IoT aggregation server
Разберем пример варианта применения сервера на базе автоматизации ухода за абстрактным полем с засеянным абстрактной культурой.
- Strix Sensor - собирает данные и отсылает их через технологическую сеть
- Strix Gateway - транспортирует данные с технологической сети на облако
- Strix Cloud - агрегирует, сохраняет и визуализирует данные
В первой итерации сенсор предстваляет собой полый штырь (возможно телескопической конструкции) высотой выше культуры для которой предназначен. А также имеющий герметичную штыревую часть погружаемую в грунт на 1-1.5 м. называемую "датчик параметров грунта". Пока видим вариант что штыри расставляются по сторонам поля. Также для оптимизации затрат можно делать вариант штыря с "хабом" для N датчиков параметров грунта.
На внешней части в самом верху расположен LORA модуль передачи данных, а также должны присутствовать датчики:
- освещенности
- температуры
- влажности
- скорости и направления ветра
- GPS/ГЛОНАС (чтобы датчики автоматически привязывались на карте)
На датчике параметров грунта присутствуют:
- температуры через каждые N см. (для получения среза температур грунта)
- влажности грунта
- нитратометр (ионоселективный электрод или измерение проводимости + таблица значений, как в бытовых нитратометрах)
Для соблюдения законов РФ, необходимо предоставлять все оборудование в собственность клиенту как часть комплексной услуги по мониторингу. Также сеть передачи данных во всех документах должна проходить как исключительно технологическая сеть. Дальность технологической сети LORA 5-15 км, топология "Сота". Частотный план радиомодема должен включать только разреженный в данной локации диапазон частот, такт например для РФ это RU868 (в дальнейшем EU868, IN865, AS923, AU915, KR920, US915, KZ865). Также для использования на территории РФ необходимо получить на Strix Gatway и Strix Sensor декларацию о соответствии требованиям технического регламента Таможенного союза "Электромагнитная совместимость технических средств" (ТП ТС 020/2011), вопрос уточняется.
Всю работу по агрегации, хранению и визуализации данных выполняет облако.
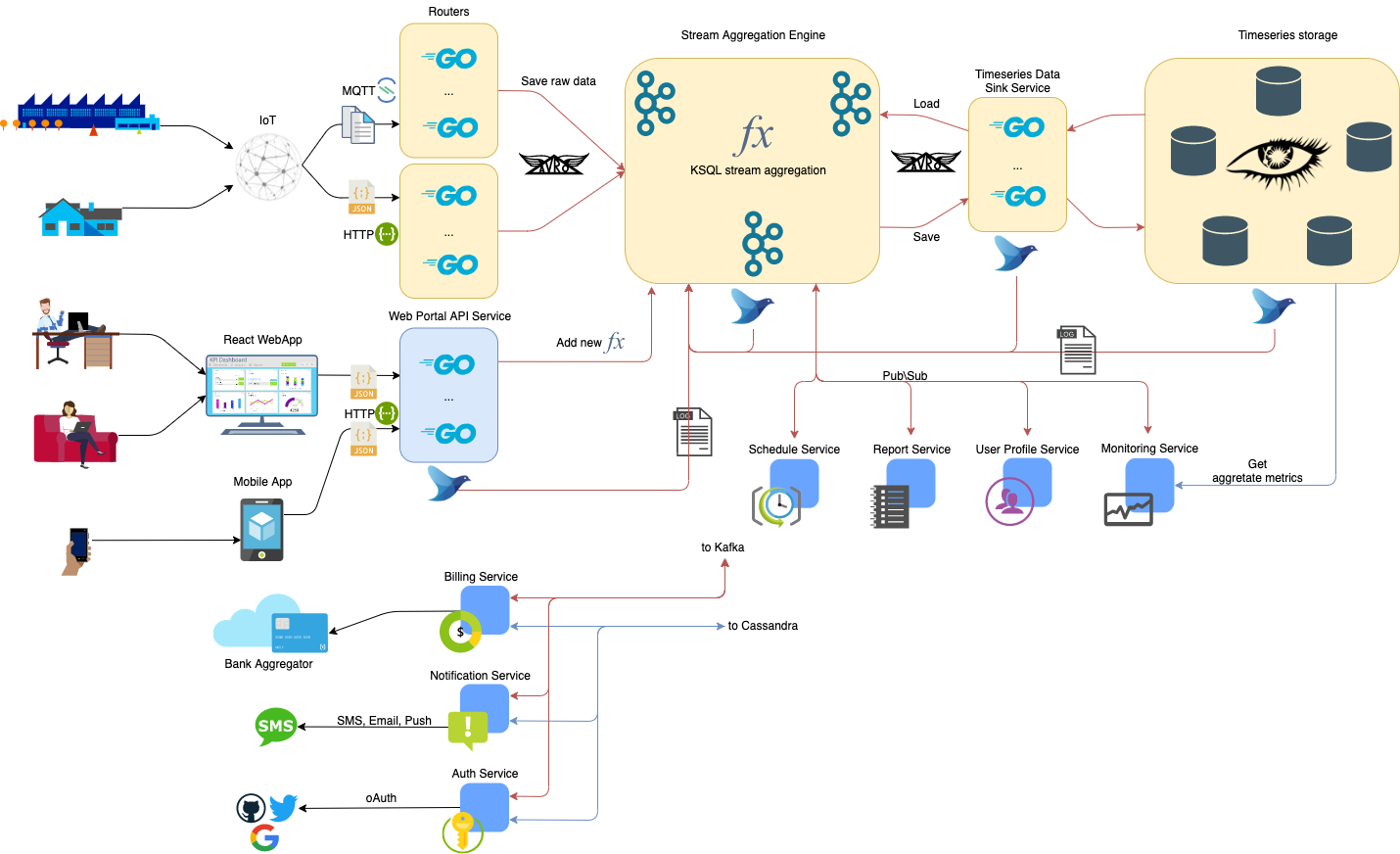
