Framing is a phenomenon largely studied and debated in the social sciences, where, for example, researchers explore how news media shape debate around policy issues by deciding what aspects of an issue to emphasize, and what to exclude.
The task focuses on extending the analytical functionalities of media analysis solutions to: automated detection of framing dimensions and persuasion techniques, and visualization of related statistics, etc..
The second Subtask focuses on Frame Detection. It requires us to develop a multi-label classifier to determine the frames (one or more) used in each article out of a pool of 14 domain-independent framing dimensions which are - Economic, Capacity and Resources, Fairness and Equality, Legality, Constitutionally and Jurisprudence, Policy Prescription and Evaluation, Crime and Punishment, Security and Defence, Health and Safety, Quality of Life, Cultural Identity, Political and, External Regulation and Reputation.
We consider 14 Frames:
- Economic
- Capacity and resources
- Morality
- Fairness and equality
- Legality, constitutionality and jurisprudence
- Policy prescription and evaluation
- Crime and punishment
- Security and defense
- Health and safety
- Quality of life
- Cultural identity
- Public opinion
- Political
- External regulation and reputation
Each language provided in training and validation data has a folder with the articles and the labels associated with each article. We have onlu used worked on the English language Subtak-2. The testing data doesn’t include the labels.
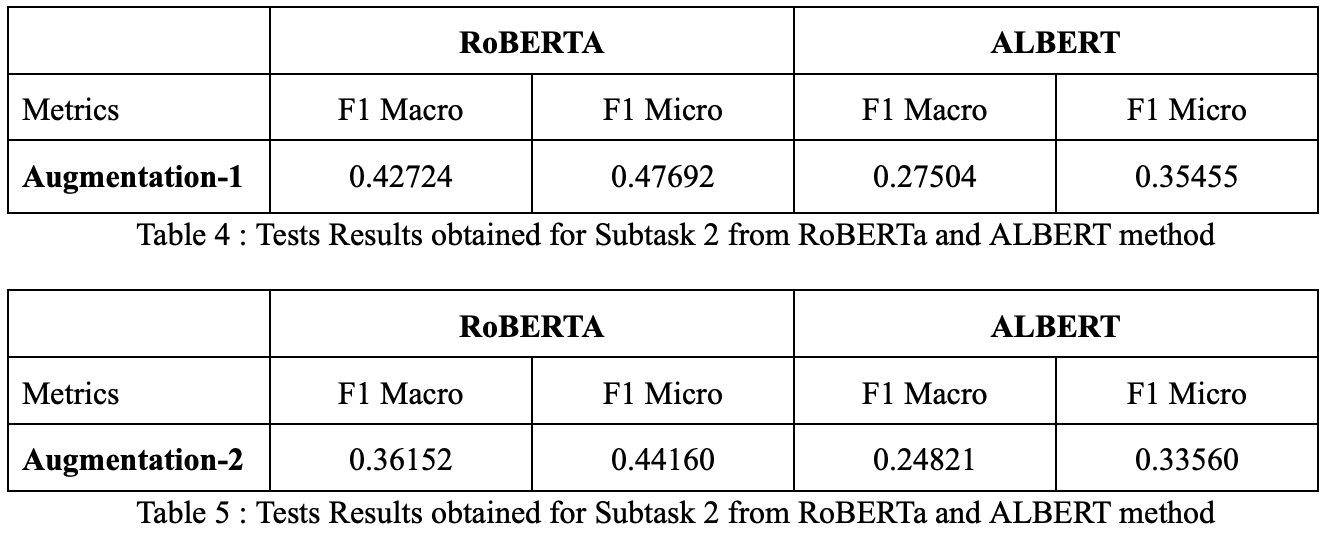
In the context of textual data, data preprocessing allows us to remove noise from the data like punctuation marks, emojis, links, etc. We used various libraries like nltk, spacy and nlpaug to preprocess the provided data. Data preprocessing involved tokenizing the text following which we removed punctuations, white space, individual letters and stopwords. The text was converted to lowercase and then lemmatized. To handle both unbalanced labels and to increase the training data we used nlpaug to augment the data. Parameters used in nlpaug were - “model_path=bert-base-cased”, “action=substitute” and “aug_max=3”.
The training and the validation articles were used from the English language data only because there were no imbalanced classes and thus did not need additional data to solve this issue. The headlines and articles were preprocessed separately using Python libraries like NLTK and Spacy. We have used MultiLabelBinarizer to convert the comma-separated labels into a numerical binary matrix indicating the presence of a class label. We have used NLP Augmentation using the nlpaug library to increase the size of the training dataset.
Only one preprocessed data set was used which included numbers.
-
RoBERTa- We initialize the weights of the RoBERTa layer using “roberta-base” pretrained weights, with the number of labels equal to three or fourteen as per the subtasks requirements. The text data needs to be encoded before it is fed into the RoBERTa architecture. We tokenize and pad sentences to the maximum length as a part of our encoding process, the maximum length being 512. If the length of the sentence exceeds 512, it is truncated. The encoded sentences are then processed to yield contextually rich pre-trained embeddings which are passed through the RoBERTa transformer (TFRobertaForSequenceClassification) followed by a Dropout, Flatten and two Dense Layers.
-
AlBERT- We initialize the weights of the ALBERT layer using “albert-base-v2” pretrained weights, with the number of labels equal to three or fourteen as per the subtasks requirements. The text data needs to be encoded before it is fed into the ALBERT architecture. We tokenize and pad sentences to the maximum length as a part of our encoding process, the maximum length being 512. If the length of the sentence exceeds 512, it is truncated. The encoded sentences are then processed to yield contextually rich pre-trained embeddings which are passed through the ALBERT transformer (TFAlbertForSequenceClassification) followed by a Dropout, Flatten and two Dense Layers.
We used a sigmoid activation function for the final dense layer. The sigmoid function is used in this multilabel classification problem because the probabilities produced by a sigmoid function are independent, and are not constrained to sum to 1.0. That’s because the sigmoid function looks at each raw output value separately and thus it’s the optimal activation function of a multilabel classification problem.
The preprocessed data was passed through a classification model, the architecture of which is defined above. We used Adam Optimiser with learning rate equal to 0.00001, loss function equal to Binary Cross Entropy Loss and batch size equal to 8. Class weights were set while fitting the model on the training data. We focused primarily on ‘F1 micro’ in this subtask. The model was run for 400 epochs.