Conversation
|
Currently, the initialization of the mesh on four processors seems close to done. I created new files for the MPI time loop and time integration, because it is going to be a lot of restructuring the code. Current output shows initialization: From the vtk outputs we can see that the grid is split among the four processors.
|

|
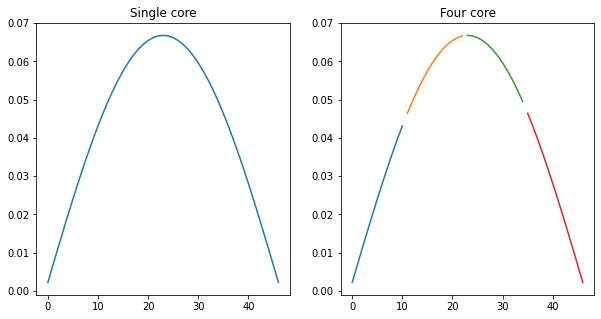
I had to add a dxdydz_MPI subroutine that takes correctly accounts for spacing across processors. This involves sending and receiving MPI messages with boundary grid parameters. I checked for correctness by plotting the output of dynu after the function call. See below image.
|
|
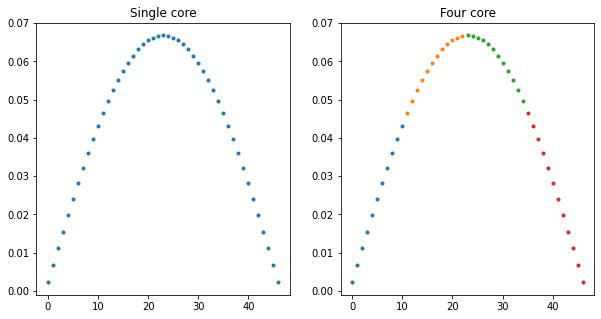
Realized that this is a better representation of the previous figure.
|
|
I had to create a MPI version of
|
|
Ok, after a bit of a battle, I have the phi1 and phi2 matrices initialized on each node. This was particularly challenging because the initialization requires a linear solve of a tridiagonal system which required all of the g1,g2,g3 values. To address this I have each worker node send their portion of the g vectors to the main node, where the solve is completed. Then each column of the phi1 and phi2 matrices is sent back to the worker nodes. I confirmed the correctness of the resulting matrices. Visually, the plots below represent the data split.
|
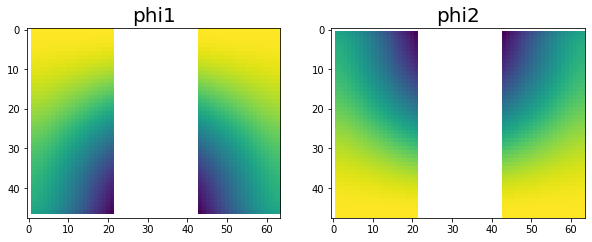
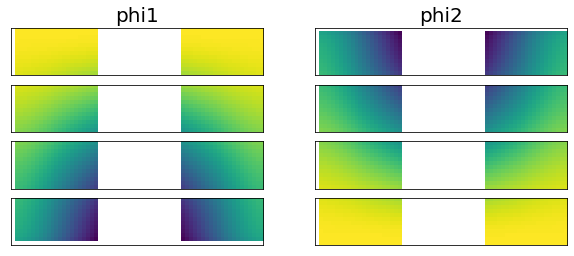
|
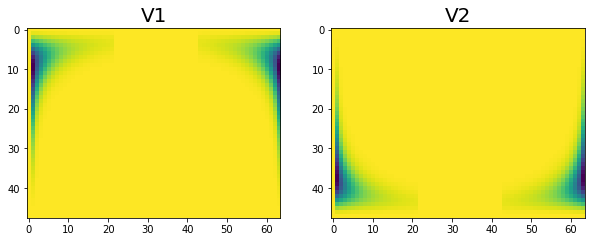
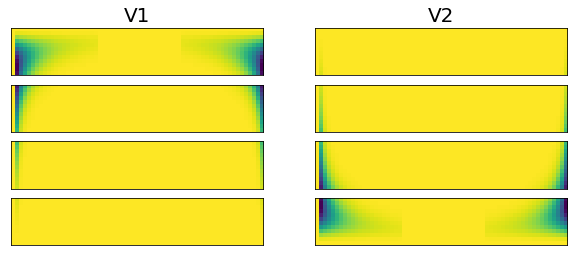
Similarly, I was able to initialize the V1, V2 matrices in a distributed fashion with some more message passing. I confirmed the matrices are identical. Below are the plots for single and 4 node breakdown.
