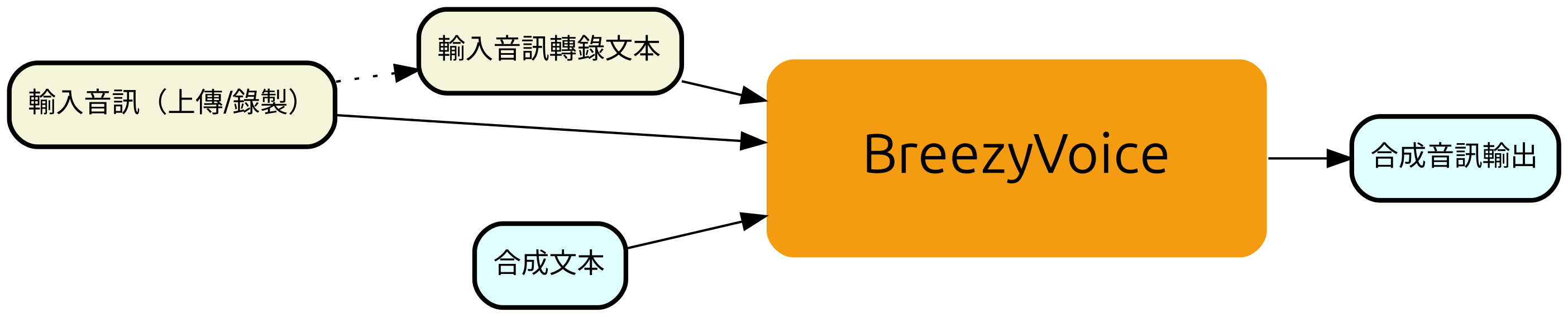
BreezyVoice is a voice-cloning text-to-speech system specifically adapted for Taiwanese Mandarin, highlighting phonetic control abilities via auxiliary 注音 (bopomofo) inputs. BreezyVoice is partially derived from CosyVoice. BreezyVoice is part of the Breeze2 family
🚀 Try out our interactive UI playground now! 🚀
🚀 立即體驗 BreezyVoice 語音合成 ! 🚀
Or visit one of these resources:
Repo Main Contributors: Chia-Chun Lin, Chan-Jan Hsu
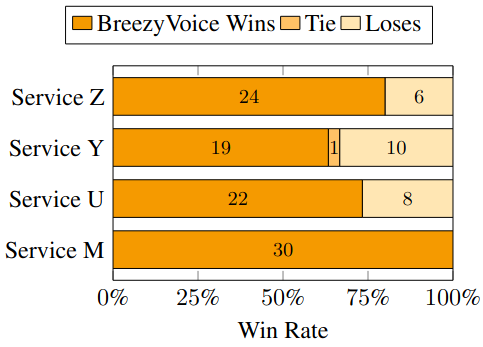
🔥 BreezyVoice outperforms competing commercial services in terms of naturalness.
🔥 BreezyVoice is highly competitive at code-switching scenarios.
| Code-Switching Term Category | BreezyVoice | Z | Y | U | M |
|---|---|---|---|---|---|
| General Words | 8 | 5 | 8 | 8 | 7 |
| Entities | 9 | 6 | 4 | 7 | 4 |
| Abbreviations | 9 | 8 | 6 | 6 | 7 |
| Toponyms | 3 | 3 | 7 | 3 | 4 |
| Full Sentences | 7 | 7 | 8 | 5 | 3 |
🔥 BreezyVoice supports automatic 注音 annotation, as well as manual 注音 correction (See Inference).
Clone and install
- Clone the repo
git clone https://github.com/mtkresearch/BreezyVoice.git
# If you failed to clone submodule due to network failures, please run following command until success
cd BreezyVoice- Install Requirements (requires Python3.10)
pip uninstall onnxruntime # use onnxruntime-gpu instead of onnxruntime
pip install -r requirements.txt
(The model is runnable on CPU, please change onnxruntime-gpu to onnxruntime in requirements.txt if you do not have GPU in your environment)
You might need to install cudnn depending on cuda version
sudo apt-get -y install cudnn9-cuda-11
UTF8 encoding is required:
export PYTHONUTF8=1Run single_inference.py with the following arguments:
-
--content_to_synthesize:- Description: Specifies the content that will be synthesized into speech. Phonetic symbols can optionally be included but should be used sparingly, as shown in the examples below:
- Simple text:
"今天天氣真好" - Text with phonetic symbols:
"今天天氣真好[:ㄏㄠ3]"
-
--speaker_prompt_audio_path:- Description: Specifies the path to the prompt speech audio file for setting the style of the speaker. Use your custom audio file or our example file:
- Example audio:
./data/tc_speaker.wav
- Example audio:
- Description: Specifies the path to the prompt speech audio file for setting the style of the speaker. Use your custom audio file or our example file:
-
--speaker_prompt_text_transcription(optional):- Description: Specifies the transcription of the speaker prompt audio. Providing this input is highly recommended for better accuracy. If not provided, the system will automatically transcribe the audio using Whisper.