Компоненты облака:
Данные через сеть Интернет принимают две группы роутеров. Первая группа обеспечивает прием данных по HTTP REST API, интерфейс описан в Swagger спецификации. Вторая группа принимает данные по MQTT API, интерфейс описан в AsyncAPI спецификации.
Задача роутера проверить сообщение на корректность схемы и перекодировать его в Avro-формат для загрузки в Kafka.
Kafka кластер выполняет потоковую обработку данных пришедших с датчиков, вычисляет в реальном времени аггрегатные пользовательские и системные функции с помощью Kafka Streams или KSQL. Набор пользовательские функций может изменяться в зависимости от настроек аггрегации данных в пользовательском интерфейсе каждого пользователя. При этом важно чтобы пользователь в целях безопасности не мог получить прямого доступа к кластеру и даны разных пользователей проходили по разным очередям. Далее аггрегированные и "сырые" данные складываются в хранилище на базе Apache Cassandra.
Важно изначально настроить Stream Aggregation Engine так чтобы ограничивалось максимальная производительность клиентов пишущих на топики данные, чтобы предотвратить возможность DOS-атаки данного сервиса.
В данном проекте мы планируем применять Cassandra как основное хранилище всех данных. Такой подход позволит сосредоточиться на поддержке меньшего технологий. Для доступа к данным внутри Cassandra есть как официальный набор драйверов official list of client drivers, так и сторонние решения, например для Go есть развитие GoCQL от ScyllaDB: GoCQLx.
При проектирование схемы данных надо исходить от клиентских запросов и не бояться денормализации данных, а также важно правильно выбирать compaction стратегии и их настройки в зависимости от типа данных и кейса их использования.
В данном проекте Apache Cassandra кластер применяется также как долговременное хранилище аггрегированных и сырых данных. Важно верно выбрать кластерные ключи и распределение по таблицам чтобы избежать проблем с "супер таблицами" в будущем, а также верно использовать стратегии уплотнения данных. Так на текущий момент наиболее подходящей под time series данные считается стратегия TimeWindowCompactionStrategy.