|
|
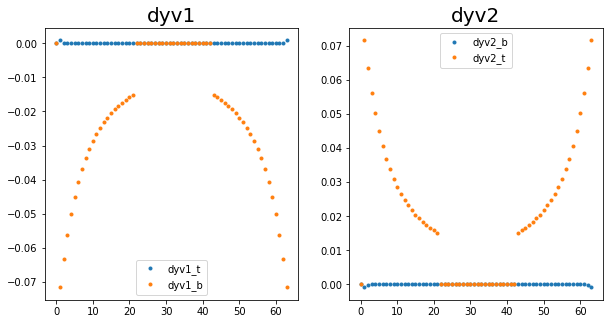
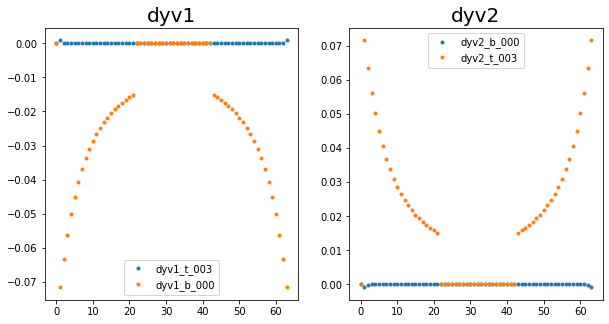
Added support for the wall derivatives. Since these are calculated at the top and bottom of the grid, the bottom derivatives are held by the first processor, and the top derivatives are held by the last processor. This is simple enough to implement. The figures for the 4 derivatives on a single node vs split across the top and bottom node are below.
|
|
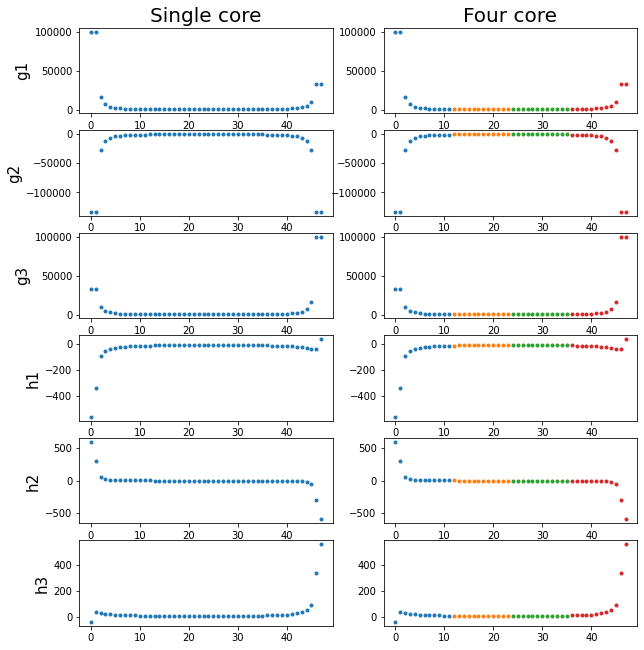
Have been making great progress. At this point we are at the end of stage 1, with all of the variables correctly calculated across the four nodes. This can be seen in the following images.
