This is a slightly modified version of sherjilozair/char-rnn-tensorflow we used for a class project on Neural Net Methods to train the machine to generate Wikipedia-style descriptions of video games. This project is completed by Kyle Gonzalez, Cassandra Ravenbrook, and Anya Osborne. It represents the Multi-layer Recurrent Neural Networks (LSTM, RNN) for character-level language models in Python using Tensorflow. The original inspiation comes from Andrej Karpathy's char-rnn. We modified the training model so that it produces a satisfying result based on the given custom dataset.
The project was executed on Windows 10 64x, using Anaconda environments, utilizing NVIDIA GPU. Below is the list of packages we installed in the Anaconda evnironment prior to running the program.
- TensorFlow 1.15.0 (tensorflow-gpu==1.15) - We used the following installation guide - Anaconda TensorFlow.
- Install pip - We used pip 21.0.1
- Python 3+ - We used Python 3.7.9, but it can work with 2.7, 3.6, 3.5, and 3.4.
- Install numpy into your environment. The version we used is 1.20.0. Here is a guide on Installing NUMPY.
- Lastly, you will likely need to install six 1.15.0. Six is a Python 2 and 3 compatability library to smooth the differences between the Python versions.
- To train, run train.py. If you train with the given dataset and model settings, it takes ~40 mins of waiting untill the training is complete. The command to run the training is
python train.py(make sure the path in the evnironment is correct). To access all the parameters usepython train.py --help. - In result of training, it will create new logs, checkpoints and vocabulary in the save and games folders.
- The sample output is generated from the saved checkpoints. To receive one, run
python sample.py. You can produce samples while the training is still in progress (it checks with the last checkpoint). However, it works only in CPU or using another GPU. To force CPU mode, useexport CUDA_VISIBLE_DEVICES=""andunset CUDA_VISIBLE_DEVICESafterward (resp.set CUDA_VISIBLE_DEVICES=""andset CUDA_VISIBLE_DEVICES=on Windows). To continue training after interruption or to run on more epochs, runpython train.py --init_from=save.
You can use any plain text file as input. In this project, we used the output text generated from our Wikipedia-Text-Extractor-Games that includes 110 game descriptions extracted from Wikipedia as a plain text file.
There multiple ways you can tweak the training model to experiement with the output results.
- You can start with cleaning the input.txt to as much as possible (e.g. we removed unnessary symbols, line spaces, headings, etc.)
- Use Tensorboard to compare all of your runs visually to aid in experimenting (see more info below).
- Tweak
--rnn_sizeto somewhat from 128 if you have a lot of input data. We've got a large input file, so our--rnn_sizewas 400. - Tweak
--num_layersfrom 2 to 3 but it is recommended no higher unless you have experience (e.g. we used 3 layers). - Tweak
--seq_lengthup from 50 based on the length of a valid input string. In our input we used sentenced, so we set it up to 64 characters. For names, you can use <=12 characters. An lstm cell will "remember" for durations longer than this sequence, but the effect falls off for longer character distances. - Once you've done all that, you can add some dropout. Start with
--output_rate 0.8and maybe end up with both--input_rate 0.8--output_rate 0.5only after exhausting all the above values.
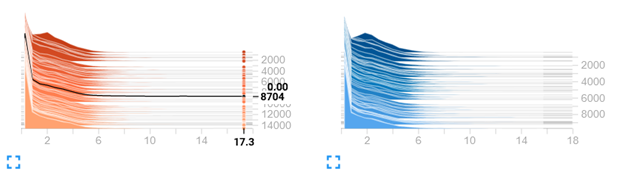
When experimenting with tweaking the training model, it is helpful to visualize the process in Tensoboard. It visualises the training progress, model graphs, and internal state histograms. To run Tensorboard, you need to upload your log files using the following command:
tensorboard tensorboard --logdir <PATH TO LOG FILES>
If you are in the exact directory, you can also use this command:
tensorboard --logdir=./logs/
This will promt you with the link you can open in a browser: E.g. http://localhost:6006 or the correct IP/Port specified. Here are some examples of our Tensoboard histograms.
{kind=link}
Here are some examples of samples we got based on various modifications completed to the training model.
This one is based on full descriptions of 110 games:
can only direct story moming out of Game of the game is a villuse "the test dead in to the form, while they had screen is not how they have blog to the class, a moving months atcess that they could be reward the Campaigoni (on Otton 64 and BioShock 2 was the pastof Japan better up at the same you began your ball of set in the game not this game to terms in hosper been "itsumes the besout to sporce the live across the lawmens of the Computing them their story, the use the game's best launchers,>
In experimenting with the input file, we decided to use a shorter version with a repetitive vocabulary. We extracted Wikipedia text from the gameplay section only about puzzle games GameplayPuzzles. Here is the sample we received:
eS as wincso gayele ur the ol the bomverd To wall bzuyecs ivqcim the the morcsaald Czosrte megmere spocler erint sening or dere. thing a saxo fupsaic bactor the an cleecutes theberes. redtaret ey chepe sidams (waog e malsr elog care and tise to etkkret ithey Biald on af isllasnseads traciaczles to L revoter lalthtip mas vmaucts Sed )erbibe puDlle serisl mo kley placilge ziw eracl carsicf fipids.sdith the te gker somt.s fiwe semdith ix Goces molings the mond thse cacpes bales on fom silh a whel
The train loss during this experiment turned out to be pretty high, so we decided to return to the initial input file.
In this round of experiments, we used the AllGameDescriptions as an input and started getting satisfying results:
In versions art rounds has unearcom, a DICE back to menuge his appeared by several development in the game items not version of the success of the world survivorn-appear uses thatat Make and Ark the top invediethland. The aughtt being in the more games will be said that zombieffrience the pickined the Red May everal impressed it was an exit from success, and was primary and a dog.
had previous installments, including Square Enix. Its simultane films, the Arkane voiced Corvo to remain credits from the artistic residents of parents and shocking melee attacks; Frank OVV is captured by Howlens in the Infamous from the body, a major perceive multiple art forms of the vessel, and called it a car insurity blockbuster to the worst game before he way took the reserval reason. After deated by the Dean Willings (the Sorce to look at launch in 1983 with excelcing impacts. It is playa
included Luke System, ATMA-LITI games released the Quantian 1 Up Studios. It featured characters and audio and God of War I and God of War II and God of War IV the developer map Official Nintendo LoPa (a President changed the Special Acrobatic DLC) who previously not years led to develop.The game's concept for CandySwipe wroth that the original books was released worldwide on March 6, 2010 by Synergistic Byramightwaction film, Opener and Story, Laos Dea Yestwaure, China and Sony Clarke. Benjamor
Here is more examples of samples we received - Sample Output.