The SemEval 2017 Task 10 deals with automatic extraction of keyphrases from Computer Science, Material Sciences and Physics publications, as well as extracting types of keyphrases and relations between keyphrases.
In this project, I have implemented a Bi-LSTM + CRF model to do an end-to-end classification and recognition of keywords.
SemEval 2017 ScienceIE corpus consists of 500 journal articles evenly distributed among the domains Computer Science, Material Sciences and Physics. The corpus consists of 350 documents for training, 50 for development and 100 for testing. The keywords are classified into three categories: TASK, PROCESS and MATERIAL.
- Text data corresponding to each article in the corpus is processed to get a list of tokens and their corresponding POS tagging using spaCy python library.
- Before passing the input through the model, the lists are converted into integer sequences, and the resulting sequences are padded to ensure that all sequences are the same length.
- IOB label scheme is used to generate the output label sequence. To distinguish different type of keywords the output label for each token is appended with correpsonding keyword type. For example, for a TASK type keyword the output label will look like B_Task and I_Task.
Code for data preprocessing can be found in file Data_Processing.ipynb
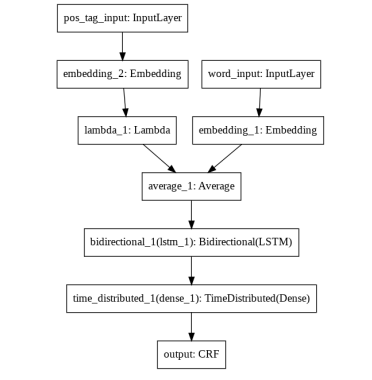
To train the model, the token and POS tagging sequences obtained after data preprocessing are passed through separate embedding layers. The weighted average of the output, with high weightage to POS Tag, is passed through a Bidirectional LSTM layer of 20 units. The results of the forward LSTM and the backward LSTM are concatenated and fed into a Time Distributed Dense Layer with softmax activation function. The output of the Dense layer is then passed through a CRF layer to predict the output label sequence.
Code for model training and testing can be found in file Bi_LSTM_CRF.ipynb
The below image shows model performance on a random paper selected from the domain of material science. The model appears to detect the majority of the main keyphrases such as material science, novel therapeutic treatment, and selective drug delivery.

The selected paper can be found here