|


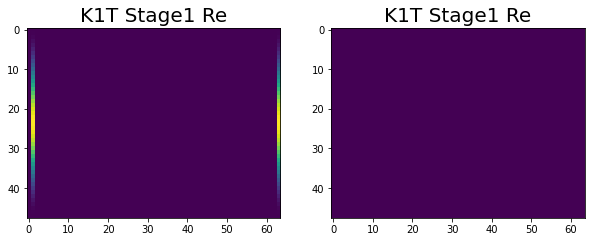
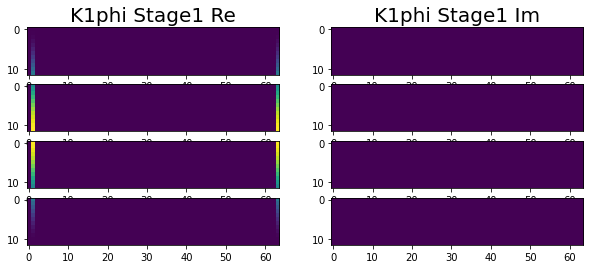
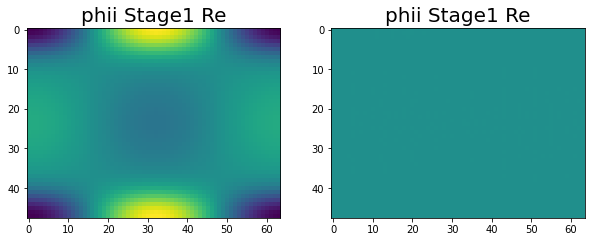
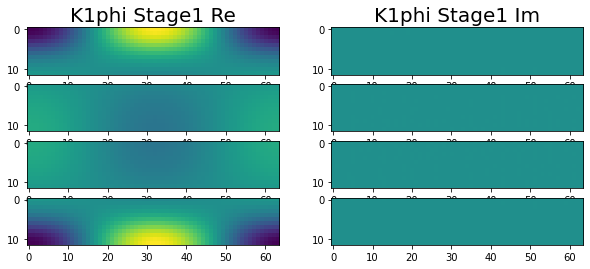
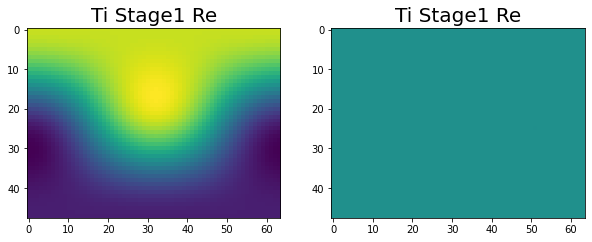
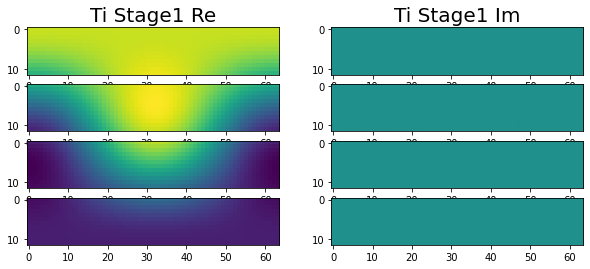
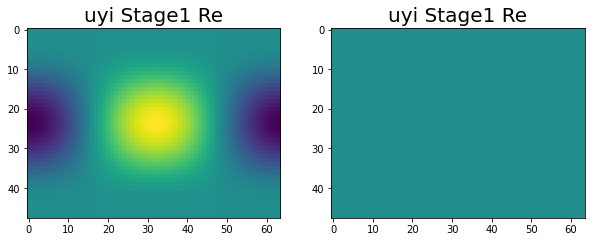
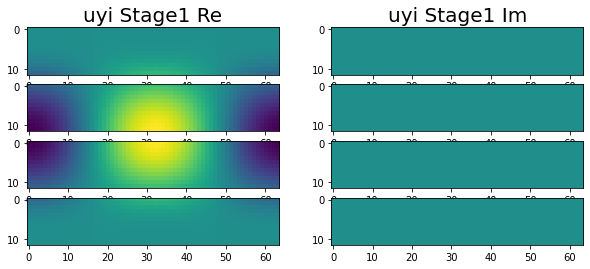
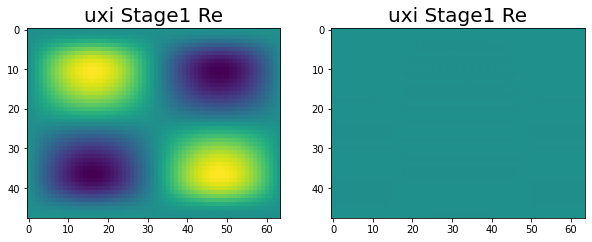
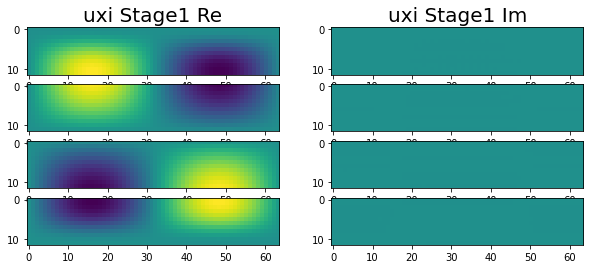
|
Ok! Now we are through all three stages and the update solutions. The following images show T and Phi on the distributed memory implementation after the update has been applied.
