Di era digital saat ini, platform streaming film seperti Netflix, Hulu, dan Amazon Prime memiliki koleksi film yang sangat besar. Pengguna sering kali kesulitan menemukan film yang sesuai dengan preferensi mereka karena banyaknya pilihan yang tersedia. Oleh karena itu, sistem rekomendasi menjadi penting untuk membantu pengguna menemukan film yang mereka sukai.
Proyek ini bertujuan untuk membangun sistem rekomendasi film menggunakan dataset MovieLens. Dengan sistem ini, diharapkan pengguna dapat menerima rekomendasi film yang sesuai dengan preferensi mereka, meningkatkan kepuasan pengguna, dan meningkatkan engagement pada platform.
Rubrik/Kriteria Tambahan (Opsional):
- Menyelesaikan proyek ini penting karena sistem rekomendasi dapat meningkatkan pengalaman pengguna dan loyalitas terhadap platform. Menurut Ricci et al. (2011), sistem rekomendasi membantu mengurangi information overload dan meningkatkan kepuasan pengguna.
- Bagaimana membangun sistem rekomendasi yang dapat memberikan saran film yang dipersonalisasi kepada pengguna?
- Algoritma apa yang paling efektif untuk digunakan dalam sistem rekomendasi film pada dataset MovieLens?
- Bagaimana cara mengevaluasi kinerja sistem rekomendasi yang dibangun?
- Mengembangkan sistem rekomendasi yang dapat memberikan saran film berdasarkan preferensi pengguna.
- Membandingkan beberapa algoritma rekomendasi untuk menentukan pendekatan terbaik.
- Mengevaluasi kinerja sistem rekomendasi menggunakan metrik evaluasi yang sesuai.
- Mengimplementasikan algoritma Collaborative Filtering (User-Based dan Item-Based).
- Mengimplementasikan teknik Matrix Factorization menggunakan Singular Value Decomposition (SVD).
- Mengevaluasi model menggunakan metrik Root Mean Square Error (RMSE) dan Precision@K.
Dataset yang digunakan adalah MovieLens 100K Dataset, yang berisi 100.000 rating dari 943 pengguna terhadap 1.682 film. Dataset ini dapat diunduh di MovieLens Dataset.
Variabel-variabel pada dataset MovieLens adalah sebagai berikut:
- user_id : ID unik untuk setiap pengguna.
- item_id : ID unik untuk setiap film.
- rating : Rating yang diberikan pengguna (skala 1-5).
- timestamp : Waktu saat rating diberikan.
Exploratory Data Analysis (EDA):
-
Distribusi Rating:
# Visualisasi distribusi rating plt.figure(figsize=(8,6)) sns.countplot(x='rating', data=ratings, palette='viridis') plt.title('Distribusi Rating') plt.xlabel('Rating') plt.ylabel('Frekuensi') plt.show()
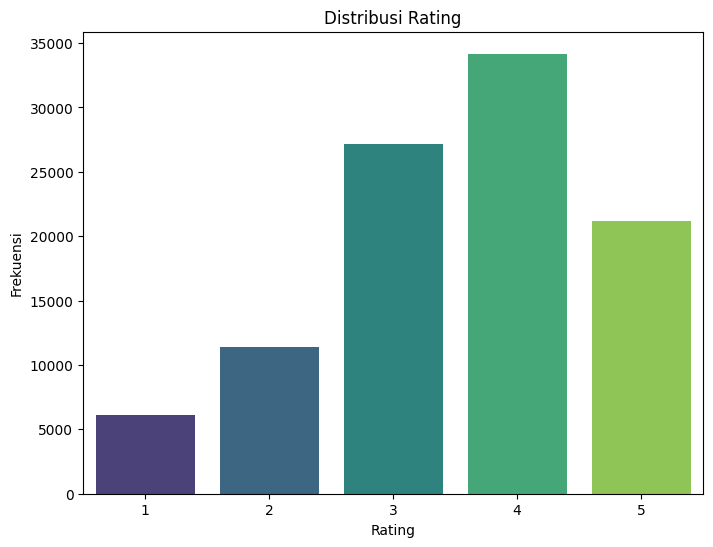
Insight: Mayoritas pengguna memberikan rating tertinggi pada angka 4 dan 3, menunjukkan bahwa penilaian film cenderung berada di tengah hingga positif. Hal ini mungkin mencerminkan preferensi pengguna yang lebih bijaksana atau adanya variasi dalam kualitas film yang ditonton.
