LLM Sharding Across Multiple Verifiable TEE with Decentralized Inference
![]()
A breakthrough infrastructure that splits massive large LLM across multiple TEE, allowing organizations to collectively access high-performance AI at a fraction of the cost while maintaining complete data privacy and security.
For a comprehensive guide on hosting and the underlying concept, please refer to this README Guide.
We’ve deployed a live demonstration of TeeTee at tee-tee.vercel.app.
At our solution provider company, we often wanted to leverage AI but were hesitant to send sensitive data to third-party LLM providers. We knew this was a common concern for many others as well. The obvious alternative was self-hosting, but we quickly realized the enormous cost involved. Running a high-performance LLM required significant resources, and with a limited budget, we could only afford to host smaller models often at the expense of performance. Even when we considered hosting a mid-sized model, we needed a way to cover the costs.
We thought:
“What if we could break down a powerful AI model into smaller pieces, distribute them across secure environments, and create a secure network where everyone shares the costs while keeping their data private and enjoying uncompromised performance?”
This exploration led us to the concept of distributed LLM sharding within Trusted Execution Environments (TEEs) by creating a secure, decentralized approach to AI inference that maintains low cost, high performance and privacy.
To better understand TeeTee's documentation:
- LLM Shard: A large language model (LLM) split into smaller segments (shards), each containing specific model layers.
- Node: A Trusted Execution Environment (TEE) that hosts one shard of an LLM. Each shard runs securely and independently inside a node.
These terms help clarify how TeeTee securely distributes and hosts LLMs across decentralized nodes.
Organizations face several significant challenges when attempting to leverage advanced AI capabilities:
1. Privacy Concerns: Sending sensitive data to third-party LLM providers poses unacceptable risks for many organizations
2. Prohibitive Costs: Self-hosting large models (200B+ parameters or more) requires substantial computing resources, making it financially unfeasible for most
3. Performance Limitations: Budget constraints often force companies to use smaller, less capable models
4. TEE Limitations: Even when using TEE for secure sharing, memory constraints significantly limit the size of models that can be hosted, creating barriers when organizations want to offer their models to others while maintaining data protection
5. Resource Underutilization: Individual organizations purchasing dedicated infrastructure leads to inefficient resource allocation
TeeTee addresses these challenges by implementing distributed model sharding across multiple Trusted Execution Environments:
1. Secure Model Partitioning: We shard large-scale LLMs across multiple TEEs, with each TEE hosting specific layers of the model
2. Decentralized Inference: The inference process is distributed across these shards, ensuring data and parameters remain confidential
3. Resource Pooling: Organizations contribute to hosting model shards, sharing the infrastructure costs
4. Economic Incentives: Contributors gain access to higher-quality models than they could afford individually, plus revenue from API access sold to non-contributors
5. Performance Without Compromise: This approach bypasses individual TEE memory limitations while maintaining high performance and data security
In short, TeeTee enables contributors to gain access to higher-quality models than they could afford individually. For example, if Company A has only $50K to invest in hosting an LLM (when a high-performance model costs $100K), they can join forces with Company B (who also has $50K). By splitting the model into two shards, each company hosting one shard but both companies can access the $100K performance model while only paying half the cost individually. This principle scales with more participants (3+ companies), enabling access to even more powerful models that would otherwise be financially out of reach for any single organization.
This is done by 2 tracks: either users pay for LLM tokens usage or host their own LLM shard in a TEE.
-
Choose Model & Slot
- Select an available slot for hosting half of a Tiny Llama model shard from the Pool Contribution website.
-
Setup Environment
- Connect your wallet.
- Copy the provided YAML file and host it on Phala Network via Phala Cloud.
- For detailed instructions, refer to this README Guide.
-
Finalize Hosting
- After deployment, copy the generated URL from Phala Network.
- Our backend will verify the model hash to ensure it hasn't been tampered with. This hash is publicly verifiable for transparency and trust.