Высокопроизводительный сервис служащий в качестве persistence адаптера для Stream Aggregation Engine. Основная задача сохранение аггрегированных и сырых данных в Timeseries storage, а также обратная их загрузка для целей расчета аггрегатных функций по историческим данным (необходимо исследовать возможность использования готового решения от компании Confluence).
Состоит из набора микросервисов. Сервисы общаются между собой через топики Kafka, что позволяет используя правильные шаблоны проектирования для сервисов с потоковой обработкой данных легко масштабировать систему.
Состоит из следующего набора сервисов:
Предоставляет API для Frontend приложения. А также производит вариацию данных принятых со стороны пользователя. В качестве основы планируется взять rest based framework из списка go-web-framework-stars.
Собирает статистику потребленных пользователем ресурсов и выставляет счета.
Производит аутентификацию и авторизацию пользователей. Возможна как использование внутренней базы пользователей так и внешних OAuth сервисов.
Хранит профили пользователей.
Выполняет запуск абстрактных плановых заданий.
Хранит настройки отчетов созданных пользователем. Формирование отчетов запускает либо сервис Portal API, либо, как в случае отчетов по плану, Schedule Service.
Отвечает за отправку Push нотификаций, SMS и Email рассылок.
Набор агрегатных функций на KSQL в потоковом режиме обрабатывающих данные на Kafka кластере.
Основной сервис для пользовательского WebUI и внутренней панели администрирования. Сервис предоставляющий Dashboard панели для мониторинга и аналитики по различным частям системы, а также отдельные графики для интегрирования в пользовательский WebUI. Графики и панели могут быть переконфигурированны пользователем, пользователь не имеет непосредственного доступа в данный сервис. Все команды по реконфигурации он получает на специальной очереди в Kafka, публикует туда их Portal API Service.
Графики панелей предоставляет Grafana. Сервис потребляет данные из Cassandra. В Cassandra они попадают из счетчиков приложений и логов предварительно распаршеных и аггрегированных в Kafka Stream Aggregation Engine (необходимо исследовать возможность применения Grafana для построения панелей графиков). Для коннекта Cassandra как source в Grafana планируется написать backend плагин, либо воспользоваться проектом grafana-cassandra-source.
Fluentbit сервис парсинга и пересылки логов, основная задача это переслать логи системных сервисов на специальные Kafka топики. Далее с помощью Kafka Stream Aggregation Engine они будут обработаны в необходимые нам метрики и сохранены в Timeseries storage на базе Cassandra.
Сервисы обязаны разрабатываться с возможностью активирования выборочной трассировки используя штатные возможности Fluentbit.
Основной задачей приложения является предоставление клиенту удобного интерфейса доступа к аналитике по его данным. Приложение должно иметь унифицированные вид, но с оптимизацией под параметры устройства.
Web App - приложение исполняемое в браузере с использованием React Framework. Список поддерживаемых браузеров MS Edge, Google Chrome, Mozilla FireFox, Apple Safari.
Mobile App - приложение для мобильных платформ на базе Kotlin\Kotlin Native. Поддерживаемые ОС Android 4.x\iOS 10 и выше.
-
Strix Sensor
- Arch: Firmware for MCU STM32L151 + LORA modules (RU868) ex.: on modem Semtech SX1272/SX1257.
- Backend: C++/ASM.
-
Strix Gateway
- Arch: Docker based image.
- Platform: ARMv8 (ex.: RPi).
- Backend: Go.
-
Strix WebApp
- Front: React.
-
Strix Cloud
- Arch: Docker based microservices.
- Orchestration: K8S, Ansible.
- Backend: Go.
- API: Swagger.
- Timeseries DB: Cassandra.
- Msg Broker: Kafka.
- Aggregation engine: Kafka stream.
Также множество Go технологий можно найти в списке awesome-go