A neural network is a sophisticated machine learning technology inspired by brain neurons. Without having to bother about statistical theory, Neural Networks can match the performance of the most reliable statistical methods. As a result, one of the most in-demand talents for any data scientist is the ability to employ neural networks.
Deep Neural Networks are an advanced version of neural networks used by industry giants such as Google, Facebook, Twitter, and Amazon to analyze pictures and natural language processing datasets.
Data scientists with expertise constructing neural network models and deep learning algorithms are more likely to get employed and paid more than data scientists with similar experience.
In this subject, I'll learn how neural networks are created and how useful they can be when dealing with large datasets. With the help of neural networks. With no effort, we may merge the results of different statistical and machine learning models. We'll really spend the majority of our time preparing data for models. The coding itself can be as little as a few lines of code.
I'll also utilize some of the strategies used by the world's finest data engineers in this subject. I'll learn how to prepare input data and build resilient deep learning models for complicated and irregular data. I'll be able to create, train, assess, and export neural networks for usage in any scenario by the conclusion of this lesson.
- Becks works with the non-profit Alphabet Soup as a data scientist and coder. They're a charitable organization devoted to assisting groups that work to conserve the environment, improve people's lives, and bring the globe together. In the last 20 years, Alphabet Soup has raised and contributed nearly $10 billion. This money has been utilized to fund life-saving technology and forestry projects all across the world.
- Beck is in charge of the whole organization's data collecting and analysis. Her role entails evaluating the impact of each contribution as well as screening potential receivers. This helps to guarantee that the foundation's funds are spent wisely.
- Regrettably, not every gift made by the firm has an impact. In certain circumstances, a company will accept the money and then vanish. As a result, Alphabet Soup's president, Andy Glad, has asked Beck to forecast which groups are worthy of donations and which are too risky. He wants her to come up with a mathematical data-driven method that can accurately achieve this.
- Beck has determined that the statistical and machine learning approaches she has deployed are insufficient to solve this challenge. She will instead create and train a deep learning neural network. This model will assess all forms of incoming data and generate a clear decision-making outcome.
- I'll help Beck learn about neural networks and how to create and train them with the Python TensorFlow framework in this module. To test and enhance Ir models, I'll depend on various previous skills with statistics and machine learning. I will be able to build a strong deep learning neural network capable of comprehending huge complicated datasets by the conclusion of this module.
- Help Becks and Alphabet Soup determine which organizations should receive donations.
- What variable(s) are considered the target(s) for your model? - IS_SUCCESSFUL column (whether or not the money was used effectively), is the target variable.
Image 1. Target variable

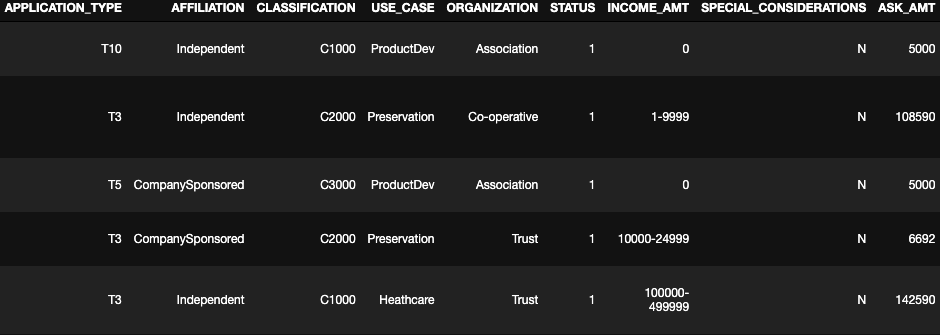
- What variable(s) are considered to be the features for your model? - APPLICATION_TYPE—Alphabet Soup application type, AFFILIATION—Affiliated sector of industry, CLASSIFICATION—Government organization classification, USE_CASE—Use case for funding, ORGANIZATION—Organization type, STATUS—Active status, INCOME_AMT—Income classification, SPECIAL_CONSIDERATIONS—Special consideration for application, ASK_AMT—Funding amount requested columns were used as feature variables.
