房價預測 目標:透過機器學習來預測房價 資料來源 上課老師提供並參與kaggle競賽(當時沒作資料分析)
以下為模型架構圖
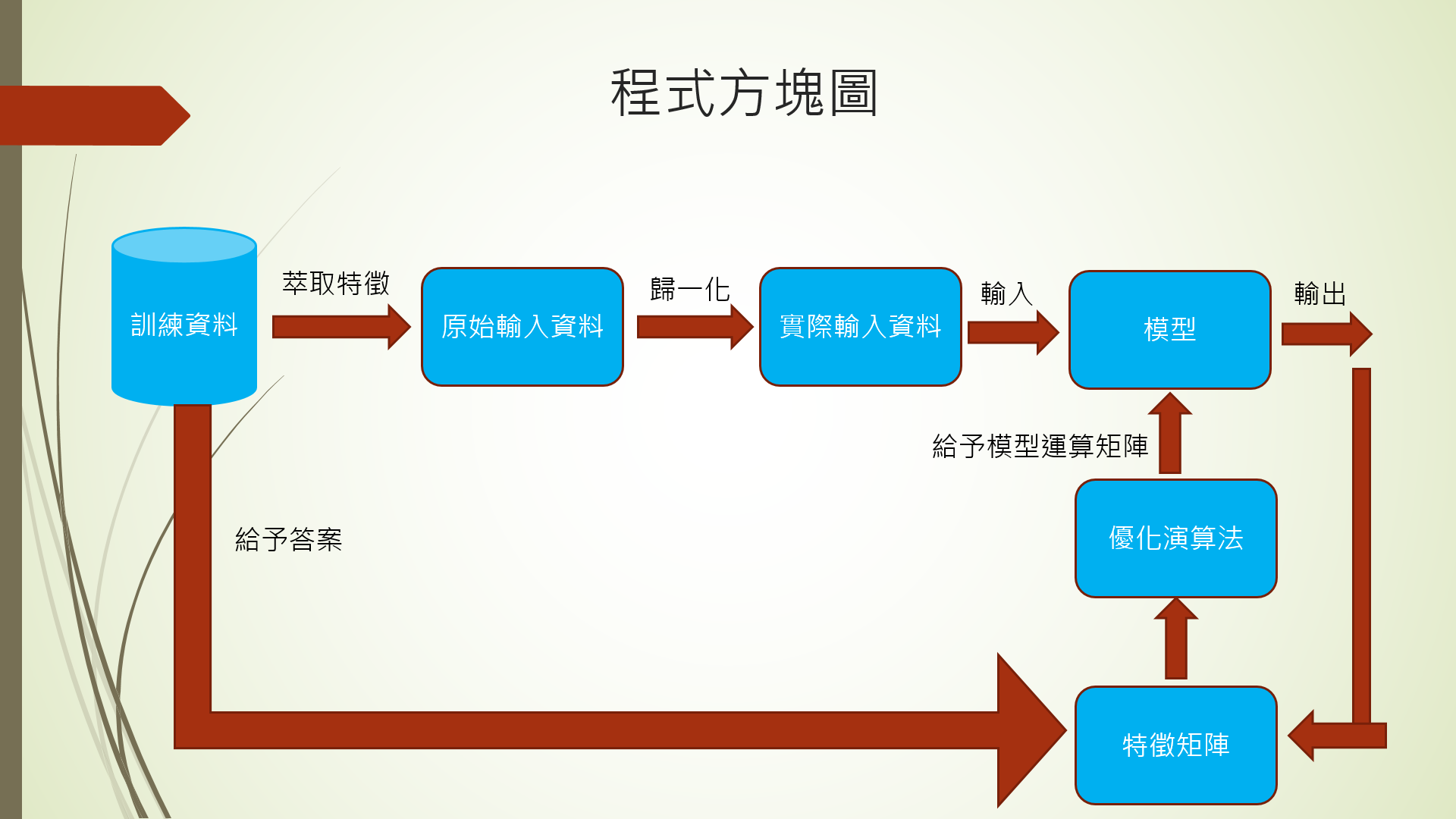
首先考慮輸入的問題各項數據間的差距可能很大因此去做標準化的動作 (現在可能可以不用 只要在模型中加入BatchNormalization 優點有以下:可以不用使用dropout 避免動盪過大 避免輸出飽和) (參考於論文 Batch Normalization: Accelerating Deep Network Training by Reducing Internal Covariate Shift)

最後是模型 及訓練結果(loss 最後在76881) 可以看出當時沒有使用dropout 這樣導致容易過擬合
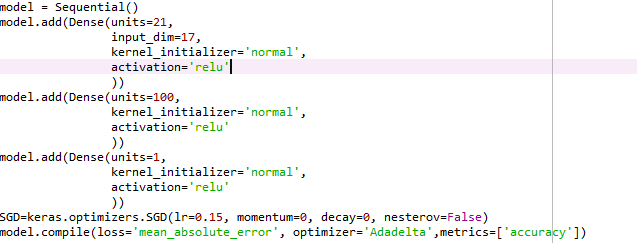


