IEEE Papers Mapper is a comprehensive tool for retrieving, processing, classifying, and visualizing research papers from the IEEE Xplore API. It automates data ingestion, applies machine learning for classification, and offers interactive dashboards for insights.






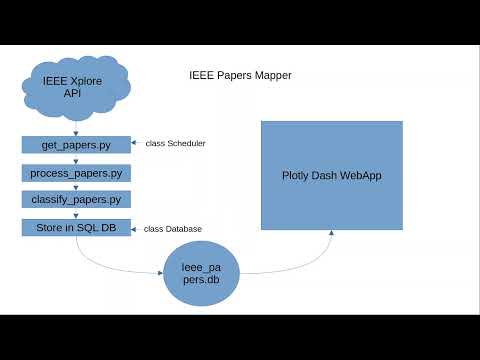
The IEEE Papers Mapper is a comprehensive pipeline designed to automate the retrieval, processing, classification, and visualization of academic papers sourced from the IEEE Xplore digital library. This tool streamlines research management by automatically fetching papers based on user-defined queries, preprocessing the raw data to extract key metadata, and employing an encoder-only machine learning model to classify papers into predefined categories. The results are stored in a robust SQLite database and visualized through a Plotly Dash web app. The project integrates APScheduler for scheduled data retrieval, ensuring that the pipeline remains up-to-date. It is highly configurable, allowing users to define custom thresholds, categories, and schedules, making it a valuable resource for researchers and data professionals aiming to organize vast volumes of academic literature efficiently.
- Automated Data Retrieval: Scheduled fetching of research papers using APScheduler.
- Data Processing: Cleans, formats, and prepares data for analysis.
- Machine Learning Classification: Zero-shot classification using transformer models.
- Interactive Dashboard: Visualize categorized papers and insights using Plotly Dash.
- Python 3.12+
- Virtual Environment (optional but recommended)
- Required tools: pip, git
-
Create a project directory:
mkdir ~/workspace/my_project cd ~/workspace/my_project
-
Create and activate a virtual environment:
python3 -m venv venv source venv/bin/activate # For Linux/Mac venv\Scripts\activate # For Windows
-
Install the
pippackage and start using it at will:pip install ieee-papers-mapper
-
Clone the repository
git clone https://github.com/alex-anast/ieee-papers-mapper.git cd ieee-papers-mapper -
Create and activate a virtual environment:
python3 -m venv venv source venv/bin/activate # For Linux/Mac venv\Scripts\activate # For Windows
-
Install the required packages:
pip install -r requirements.txt
-
Install the package locally:
pip install .
To launch the dashboard, run:
python ieee_papers_mapper/app/dash_webapp.pyVisit http://localhost:8050 to view the dashboard.
To run the pipeline of retrieving, processing and classifying the papers automatically, execute:
python ieee_papers_mapper/main.py --days 1NOTE: Currently the scheduler is commented out. The pipeline runs must be executed manually.
- Data Retrieval: Automatically fetches new papers based on categories from IEEE Xplore.
- Data Processing: Handles missing columns and formats data for classification.
- Classification: Uses a DeBERTa-v3 model for zero-shot classification into predefined categories.
- Data Storage: Uses SQLite3 for storing the data in an SQL database (scalability, modularity over CSV files).
