ARTEMIS-2945 Artemis native JNI code can be replaced by Java #10
Conversation
|
This the results from running a bench with 2000 clients (1000 producers 1000 consumers 1000 queues) on a Troughput seems a bit increased and latency are a bit lower, I'm going to try with different number of clients to check if it's still true |
|
I've tested with 2-20 and 200 clients getting the same: this branch seems on par with |
|
To note, I've been testing this branch against master using an independent test rig with large real servers we use. And it corroborate the above stats, we are seeing in most parts no perf difference. As raised privately to Franz but putting it here for public. Synthetic performance != real use cases. I would suggest whilst we switch ASYNCIO over to this newer implementation, we should add another configuration ASYNCIO_LEGACY for a few releases so if anyone does see a perf drop in real usecases they can switch back to the legacy jni one quickly. And report the issue |
022523d to
119b367
Compare
This is a great suggestion indeed, taken! |
|
@michaelandrepearce
Differently from my expectation isn't the
This could be improved by using a better Thread pool queue (see https://issues.apache.org/jira/browse/ARTEMIS-2240), but the risk is that the a faster Another interesting point to observe is the There are few things that doesn't look right to me:
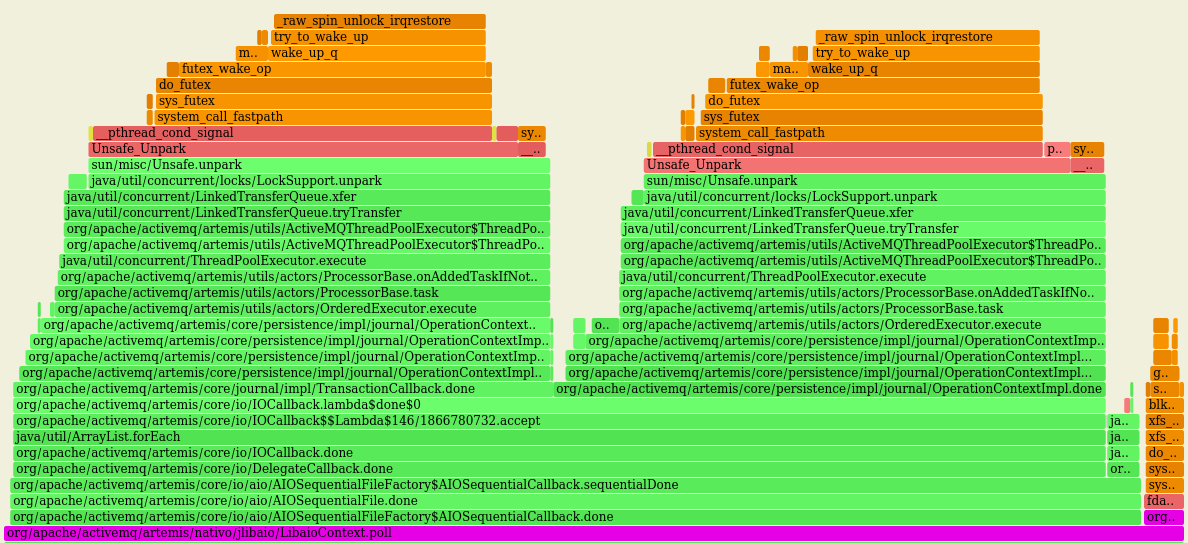
The latter 2 ones are competing over OS resources for the sole purpose of wake up someone (ie who call |