以結果來看不算好 當時不懂得調整跟挑選參數 導致認為只要多訓練幾次就好 但這樣容易過擬合 在訓練集以外的地方可能就不適用
讀入資料後 可以知道資料有23個參數其中id 出售月跟日 zipcode 等 明顯是跟價格無關因此不去理會
直覺上來說我們都會認為房子越大越值錢 我們在此做個分析
取前100筆資料 可以看出基本上就是房子越大越值錢

取前500及前2000及全部 可以看出最大及最小值都在隨著大小不斷上升 但可以注意到每一個大小還是有區間(代表有其他因素影響)

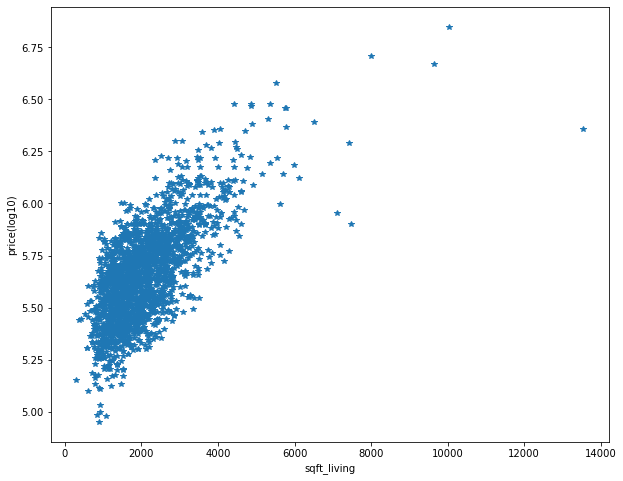
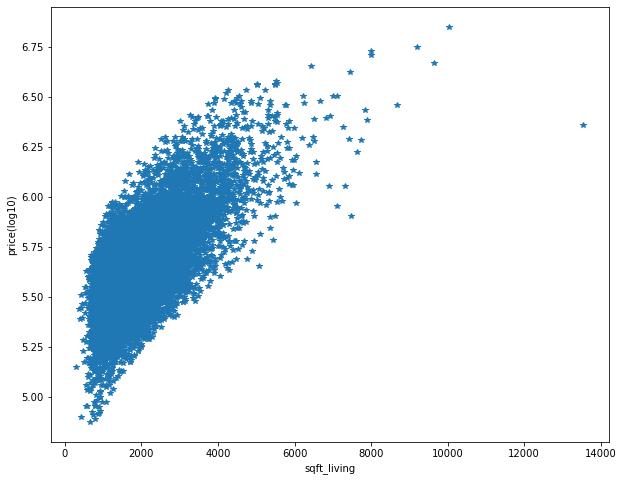
在大小超過6000之後 數據就變得很少 可以考慮在房屋大小超過6000時使用KNN而不使用原本的線性回歸
有區間的存在代表還有額外的參數會影響房價 除了大小 第二個可能會參考的就是屋齡因此我們取前2000筆資料做分析

整體
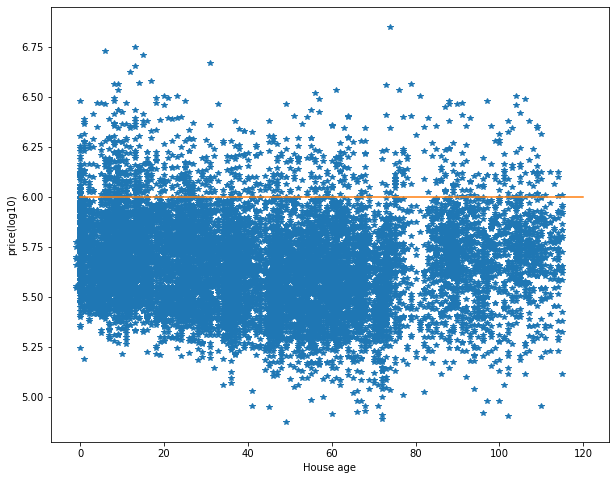
看起來趨勢是差不多的 但我們可以看出一個有趣的現象在屋齡0到80年間是隨著屋齡 價格下降 但屋齡過了(中間有一段很少資料)80年 則是價格約跟快40年的屋齡差不多 且不太有根據屋齡更大價格改變
最後分析幾個較為緊密且數據上比較完整的值(如waterfront 及 view大部分都是零所以不採用 後面的座標也幾乎不影響 而bathroom個數較為奇特有小數點 不知道是輸入錯誤還是如何)

可以看出 bathroom 跟 grade 有很明顯的趨勢 是一個很適合使用的特徵 floor 的部分由於X軸值很少 只有1-3 而且2和3在不同個體上的影響可能不大或許可以考慮拿掉 condition則是可以簡化特徵成0(1-2) 1(2-5)
#結論: 適合使用的特徵為房屋大小(6000內) 屋齡(可以考慮使用分區 因為在屋齡較高的分區有不同趨勢) bathroom 個數 grade 等級 可以直接使用 floor 可以不考慮 condidtion 則可以簡化