Automated demo video generator for web applications.
Write a JSON scenario describing browser actions and narration text. NeuraScreen drives a real browser, captures the screen, generates voiceover with TTS and produces a ready-to-publish video automatically.
JSON scenario --> Playwright browser --> Screen capture --> TTS narration --> MP4 video
Creating product demo videos is slow, repetitive and hard to maintain.
- Recording a 5-minute walkthrough takes an hour of preparation, retakes and editing
- Every UI change means re-recording the entire video
- SaaS teams need dozens of demo videos across features, languages and versions
- Keeping tutorials in sync with the actual product is a constant effort
NeuraScreen solves this. Describe your demo as a JSON scenario. The tool records the real browser, narrates with AI voice, and outputs a ready-to-publish MP4. When the UI changes, update the scenario and regenerate.
- Product demo videos for marketing pages and sales decks
- SaaS onboarding tutorials for new users
- Documentation walkthroughs with step-by-step narration
- Release videos showcasing new features
- Internal training for product and support teams
- Automated tutorial generation at scale using AI-written scenarios
Watch NeuraScreen generate a full demo video from a JSON scenario — preview, TTS narration, browser automation, screen capture and final MP4:
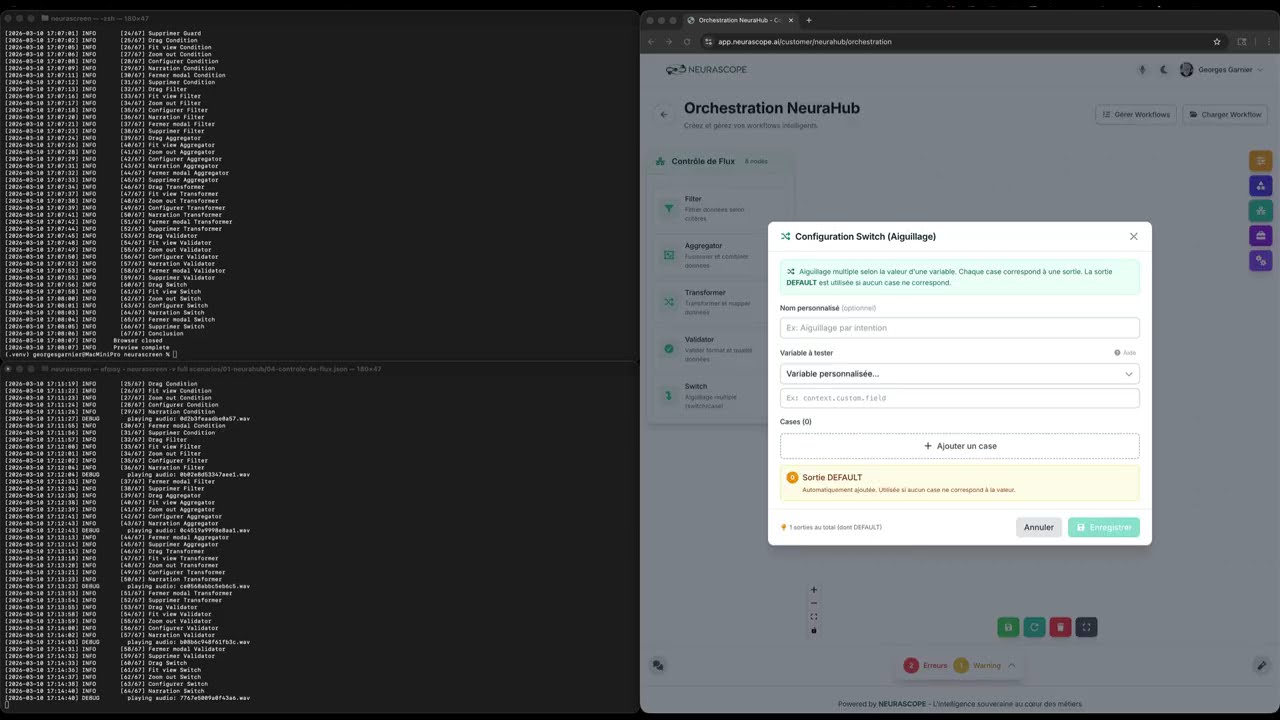
9m29 video · 67 automated steps · 12 narrated segments · 8 drag & drop interactions · 0 manual editing
NeuraScreen includes an optional desktop application (PySide6) for editing scenarios, previewing TTS audio and managing configuration visually.