|
@michaelandrepearce
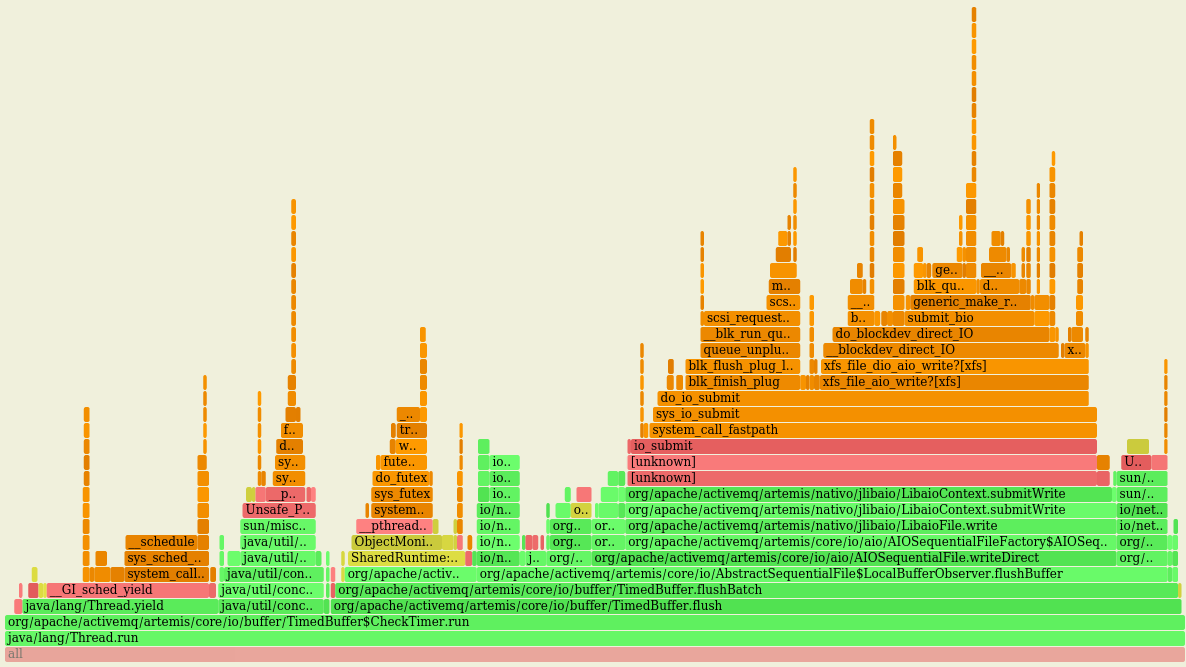
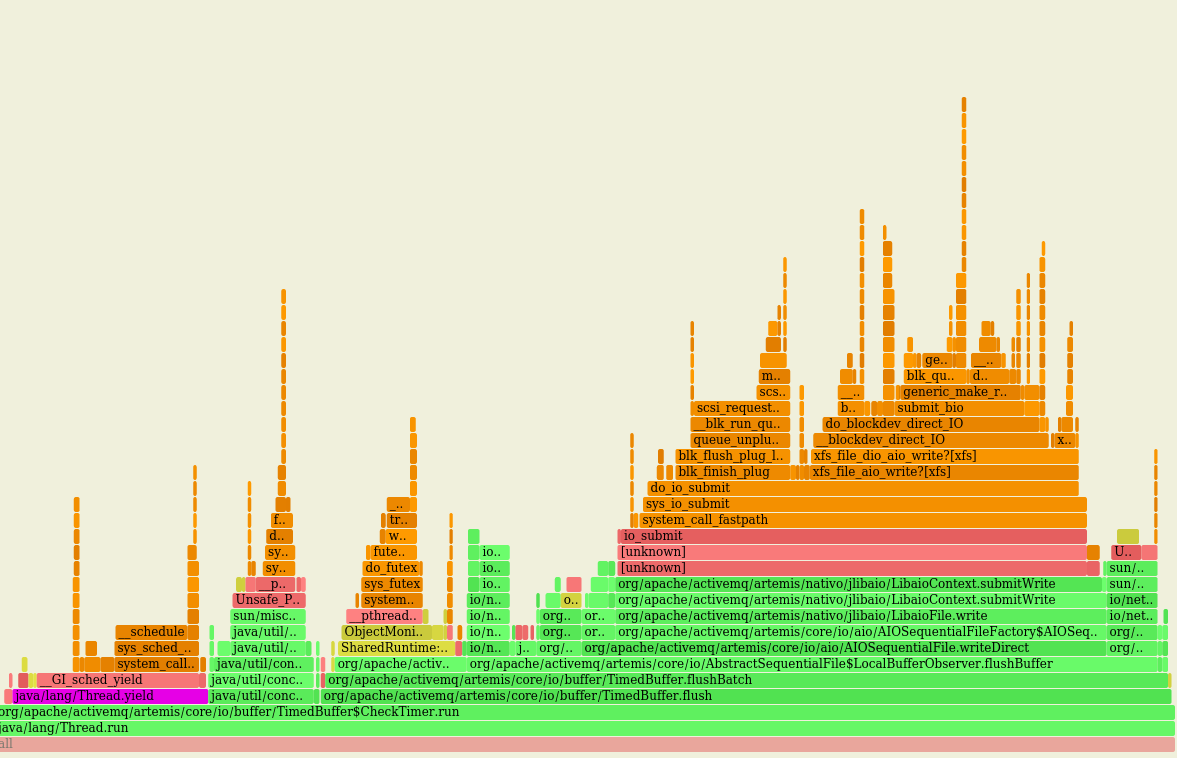
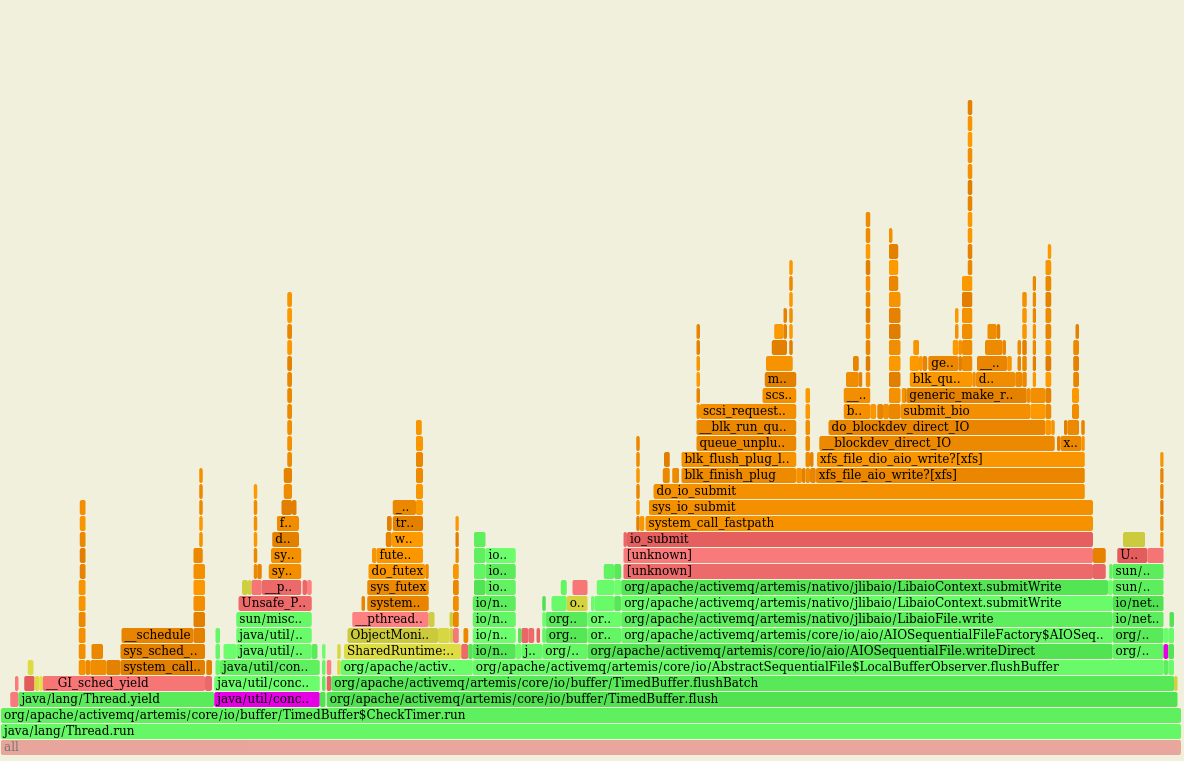
That seems to me that most of the time of this loop is spent by submitting tasks to awake threads of the pool, something that doesn't feel right to me... Although this I'm getting overall better performance, the impact, CPU-wise, of using such queue is high (LTQ in violet): vs the original behaviour