Complete documentation is available at: https://alex-anast.com/ieee-papers-mapper/
./ieee-pappers-mapper
├── conftest.py
├── docs # MkDocs
│ ├── about.md
│ ├── developer_guide
│ │ ├── api_reference.md
│ │ └── code_structure.md
│ ├── index.md
│ └── user_guide
│ ├── installation.md
│ ├── overview.md
│ └── usage.md
├── LICENSE
├── mkdocs.yml # MkDocs config
├── pyproject.toml
├── README.md
├── requirements.txt
├── setup.py
├── src
│ └── ieee_papers_mapper
│ ├── app # Web App (plotly dash)
│ │ ├── assets
│ │ │ └── styles.css
│ │ ├── callbacks.py
│ │ ├── dash_webapp.py
│ │ └── __init__.py
│ ├── config # Config and util files
│ │ ├── config.py
│ │ ├── progress.json
│ │ └── scheduler.py # Custom scheduler wrapper class
│ ├── data
│ │ ├── classify_papers.py # Classification
│ │ ├── database.py # Custom Database wrapper class
│ │ ├── get_papers.py # Paper retrieval
│ │ ├── __init__.py
│ │ ├── pipeline.py # Pipeline actions
│ │ └── process_papers.py # Paper (pre)processing
│ ├── ieee_papers.db
│ ├── __init__.py
│ └── main.py
└── tests
├── __init__.py
├── test_classify_papers.py
├── test_database.py
├── test_get_papers.py
└── test_process_papers.pyRun the tests with:
python -m pytest
- get_papers.py: Validates API integration and error handling.
- process_papers.py: Ensures data cleaning and formatting.
- classify_papers.py: Verifies ML classification accuracy and runtime performance.
- database.py: Checks database initialization and CRUD operations.
- Fork the repository and submit a pull request.
- Adhere to PEP 8 code style.
- Include unit tests for new core functionality.
- Lint with
blackformatter.
- Currently
author index termsis not consistent, and therefore commented out. Fix. - Scheduler is not enabled.
- Add more advanced ML models for classification.
- Enhance the dashboard with dynamic filtering.
-
Introduce versioning and a changelog. See if this can be automated
-
TESTS -- test everything, especially the core parts: unit and integration tests
-
Set up CI in github when tests are ready
-
Make it deployable with Docker
-
Use terraform Infrastructure-as-Code (IaC) to define the cloud infra needed. This would include a database instance, a container orchestration service, and the necessary networking and security groups.
-
Deploy to the cloud (yes you will have to pay a little. See if you can use your own website.
-
Replace SQLite with something used in prod. Probably PostgreSQL. Explain why this change.
-
Refactor the pipeline from a single script into a more robust, event-driven architecture.
- Instead of a monolithic
run_pipelinefunction, break it into discrete services that communicate via a message queue - Fetcher Service, Processing Service, Classifier Service. This is like a DAG -- maybe it's time to apply graph theory and data engineering skills here.
- [ ]
- Instead of a monolithic
-
Data Validation (data quality) (Pydantic): Before inserting to the database, it must conform to an expected schema (e.g.,
publication_yearis a valid year,titleis a non-empty string). -
Configure your logger to output logs in JSON format
-
In the cloud, ship these logs to a centralised logging service and be able to see them online
-
Add monitoring (maybe with Grafana) -- dashboards -- eg:
papers_processed_per_minute,api_error_rate, andclassification_time_seconds -
Move hidden env vars from
.envto dedicated secrets management service. The application should fetch the secret at runtime. -
Create design docs that are verbose and detailed. This is easy, use gemini and make sure you capture all the core system design decisions. You have to include diagrams
These make the whole app a very robust product. Anything else is more ML engineering. Some more abstract ideas are given below:
- Feed each retrieved paper in a paid, good LLM for data labelling to create a comprehensive dataset
- Experiment with different techniques via a notebook on how to classify as best as I can. Yes the pretrained model could work, but I am wondering if it would be interesting to work with SVMs (considering the low amount of data) and give a real-time classification capability
- I wonder if vectorisation and RAG could help here in any way. Maybe a north star could be some type of optimised retrieval, in the sense that we make our own database and then Q&A so that we can discuss based on the papers that have been already classified.
Limited to 20 API calls/day and to max 200 papers/call, due to IEEE Xplore API restrictions.
This project is licensed under the MIT License. See the LICENSE file for details.
- Owner: Alexandros Anastasiou
- Email: anastasioyaa@gmail.com
- Website: TODO
- LinkedIn: TODO