| Welcome | Editor | Configuration |
|---|---|---|
 |
 |
 |
| Output Browser | Macro Recorder | JSON + Split View |
|---|---|---|
 |
 |
 |
Install with GUI support: pip install neurascreen[gui] then launch with neurascreen gui.
Via pip (recommended):
pip install neurascreen
playwright install chromiumWith optional extras:
pip install neurascreen[gradium] # For Gradium TTS
pip install neurascreen[gui] # For desktop GUI (PySide6)
pip install neurascreen[all] # EverythingFrom source:
git clone https://github.com/NEURASCOPE/neurascreen.git
cd neurascreen
pip install -e ".[dev]"
playwright install chromiumcp .env.example .envEdit .env:
APP_URL=http://localhost:3000
TTS_PROVIDER=openai
TTS_API_KEY=sk-...
TTS_VOICE_ID=alloy# Validate the scenario
neurascreen validate examples/01-simple-navigation.json
# Preview in browser (no recording)
neurascreen preview examples/01-simple-navigation.json
# Generate video with narration
neurascreen full examples/01-simple-navigation.jsonOutput: output/01-simple-navigation.mp4
{
"title": "Dashboard Overview",
"description": "Quick tour of the main dashboard",
"resolution": { "width": 1920, "height": 1080 },
"steps": [
{ "action": "navigate", "url": "/dashboard", "wait": 2000 },
{ "action": "wait", "duration": 1000,
"narration": "This is the main dashboard. It shows all active projects and recent activity." },
{ "action": "click_text", "text": "Analytics", "wait": 1500 },
{ "action": "wait", "duration": 1000,
"narration": "The analytics tab provides real-time metrics and usage trends." },
{ "action": "scroll", "selector": "main", "direction": "down", "amount": 400, "wait": 1000 },
{ "action": "wait", "duration": 1000,
"narration": "Detailed reports are available at the bottom of the page." }
]
}neurascreen validate my-scenario.jsonneurascreen full my-scenario.jsonThe output MP4 is in output/.
- You write a JSON scenario with browser actions and narration text
- The TTS engine pre-generates audio for each narration step
- Playwright drives a real Chromium browser through the steps
- ffmpeg captures the screen natively in high quality (5K on Retina displays)
- Each narration audio is played in real-time during capture for perfect synchronization
- The assembler crops/scales to 1920x1080 and merges the audio track
The JSON format is designed to be easily generated by large language models. You describe what you want, the LLM writes the scenario, NeuraScreen produces the video.
| Model | Best for |
|---|---|
| Claude Code | Browse your app live, inspect elements, write the scenario |
| ChatGPT (GPT-4o) | Write scenarios from descriptions or screenshots |
| Mistral | Good for multilingual narration text |
| Gemini | Multimodal: generate scenarios from screenshots |
| Ollama (local) | Privacy-sensitive projects, offline usage |
| OpenRouter | Access multiple models via one API |
I need a demo video scenario for my web application.
The app is a project management tool at http://localhost:3000.
The user logs in, sees a dashboard with projects, clicks on a project,
and sees the task list.
Generate a JSON scenario for NeuraScreen using this format:
- "navigate" to open pages
- "click_text" to click buttons by their visible text
- "click" with CSS selectors for icon buttons
- "wait" with "narration" to describe what's visible on screen
- "scroll" to scroll down
The narration should be professional, concise, and in English.
Start with an intro and end with a conclusion.