with LBQ (in violet as well): On a fresh run of this PR on the same machine I got: While, after switching to LTQ: Troughput is marginally increased (< 1%) while the CPU usage has increased a lot ie +~25% |
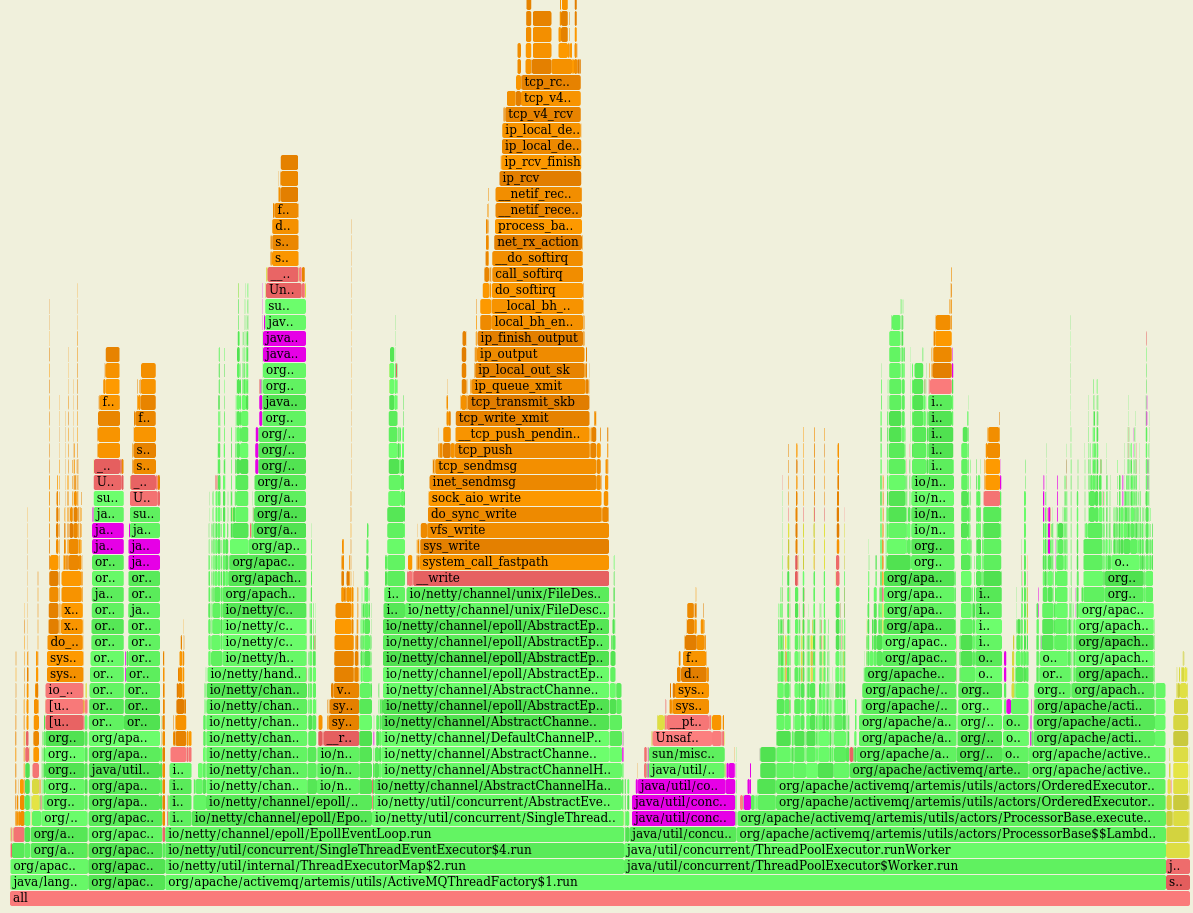
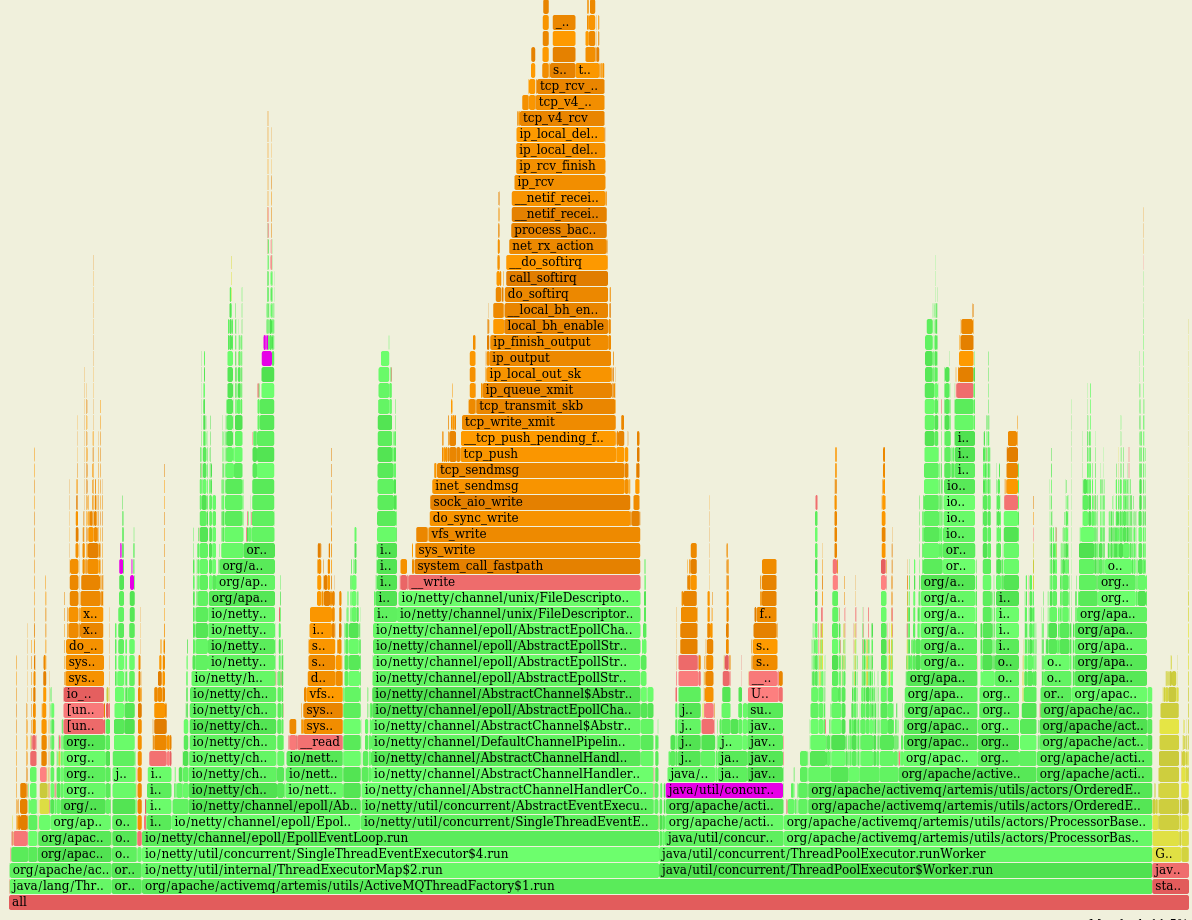
|
this is replaced by #14 |
That's an alternative of #9 that focus on closing the gap with the original implementation in C and that's just 1:1 with the original version in term of internal behaviour