A lot of work has been done in the field of anomaly detection especially in the field of cyber security and medical diagnosis. But, due to the ever-increasing threats to human health and network systems, it
is difficult to identify these.
As a part of comparative analysis, I have implemented couple of algorithms on each dataset so as to come up with some modifications in parameters
and conditions in order to optimize the classification model.
I implemented the work done in the following paper to enhance the performance of One-class Support Vector Machine on the datasets.
http://met.guc.edu.eg/Repository/Faculty/Publications/479/One-class-SVM_anomaly-detection.pdf
The datasets used in this project are KDD Unsupervised dataset (network intrusion detection) and Breast cancer
dataset (Breast cancer diagnostics).
Maintaining uniformity in data -
The instances consist of various data types of feature values which might pose a problem where our algorithms will
need to work with numeric values for mathematical equations. Therefore, the initial step of pre-processing data is to
convert all the feature values into uniform type. Textual characters and alphanumeric values are converted into
numeric values for data uniformity for mathematical calculations.
Normalization of data -
The next step in pre-processing data is normalization of instances in order to avoid larger computational costs and
scale the values in order to achieve efficient weights and values.
RandomForest -
RandomForest is a collection of decision trees where the dataset is divided randomly and each subset is fed
to every decision tree. The trees fit the data and intuitively, each decision tree provides weights to features and vote
the features according to their relevance and importance. The majority voted features among these are considered to
be highly discriminating features amongst others.
RandomForests can compress very high amount of data and can deliver high quality models. As this uses a number of
trees for data fitting, it is very quick to train.
Principle component analysis -
PCA measures the data based on the principle components instead of basis vectors. It is a dimensionality
reduction technique where projections of all data points is taken on vector that has unique representation for each point
and maximizes variance.
In our implementation, we have used Gaussian Radial Base Function (RBF).
Imagine a factory type of setting; heavy machinery under constant surveillance of some advanced system. The task of
the controlling system is to determine when something goes wrong; the products are below quality, the machine
produces strange vibrations or something like a temperature that rises. It is relatively easy to gather training data of
situations that are OK; it is just the normal production situation. But on the other side, collection example data of a
faulty system state can be rather expensive, or just impossible. If a faulty system state could be simulated, there is no
way to guarantee that all the faulty states are simulated and thus recognized in a traditional two-class problem.
To cope with this problem, one-class classification problems (and solutions) are introduced. By just providing the
normal training data, an algorithm creates a (representational) model of this data. If newly encountered data is too
different, according to some measurement, from this model, it is labeled as out-of-class.
The results are as follows:
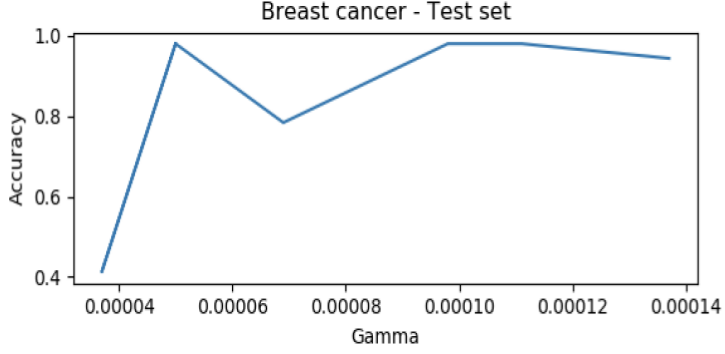
Eta One Class SVM is an approach that was introduced to tackle the challenge that outliers do significantly contribute to the decision boundary. It is more robust against the noise in the training datasets. It has an advantage of maintaining the sparsity of SVM solution.
- Python 2.6 and above (Python 2.7.5 using)
- Using numpy, matplotlib, scipy, tensorflow, time, math, pandas and scipy third-party library
- Just type "python XXX.py" XXX is the python file name.
- The commented lines are the dubugging commands used for developing.