The LLM produces the JSON. You validate and run it:
neurascreen validate scenario.json
neurascreen full scenario.jsonNeuraScreen supports 5 TTS providers. Configure in .env.
High quality, multilingual, fast, simple API.
TTS_PROVIDER=openai
TTS_API_KEY=sk-...
TTS_VOICE_ID=alloy
TTS_MODEL=tts-1-hdVoices: alloy echo fable onyx nova shimmer
Models: tts-1 (fast) or tts-1-hd (high quality)
Best voice quality, voice cloning, many voices.
TTS_PROVIDER=elevenlabs
TTS_API_KEY=sk_...
TTS_VOICE_ID=21m00Tcm4TlvDq8ikWAM
TTS_MODEL=eleven_multilingual_v2French-focused TTS with natural voices.
TTS_PROVIDER=gradium
TTS_API_KEY=gsk_...
TTS_VOICE_ID=b35yykvVppLXyw_l
TTS_MODEL=defaultEnterprise-grade, many languages, Neural2 voices.
TTS_PROVIDER=google
TTS_API_KEY=your-api-key
TTS_VOICE_ID=fr-FR-Neural2-AFree, open source, runs locally. No API key needed.
TTS_PROVIDER=coqui
TTS_API_KEY=http://localhost:5002
TTS_VOICE_ID=default| Action | Description | Required fields |
|---|---|---|
navigate |
Open a URL | url |
click |
Click by CSS selector | selector |
click_text |
Click by visible text | text |
type |
Type into a field | selector, text |
scroll |
Scroll an element | selector, direction, amount |
hover |
Hover an element | selector |
key |
Press a keyboard key | text |
wait |
Pause with narration | duration |
drag |
Drag item to canvas | text |
delete_node |
Delete last canvas node | -- |
close_modal |
Close current modal | -- |
zoom_out |
Zoom out N times | amount |
fit_view |
Fit view to content | -- |
| Field | Type | Default | Description |
|---|---|---|---|
title |
string | "" |
Step name for logging |
action |
string | -- | Action to perform (required) |
url |
string | -- | URL (relative or absolute) |
selector |
string | -- | CSS selector |
text |
string | -- | Text content |
wait |
int | 1000 |
Pause after action (ms) |
duration |
int | 1000 |
Wait duration (ms) |
narration |
string | "" |
TTS narration text |
direction |
string | -- | "up" or "down" |
amount |
int | 300 |
Scroll pixels or zoom count |
Perform actions silently, then narrate what is visible:
{ "action": "navigate", "url": "/settings", "wait": 2000 },
{ "action": "wait", "duration": 1000, "narration": "The settings page." }All settings are in .env. See .env.example for the full documented reference.
| Variable | Description |
|---|---|
APP_URL |
Base URL of your web app |
| Variable | Description |
|---|---|
APP_EMAIL |
Login email (empty = skip login) |
APP_PASSWORD |
Login password |
LOGIN_URL |
Login path (default: /login) |
| Variable | Default | Description |
|---|---|---|
VIDEO_WIDTH |
1920 |
Output width |
VIDEO_HEIGHT |
1080 |
Output height |
VIDEO_FPS |
30 |
Frames per second |
BROWSER_HEADLESS |
false |
Headless mode |
| Variable | Default | Description |
|---|---|---|
CAPTURE_SCREEN |
0 |
ffmpeg screen index (macOS avfoundation) |
CAPTURE_DISPLAY |
"" |
Display identifier — Linux: X11 display (e.g. :0.0), Windows: desktop or title=Window Name |
BROWSER_SCREEN_OFFSET |
0 |
Browser X pixel offset |
| Command | Description |
|---|---|
neurascreen validate <file> |
Validate scenario JSON |
neurascreen preview <file> |
Run in browser without recording |
neurascreen run <file> |
Record video without narration |
neurascreen full <file> |
Record with TTS narration |
neurascreen batch <folder> |
Generate videos from all scenarios in a folder |
neurascreen record <url> |
Record browser interactions → JSON scenario |
neurascreen list |
List available scenarios |
neurascreen voices list |
List configured TTS voices per provider |
neurascreen voices add <provider> <id> <name> |
Add a voice to a provider |
neurascreen voices remove <provider> <id> |
Remove a voice |
neurascreen voices set-default <provider> <id> |
Set default voice for a provider |
neurascreen --version |
Show version |
neurascreen gui |
Launch desktop GUI (requires [gui] extra) |
Options: --verbose / -v for debug output, --headless for headless mode, --srt for subtitle generation, --chapters for YouTube chapter markers.
