Plan
Raw video stream -> Activity Detection Stack -> ROAD Dataset evaluation-compatible output / Env modelling compatible-output (later).
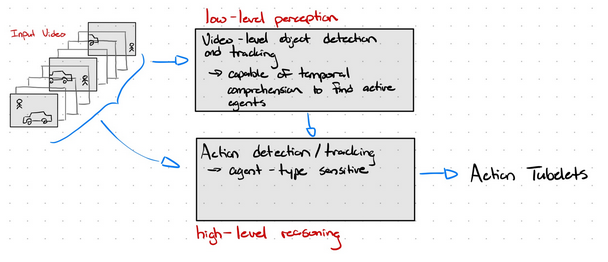
Model capable of comprehending and generating low-level attributes. In this case, the locations (whatever form accepted by action detector) of active agents and their types (car, pedestrian, etc.).
- Should be capable of temporal comprehension for the sake of finding active/inactive agents
- Should be relatively efficient: more for when we want to integrate into the car, also because this space is relatively mature enough to be pretty efficient in the first place. Don't want to revert backwards too much.
Model capable of fully comprehending low-level attributes and generating action classifications (post-processing may be needed to adapt the predictions into action tubelets which ROAD want).
- Ideally should spend a majority of its computing power on just action classification
- Avoid giving this model the work from low-level perception
- No information from low-level perception should go to waste!
These connections represent the flow of data through the network.
- Json format
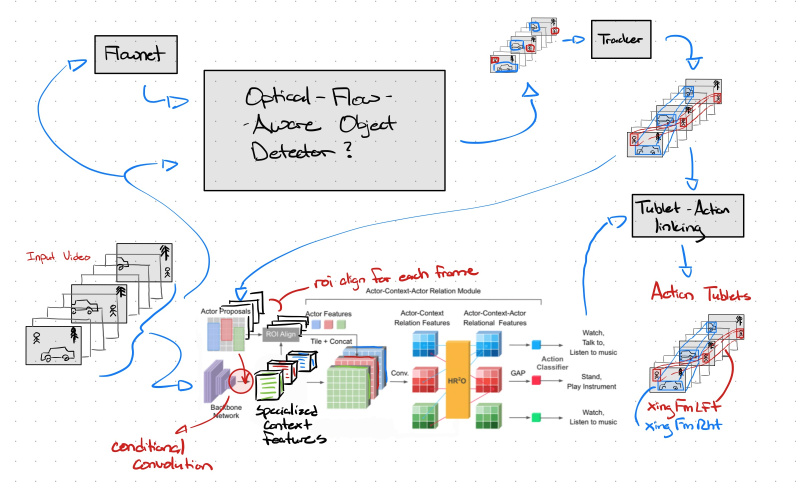
This is the overall architecture of the detection stack as of writing. Subject to change.
-
Video-Level object detectors are rather inefficient and complex, we may be able to give the network enough temporal understanding via optical flow. This approach is relatively efficient (39 fps supposedly), and we may remove the need for explicit foreground segmentation.
-
Tracking is still in progress. For now, we can test our changes to the object detection stack via the old implementation of ACAR (accepting a key_frame). Once active/inactive is dealt with, we can begin to connect boxes in a clip with some tracker and thus come up with tube proposals for tube ACAR.
-
https://mrrobot313.notion.site/Motion-foreground-Segmentation-20145bf5c6df462daff71354d3a7e485
- Tube ACAR has shown some promise (34 -> 37% mAP) and combining this with our loss changes could maybe bring its accuracy even higher.
- ACAR's agent awareness is a possible next step. ACAR will become considerate of agent classes which could lead to more patterns between an roi and its action (eg. a TL roi could be more closely related to the color actions red, green, amber).
- On the back-burner but still worth considering: ACAR's ACFB, this could give ACAR the ability to account for data beyond the 32 frames it is given (well actually 91 cropped down to 32). MeMViT has shown some interesting findings in giving a network long-term memory, perhaps we should follow with this memory idea? Memory compression for the ACFB could be interesting...
- Maybe take a look at a video transformer?
As of writing, these connections are simply data files of JSON annotations being shared between the tail and head networks.
- It may be worth exploring other ways to send data between the high-level and low-level networks (and other parts as well).
- An example would be connecting up the tensors from each of the networks in such a way to make end-to-end training and inference possible.
SUBJECT TO CHANGE, but perhaps we should take a look into changing around ACAR to produce annotations in a separate mode. We can create a eval script that closely resembles (or is) the evaluation script of the ROAD challenge.