fields
- Query with phrase-prefix