Voices are stored per provider in ~/.neurascreen/voices.json (shared with the GUI). If TTS_VOICE_ID or TTS_MODEL are not set in .env, the CLI uses defaults from voices.json.
neurascreen voices list # List all voices
neurascreen voices list -p openai # Filter by provider
neurascreen voices add gradium abc123 "My voice" # Add a voice
neurascreen voices set-default openai nova # Set default
neurascreen voices remove gradium abc123 # RemoveYou can also use python -m neurascreen instead of neurascreen.
NeuraScreen includes an optional desktop interface built with PySide6.
pip install neurascreen[gui]neurascreen gui- Scenario editor — visual step list with drag-reorder, adaptive detail panel for all 14 action types, JSON source view with syntax highlighting, split view
- File browser — sidebar tree view of your scenario folders, double-click to open
- Execution panel — run validate/preview/run/full from the GUI with real-time colored console output
- Configuration manager — visual .env editor with 7 tabs (Application, Browser, Screen Capture, TTS, Selectors, Directories), validation, import/export
- TTS & audio preview — per-provider voice config (
~/.neurascreen/voices.json), per-step audio preview, pronunciation helper, narration statistics - Output browser — browse generated videos with integrated video player (QMediaPlayer), SRT subtitles viewer, YouTube chapters viewer
- Macro recorder — record browser interactions from the GUI with live event feed, cleanup options, and direct import into the editor (Ctrl+R)
- Selector validator — verify scenario selectors against the real DOM using Playwright headless, with found/not found/multiple status and suggestions (Ctrl+Shift+V)
- Scenario statistics — steps count, actions breakdown, narration metrics, estimated duration, unique URLs and selectors
- Scenario diff — compare two scenario files side by side with added/removed/modified/unchanged status
- Autosave & recovery — periodic autosave every 60s, recovery prompt on startup
- Theme engine — dark teal (default) and light themes with full Fusion style support, switchable via Ctrl+T. Create custom themes as JSON files in
~/.neurascreen/themes/ - Step templates — insert common patterns (navigation, drag & configure, form fill) from the context menu
- Undo/redo — full undo history for all editing operations
- Keyboard shortcuts — 20+ shortcuts including Ctrl+N/O/S, F5-F8, Ctrl+R (record), Ctrl+Shift+V (validate selectors)
The GUI is optional — the CLI remains the primary interface and works without PySide6.
Download from python.org or use your package manager.
| OS | Command |
|---|---|
| macOS | brew install ffmpeg |
| Ubuntu/Debian | sudo apt install ffmpeg |
| Windows | choco install ffmpeg |
Installed automatically via playwright install chromium after pip install.