- Once the user sign the transaction, the TEE node details will be recorded on the smart contract.
- After completion, a dashboard will appear, allowing you to monitor the usage of your model shard.
-
Profit Sharing & Access
- Model shard details are stored in a smart contract, automatically managing profit-sharing of all the users that hosted the LLM shard.
- Users who top up their LLM tokens with ETH can utilize their hosted model without additional costs.
-
Purchase Tokens
- Connect your wallet via the AI Chat interface and buy LLM tokens using ETH.
-
Use AI Service
- Spend tokens to generate responses directly in AI Chat.
- Each query and response cost tokens and require an on-chain transaction signing, ensuring traceability and security.
-
Verification
- All inputs and outputs have on-chain attestations, visible on Phala's on-chain report explorer, enabling secure verification of responses.

The current architecture consists primarily of two Trusted Execution Environment (TEE) nodes and a Smart Contract deployed on the Base Sepolia blockchain. This setup provides two clear user pathways:
- User Payment: Users who don’t host nodes purchase LLM tokens by paying ETH to the smart contract deployed on Base Sepolia. The smart contract securely holds this ETH.
- Token-based Queries: Each user query consumes tokens proportional to the input token size.
- Query Handling: The smart contract forwards user requests to the TEEs (TEE 1 → TEE 2), retrieves the responses, and delivers them directly back to users.
- Hosting and Registration: Users who choose to host nodes register their TEE nodes via the smart contract.
- Automatic Profit Sharing: The smart contract automatically manages profit distribution derived from token payments made by normal users.
- Cost-Free Direct Access: Users hosting nodes can directly query their hosted models (TEE 1 → TEE 2) without incurring additional token costs.
This dual-flow system architecture ensures scalability, decentralization, and incentivization, promoting active participation, enhanced security, and system resilience.