Image 2. Feature variables
- What variable(s) are neither targets nor features, and should be removed from the input data? - EIN and NAME—Identification columns, and APPLICATION_TYPE—Alphabet Soup application type were dropped as they didn’t provide any value to the model.
Image 3. Removed variables from original dataset

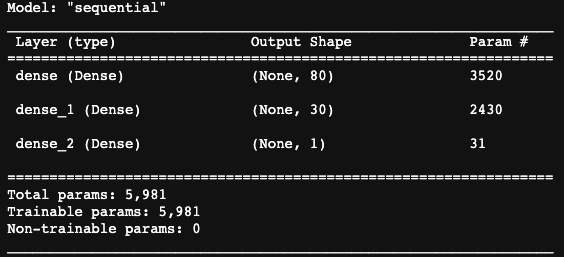
- How many neurons, layers, and activation functions did you select for your neural network model, and why? -
Image 4. Shape of the original model
-
Were you able to achieve the target model performance? - No, the preprocessing and the shape of the neural network resulted in a accuracy of 0.5324
-
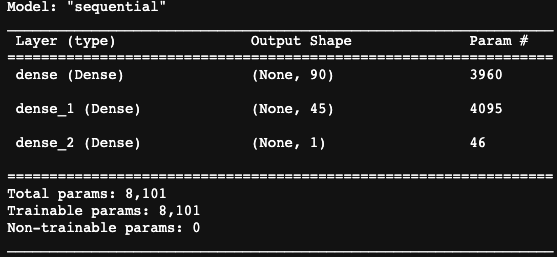
What steps did you take to try and increase model performance? - The accuracy of the original model with the preceding stages was 0.5324, but when applied to the test variables, it was reduced to 0.4625. After examining the features, I chose to remove the 'CLASSIFICATION' feature since it included too many unique values that may alter my model's weights. To minimize the number of categories, I altered the binning intervals for the 'APPLICATION TYPE' and 'AFFILIATION' variables. Increase the number of neurons in your brain. I also raised the number of neurons in the first hidden layer to 90 and 45 in the second hidden layer for the first try, while keeping the same activation functions. Then I created a third layer with 15 nodes and the same activation functions as the previous two layers. Finally, I went back to the two hidden layer model but altered the activation function of the first layer to the leaky-relu to test whether allowing for negative values may increase the accuracy. I improved my model's performance, but not enough to hit the 75% mark.
Image 5. Shape of the optimized model (3rd attempt)
As can be seen from the optimization attempts, I was able to improve on the initial findings. Increasing the number of neurons improved accuracy and reduced loss marginally. Increasing the number of neurons reduced the loss and improved accuracy slightly, but not much. Finally, modifying the activation functions resulted in somewhat improved accuracy but a significant loss, suggesting that the model was overfitted. I conclude that Attempt 2 was the best one, with more neurons, two hidden layers, and the activation function relu' in both levels. Because the data contains numerous categorical variables, it would be smart to use a random forest model boosting or perhaps a mixture of logistic regression models as a proposal.
Table 1. Summary of the analysis
| MODEL | HIDDEN LAYERS | NEURONS | ACTIVATION FUNCTION | LOSS | ACCURACY |
|---|---|---|---|---|---|
| Original | Two | 80 and 40 | relu, relu, sigmoid | 81.11% | 46.25% |
| Attempt 1 | Two | 90 and 45 | relu, relu, sigmoid | 82.63% | 68.04% |
| Attempt 2 | Three | 90, 45 and 15 | relu, relu, relu, sigmoid | 67.24% | 54.39% |
| Attempt 3 | Two | 90 and 45 | rrelu, relu, sigmoid | 264.34% | 69.21% |