- Example text for the audio file:
"在密碼學中,加密是將明文資訊改變為難以讀取的密文內容,使之不可讀的方法。"
-
--output_path(optional):- Description: Specifies the name and path for the output
.wavfile. If not provided, the default path is used. - Default Value:
results/output.wav - Example:
[your_file_name].wav
- Description: Specifies the name and path for the output
-
--model_path(optional):- Description: Specifies the pre-trained model used for speech synthesis.
- Default Value:
MediaTek-Research/BreezyVoice
Example Usage:
bash run_single_inference.sh# python single_inference.py --text_to_speech [text to be converted into audio] --text_prompt [the prompt of that audio file] --audio_path [reference audio file]
python single_inference.py --content_to_synthesize "今天天氣真好" --speaker_prompt_text_transcription "在密碼學中,加密是將明文資訊改變為難以讀取的密文內容,使之不可讀的方法。" --speaker_prompt_audio_path "./data/example.wav"# python single_inference.py --text_to_speech [text to be converted into audio] --audio_path [reference audio file]
python single_inference.py --content_to_synthesize "今天天氣真好[:ㄏㄠ3]" --speaker_prompt_audio_path "./data/example.wav"Run batch_inference.py with the following arguments:
-
--csv_file:- Description: Path to the CSV file that contains the input data for batch processing.
- Example:
./data/batch_files.csv
-
--speaker_prompt_audio_folder:- Description: Path to the folder containing the speaker prompt audio files. The files in this folder are used to set the style of the speaker for each synthesis task.
- Example:
./data
-
--output_audio_folder:- Description: Path to the folder where the output audio files will be saved. Each processed row in the CSV will result in a synthesized audio file stored in this folder.
- Example:
./results
CSV File Structure:
The CSV file should contain the following columns:
-
speaker_prompt_audio_filename:- Description: The filename (without extension) of the speaker prompt audio file that will be used to guide the style of the generated speech.
- Example:
example
-
speaker_prompt_text_transcription:- Description: The transcription of the speaker prompt audio. This field is optional but highly recommended to improve transcription accuracy. If not provided, the system will attempt to transcribe the audio using Whisper.
- Example:
"在密碼學中,加密是將明文資訊改變為難以讀取的密文內容,使之不可讀的方法。"
-
content_to_synthesize:- Description: The content that will be synthesized into speech. You can include phonetic symbols if needed, though they should be used sparingly.
- Example:
"今天天氣真好"
-
output_audio_filename:- Description: The filename (without extension) for the generated output audio. The audio will be saved as a
.wavfile in the output folder. - Example:
output
- Description: The filename (without extension) for the generated output audio. The audio will be saved as a
Example Usage:
bash run_batch_inference.shpython batch_inference.py \
--csv_file ./data/batch_files.csv \
--speaker_prompt_audio_folder ./data \
--output_audio_folder ./resultsIf you like our work, please cite:
@article{hsu2025breezyvoice,
title={BreezyVoice: Adapting TTS for Taiwanese Mandarin with Enhanced Polyphone Disambiguation--Challenges and Insights},
author={Hsu, Chan-Jan and Lin, Yi-Cheng and Lin, Chia-Chun and Chen, Wei-Chih and Chung, Ho Lam and Li, Chen-An and Chen, Yi-Chang and Yu, Chien-Yu and Lee, Ming-Ji and Chen, Chien-Cheng and others},
journal={arXiv preprint arXiv:2501.17790},
year={2025}
}
@article{hsu2025breeze,
title={The Breeze 2 Herd of Models: Traditional Chinese LLMs Based on Llama with Vision-Aware and Function-Calling Capabilities},
author={Hsu, Chan-Jan and Liu, Chia-Sheng and Chen, Meng-Hsi and Chen, Muxi and Hsu, Po-Chun and Chen, Yi-Chang and Shiu, Da-Shan},
journal={arXiv preprint arXiv:2501.13921},
year={2025}
}
@article{du2024cosyvoice,
title={Cosyvoice: A scalable multilingual zero-shot text-to-speech synthesizer based on supervised semantic tokens},
author={Du, Zhihao and Chen, Qian and Zhang, Shiliang and Hu, Kai and Lu, Heng and Yang, Yexin and Hu, Hangrui and Zheng, Siqi and Gu, Yue and Ma, Ziyang and others},
journal={arXiv preprint arXiv:2407.05407},
year={2024}
}