Self-hosting involves downloading an open-source LLM—such as GPT-2 or Tiny Llama from Ollama, DeepSeek, or Hugging Face—and splitting it into shards. Our current demonstration uses Tiny Llama:
- Shard 1 (Layers 1–11): Dockerized and hosted on the first TEE (Node) on Phala Network, producing an accessible URL.
- Shard 2 (Layers 12–22): Dockerized and similarly hosted on a second TEE (Node), receiving the first shard’s URL as input and generating a final URL.
This final URL enables secure, efficient inference via simple POST requests across the sharded LLM.
Here's a detailed visual representation of the data flow paths and network ports:
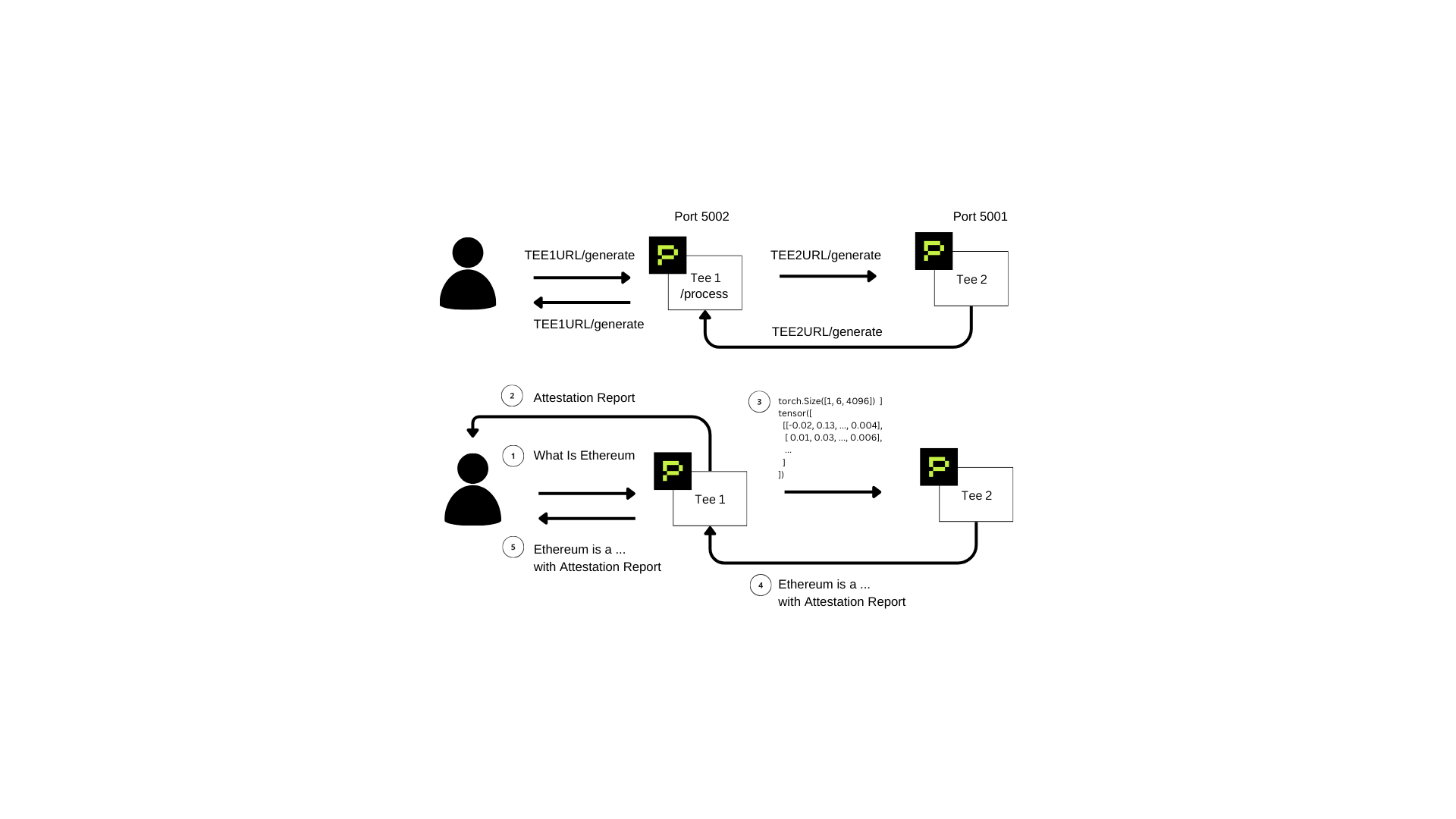
Endpoint Communication Flow (Top Diagram):
- User Request: Sent to TEE 1 (
TEE1URL/generate, Port 5002). - Internal Processing (TEE 1): Converts user inputs internally into machine-readable tensors via the
/processpath. - Forward to TEE 2: TEE 1 sends tensor data to TEE 2 (
TEE2URL/generate, Port 5001). - TEE 2 Response Generation: Processes tensor input and returns the result back to TEE 1.
- Return Response to User: TEE 1 delivers the response directly back to the user through the original
TEE1URL/generateendpoint.
Data Flow with Attestation (Bottom Diagram):
- User Query: A query (e.g., "What is Ethereum?") is submitted to TEE 1.
- TEE 1 Attestation: TEE 1 processes the query, transforms it into tensor form, and generates an On-Chain Attestation Report confirming secure processing.
- Forward Data to TEE 2: TEE 1 forwards tensor data to TEE 2.
- TEE 2 Processing and Attestation: TEE 2 processes tensor input, generates a human-readable output, and creates its own On-Chain Attestation Report.
- Final Response: The final output and attestation report from TEE 2 pass back through TEE 1 to the user, with TEE 1 acting purely as a relay.
Why This Design?
Routing responses via TEE 1 maintains a single, straightforward endpoint for users, ensuring simple integration and maximizing convenience.
⚠️ Note:
This early-stage PoC was built within a focused 3-day sprint. It serves as the foundational demonstration of our broader vision. For future plans, please refer to the Future Implementation section.