neurascreen/
├── .env.example # Configuration template
├── pyproject.toml # Package metadata & dependencies
├── LICENSE # MIT
├── README.md
├── neurascreen/ # Python package
│ ├── cli.py # CLI commands (entry point)
│ ├── config.py # Configuration loader
│ ├── scenario.py # JSON parser & validator
│ ├── browser.py # Playwright browser engine
│ ├── platform.py # OS detection & platform-specific commands
│ ├── recorder.py # Screen capture (ffmpeg)
│ ├── subtitles.py # SRT subtitles & YouTube chapters
│ ├── macro.py # Macro recorder (browser → JSON)
│ ├── narrator.py # TTS & timing sync
│ ├── tts.py # TTS abstraction (5 providers)
│ ├── assembler.py # Video assembly
│ ├── utils.py # Helpers
│ └── gui/ # Optional desktop GUI (PySide6)
│ ├── app.py # QApplication entry point
│ ├── main_window.py # Main window
│ ├── theme.py # Theme engine (JSON → QSS)
│ ├── themes/ # Theme palettes (dark-teal, light)
│ ├── resources/ # App icons, SVG arrows
│ ├── editor/ # Scenario editor widgets
│ ├── execution/ # Command execution panel
│ ├── config/ # Configuration manager (.env editor)
│ ├── tts/ # TTS panel, audio preview, voices, pronunciation
│ ├── output/ # Output browser, video player, SRT/chapters viewers
│ ├── macro/ # Macro recorder dialog, event feed, cleanup
│ └── advanced/ # Selector validator, statistics, diff, autosave
├── tests/ # Unit tests (pytest)
├── examples/ # Example scenarios
├── docs/ # Documentation
├── output/ # Generated videos
├── temp/ # Intermediate files
└── logs/ # Execution logs
| Feature | macOS | Linux | Windows |
|---|---|---|---|
| Browser automation | Yes | Yes | Yes |
| Screen capture | Yes (avfoundation) | Yes (x11grab) | Yes (gdigrab) |
| Audio playback | Yes (afplay) | Yes (paplay/aplay) | Yes (PowerShell) |
| TTS | Yes | Yes | Yes |
| Video assembly | Yes | Yes | Yes |
Generate scenarios by recording your browser interactions instead of writing JSON by hand:
neurascreen record http://localhost:3000 -t "My demo"A browser opens. Click around normally. Close it when done. The tool outputs a valid JSON scenario.
# Review and edit the generated scenario
neurascreen validate output/my_demo.json
neurascreen preview output/my_demo.json
# Add narration to wait steps, then generate the video
neurascreen full output/my_demo.jsonSee docs/macro-recorder.md for the full guide.
Generate SRT subtitles and YouTube chapter markers alongside your videos:
# Video + subtitles + chapters
neurascreen full --srt --chapters scenario.jsonOutput:
output/scenario.mp4— the videooutput/scenario.srt— subtitles (upload to YouTube Studio or use with VLC)output/scenario.chapters.txt— chapter markers (paste into YouTube description)
See docs/subtitles-chapters.md for details.
Process all scenarios in a folder in one command:
# With narration
neurascreen batch scenarios/ --srt --chapters
# Without narration (faster)
neurascreen batch scenarios/ --no-narrationValidates all scenarios upfront, processes them sequentially, and prints a summary report.
Run NeuraScreen in a container for headless video generation (no display required):
# Build
docker build -t neurascreen .
# Generate a video
docker run --rm \
-v ./scenarios:/app/examples \
-v ./output:/app/output \
-e APP_URL=http://host.docker.internal:3000 \
-e TTS_PROVIDER=openai -e TTS_API_KEY=sk-... -e TTS_VOICE_ID=alloy \
neurascreen full examples/demo.json --srt --chaptersThe container includes Xvfb (virtual display) and PulseAudio (audio playback). See docs/docker.md for CI/CD integration, networking and troubleshooting.
See CONTRIBUTING.md for how to report bugs, suggest features, add TTS providers or submit pull requests.
| Guide | Description |
|---|---|
| Scenario Writing Guide | How to write effective demo scenarios |
| Cross-Platform Setup | macOS, Linux and Windows configuration |
| Macro Recorder | Record browser interactions → JSON |
| Subtitles & Chapters | SRT subtitles and YouTube chapters |
| Desktop GUI | Visual scenario editor and execution |
| Docker | Headless generation in containers |
| Contributing | Add TTS providers, actions, or submit PRs |
See ROADMAP.md for planned features.
MIT