-
주최 및 주관: 통계청
-
텍스트 데이터를 바탕으로 산업의 대분류(21), 중분류(77), 소분류(232)를 예측하는 문제입니다.
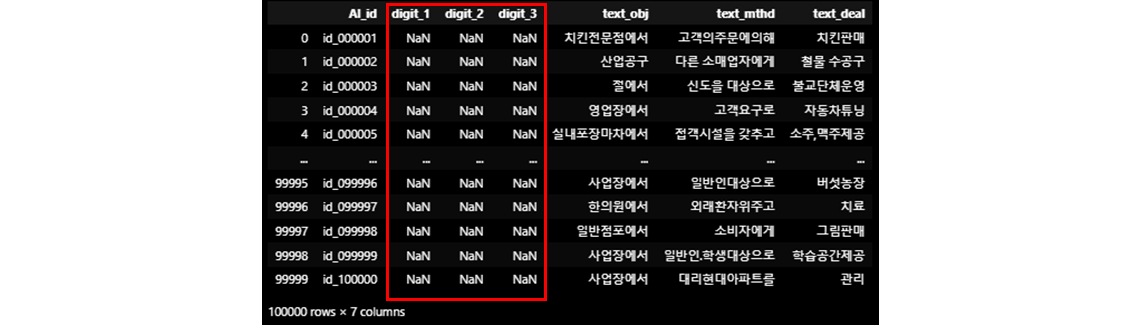
- -> 'text_obj', 'text_deal', 'text_mthd'를 통해 대분류, 중분류, 소분류(digit_1, digit_2, digit_3)를 예측하는 task (ex. 숙박 및 음식점업, 음식점 및 주점업, 기타 간이 음식점업)
-
1. Text에 대해 [^가-힣 0-9 a-z A-Z]+$ -> '' 로 전처리 및 좌우 공백 전처리 2. 데이터가 존재하지 않는 산업분류코드에 대해서는 직접 수기로 데이터를 입력 3. Raw data의 NaN값에 대해서 '한국표준산업분류(10차)_국문.xlsx' 파일의 분류별 '항목명' 데이터로 대체시킴 ex) 분류코드(C, 12, 120)의 값이 NaN인 경우 -> '담배 제조업'으로 대체 4. ['을', '를', '이', '가', '은', '는', '고', '그', '의', '및','등', '외', '와','한다','하','에', '않', '안', '된'] 등의 불용어 제거 5. Raw data에 존재하는 분류코드에 대해 대분류, 중분류, 소분류 각각 '한국표준산업분류(10차)_국문.xlsx' 파일을 통해 Data Augmentation 진행 6. Mecab을 통한 형태소 분석 후 생성된 형태소를 합쳐 token list 생성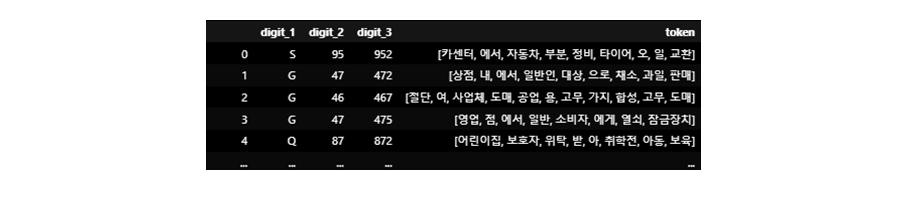
7. 사전학습된 한국어 Word2vec vocab에 생성된 token을 추가한 후 word2vec 재학습(Contextual word Embedding 아님 -> Static word Embedding 수행) - Pre-trained word vector of Korean은 다음의 github에서 다운 받을 수 있음(https://github.com/Kyubyong/wordvectors) - 아래 이미지는 pretrained word2vec의 재학습을 통해 주어진 token과 높은 유사도를 가지는 token을 높은순으로 나열
8. 모델 학습 시 vocab의 embedding도 같이 학습 시키기 위해 '<pad>', '<unk>' 토큰 추가 후 array화
- Token을 추가하여 재학습된 word2vec vocab의 t-SNE 시각화(Cluster간의 distance 고려 X)

-
-
대분류, 중분류, 소분류 예측을 하기위해 3head LSTM-Encoder를 사용
- MLP-Mixer, PLM 등 타 모델 보다 나은 성능을 보임
-
대분류 -> 중분류 -> 소분류 순으로 계층(Hierarchy)이 존재하기 때문에 예측 시 해당 분류에 속하는 하위 분류 이외에는 큰 loss 값을 갖도록 학습
- 낮은 성능과 긴 런타임(사용 X)
-
torch.nn.Embedding을 추가하여 token embedding vector 학습시킴
- Word2vec의 token embedding을 layer에 추가하여, trainable vector로써 학습시킴(학습 시 성능 향상)
-
Model techniques
- StratifiedKFold를 사용하여 cross validation을 진행함
- scheduler: CosineAnnealingLR
- Loss : SmoothCrossEntropyLoss 사용(Focal_loss 및 FocalLoss_With_Smoothing 사용 시 validation 낮은 성능)
- optimizer : AdamW 사용(SAM optimizer 사용 시 상대적 낮은 성능)
- EarlyStopping 사용
- automatic mixed precision 사용
-
-
- 사용한 Docker image는 Docker Hub에 첨부하며 cuda10.2, cudnn7, ubuntu18.04 환경을 제공합니다.
-
- python==3.9.7
- pandas==1.3.4
- numpy==1.20.3
- tqdm==4.62.3
- sklearn==0.24.2
- torch==1.10.2+cu102
- re==2.2.1
- konlpy==0.6.0
- gensim==3.8.3
-

-
- 사후 분석 및 후처리를 진행하지 않았기 때문에 후처리 분석을 수행
- 다양한 모델과의 Ensemble 시도
- Clustering 시 UMAP 고려