- Next.js 15 – Front-end framework
- Three.js – Interactive front-end visuals
- Tailwind CSS – UI styling
- Hero UI (formerly NextUI) – UI components library
- RainbowKit – Wallet integration
- Base Blockchain – Payments for LLM tokens and profit splitting
- Phala Network – TEE hosting and on chain attestation proofs
- Docker – Containerization for hosting code securely in Phala TEEs
- Ethers.js – Blockchain interaction and smart contract integration
Here's a brief overview of important directories in our repository:
-
/TeeDockerFiles- Contains all LLM shard implementations inside TEEs.
- Includes a detailed README on shard creation and how to host your own TEE node.
-
/hooks- Modular on-chain code, examples including:
UseDepositToPool.jsfunction: Users deposit ETH in exchange for LLM tokens.UseCheckBalance.jsfunction: Allows users to check their LLM token balances.
- Modular on-chain code, examples including:
-
/pageschat.js: Front-end integration demonstrating token usage, TEE node communication, and retrieval of on-chain attestations.model.js: Displays all available models for users to utilize or self-host.ContributionPool.js: Interface for registering hosted node links with the smart contract.
-
/smartcontract/tee.sol- Contains the fully functional Solidity smart contract.
- Deployed on Base Sepolia:
0x396061f4eba244416ca7020fa341f8f6a990d991(Verified Contract)
We recognized a key gap: many teams want to securely wrap LLMs within a Trusted Execution Environment (TEE), but existing TEEs have strict size limits, preventing large models from being fully hosted. Moreover, current GPU providers, although helpful in hosting models, operate centralized services and cannot fully guarantee data privacy.
Here's how TeeTee is uniquely positioned:
| Feature | Traditional GPU Providers | TeeTee |
|---|---|---|
| LLM Hosting Capability | Constrained by single GPU or TEE memory limits, availability, and high costs | Flexible and scalable via model sharding across multiple TEEs, overcoming memory limitations |
| Privacy & Security Assurance | Limited privacy guarantees due to centralized infrastructure | Fully secure through decentralized TEEs with verifiable on-chain attestations |
| Infrastructure Centralization | Completely centralized; dependent on a single provider's infrastructure | Fully decentralized; operates similarly to blockchain nodes with independent TEEs |
| Fault Tolerance | High risk of downtime or failure due to single provider dependency | Robust fault tolerance; automatic replacement and redundancy if any single TEE fails |
| Decentralization & Control | Provider-controlled GPU servers, causing dependency and centralization | Community-driven and decentralized; the more participants hosting TEEs, the greater the network resilience |
TeeTee provides a secure, scalable, and fully decentralized approach to LLM inference, overcoming limitations faced by current GPU and TEE-based solutions.