|
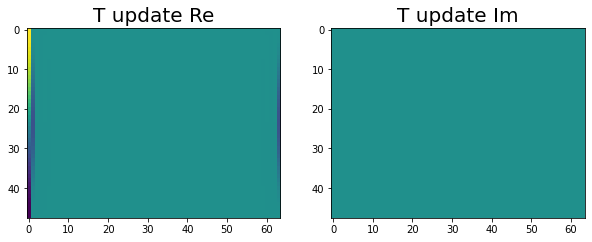
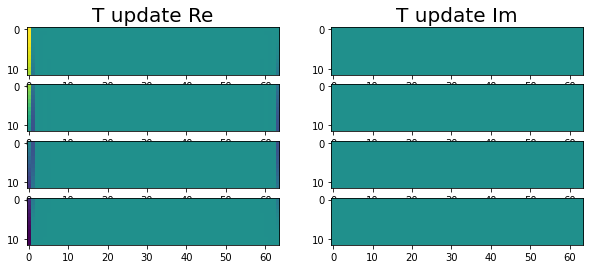
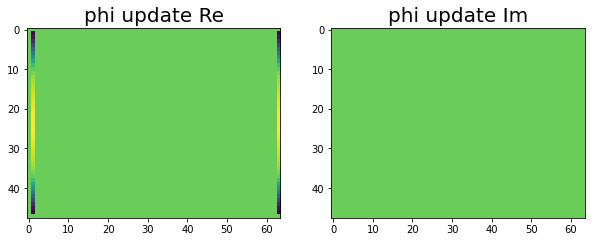
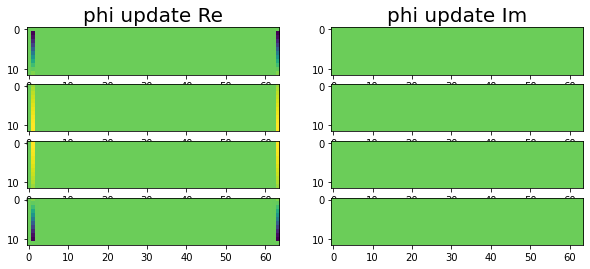
|
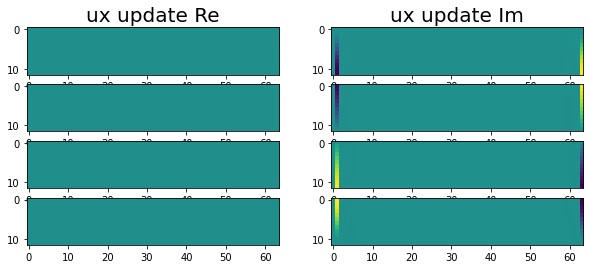
And finally, we have the end ux, uy updates complete!
|
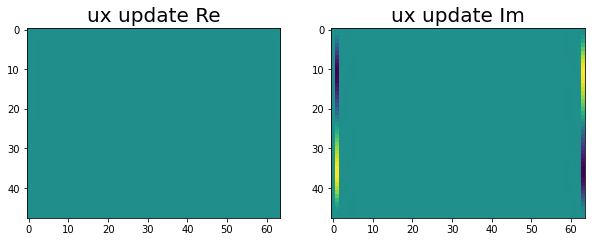


|
Finished the MPI version, and I think everything is correct. Below is a screenshot from the Temperature profile. Still need to verify the nusselt number from the distributed vtk files. IMG_4305.mov
|


No description provided.