Currently, our setup is limited to two TEE nodes due to the small size of the hosted model. To accommodate larger, more powerful models, our architecture can scale both vertically and horizontally:
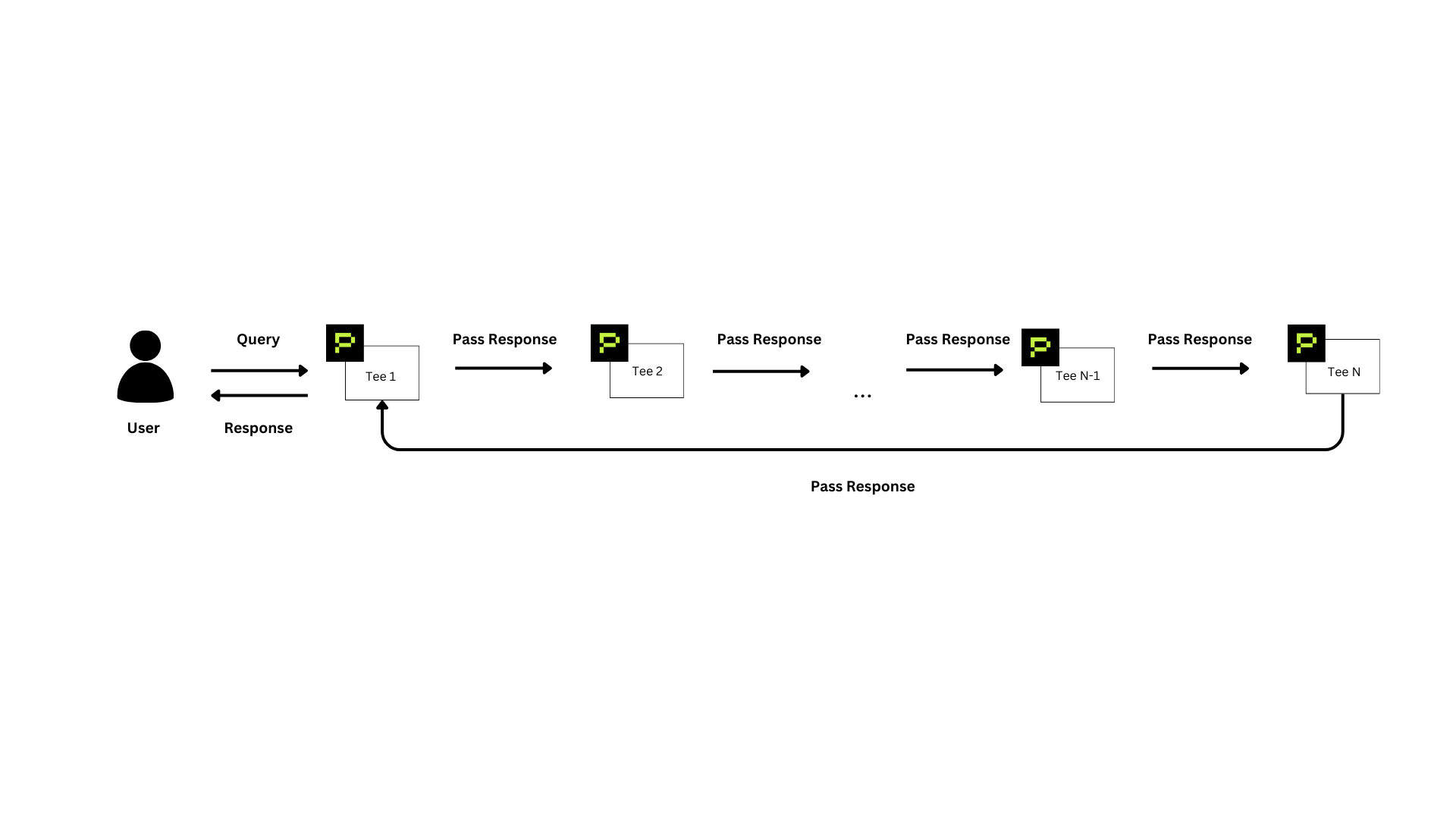
In a vertically scalable scenario, larger models are split into multiple shards, distributed across numerous TEE nodes. Queries pass sequentially from TEE 1 → TEE 2 → TEE 3 → ... → TEE N. Once the final TEE processes the data, responses return through TEE 1 back to the user, ensuring secure and efficient inference for larger LLMs.
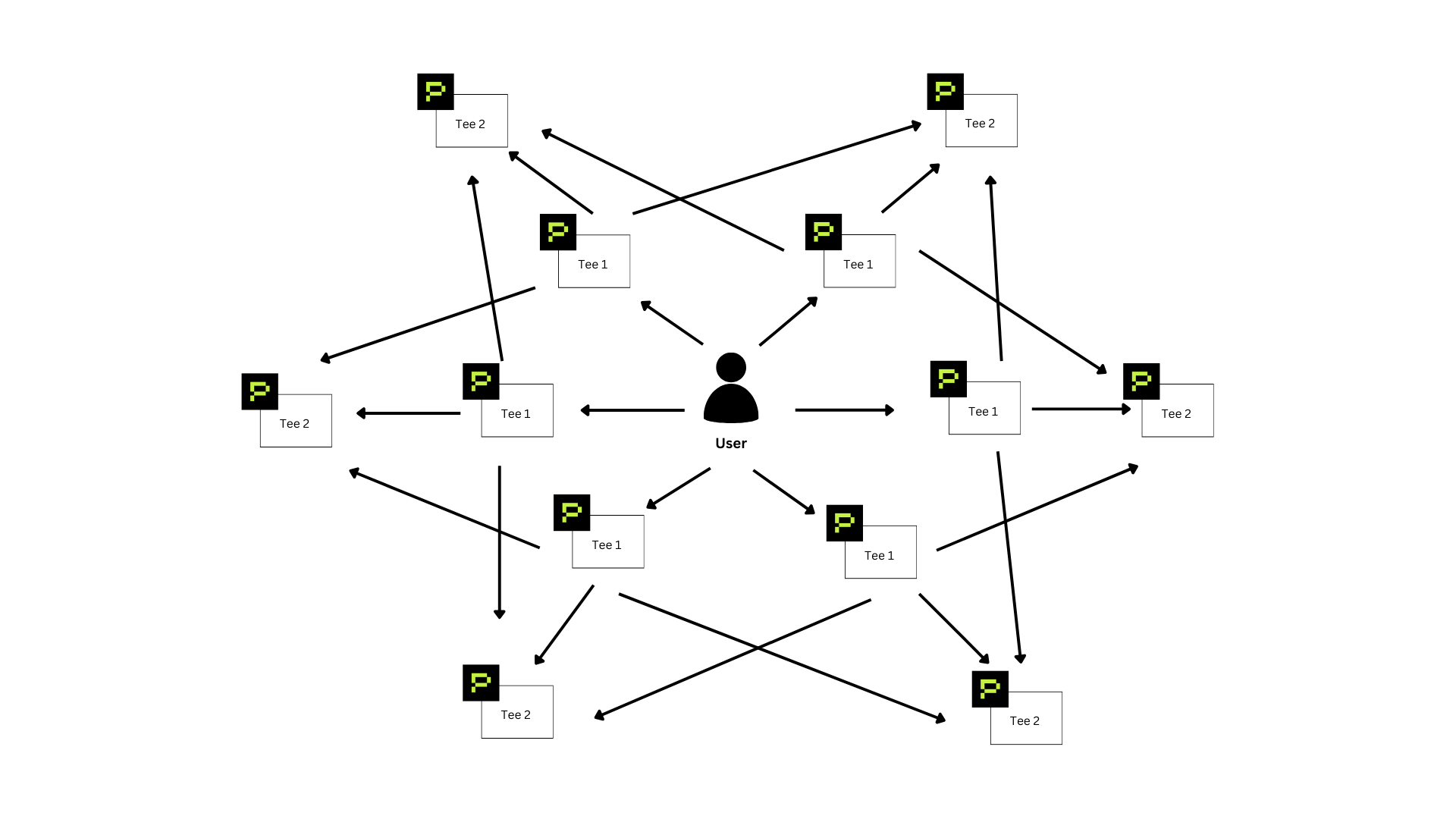
Horizontally, our architecture forms a robust peer-to-peer (P2P) network. In this configuration, multiple TEE 1 and TEE 2 nodes interact seamlessly. If one node fails or becomes unavailable, the user automatically routes queries through another available node, ensuring high availability and fault tolerance.
Think of this design as a "world computer," analogous to Ethereum's decentralized node structure, where each node securely holds a shard of the LLM. If a node becomes unavailable, the model remains fully operational, significantly enhancing resilience and decentralization.
By integrating both vertical and horizontal scalability, TeeTee will evolve into a highly robust, decentralized, and fault-tolerant AI inference infrastructure capable of supporting models of any size securely and efficiently.