-
Film Terpopuler:
# Menghitung jumlah rating per film movie_counts = ratings.groupby('item_id').size().sort_values(ascending=False) # Menggabungkan dengan judul film movie_counts = movie_counts.reset_index() movie_counts.columns = ['item_id', 'rating_count'] movie_counts = pd.merge(movie_counts, movies, on='item_id') # Menampilkan 10 film teratas print("10 Film Terpopuler:") movie_counts.head(10)
# Visualisasi 10 film terpopuler plt.figure(figsize=(12,8)) sns.barplot(x='rating_count', y='title', data=movie_counts.head(10), palette='magma') plt.title('10 Film Terpopuler') plt.xlabel('Jumlah Rating') plt.ylabel('Judul Film') plt.show()
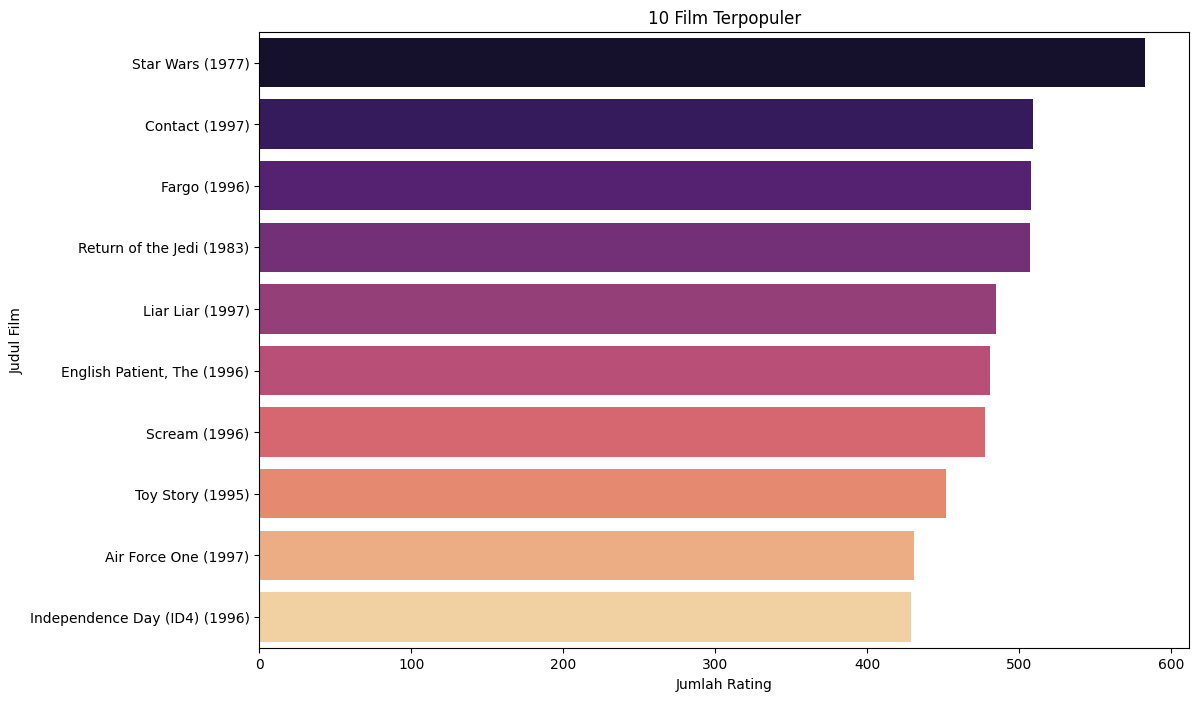
Insight: Beberapa film menerima lebih banyak perhatian, yang bisa mempengaruhi model rekomendasi. Film dengan jumlah rating tinggi mungkin lebih dikenal dan diminati oleh pengguna.
Langkah-langkah data preparation yang dilakukan:
-
Merging Data: Menggabungkan data rating dengan data film untuk mendapatkan informasi lengkap.
# Menggabungkan data ratings dengan judul film ratings = pd.merge(ratings, movies, on='item_id') # Menampilkan data setelah penggabungan ratings.head()
Penjelasan:
- Fungsi
pd.merge()digunakan untuk menggabungkan dua DataFrame (ratingsdanmovies) berdasarkan kolomitem_id. - Setelah penggabungan, setiap entri rating akan memiliki informasi tambahan mengenai judul film, yang memudahkan interpretasi hasil rekomendasi.
- Fungsi
-
Data Splitting:
# Fungsi untuk membagi data per pengguna def train_test_split_per_user(ratings, test_size=0.2, min_ratings=5, random_state=42): train_list = [] test_list = [] for user, group in ratings.groupby('user_id'): if len(group) >= min_ratings: train_grp, test_grp = train_test_split( group, test_size=test_size, random_state=random_state ) train_list.append(train_grp) test_list.append(test_grp) else: # Menugaskan semua rating ke training jika jumlah rating kurang dari min_ratings train_list.append(group) train_data = pd.concat(train_list).reset_index(drop=True) test_data = pd.concat(test_list).reset_index(drop=True) return train_data, test_data train_data, test_data = train_test_split_per_user(ratings, test_size=0.2, min_ratings=5, random_state=42)
Penjelasan:
- Fungsi
train_test_split_per_usermembagi data per pengguna. Jika seorang pengguna memiliki jumlah rating lebih dari atau sama denganmin_ratings, maka 20% rating akan dipisahkan ke set testing. - Jika jumlah rating seorang pengguna kurang dari
min_ratings, semua rating tersebut akan dimasukkan ke set training untuk memastikan set testing memiliki data yang representatif. - Pembagian data ini membantu dalam mencegah masalah cold-start pada set testing.
- Fungsi
-
Membuat User-Item Matrix:
# Membuat Matriks User-Item untuk Training dan Testing train_matrix = train_data.pivot_table(index='user_id', columns='title', values='rating').fillna(0) test_matrix = test_data.pivot_table(index='user_id', columns='title', values='rating').fillna(0)
Penjelasan:
pivot_tabledigunakan untuk membentuk matriks denganuser_idsebagai indeks dantitlesebagai kolom, mengisi nilai denganrating.- Nilai
NaNdiisi dengan0menggunakanfillna(0)untuk menandakan bahwa pengguna belum memberikan rating pada film tersebut.
-
Normalisasi Data:
# Melakukan Normalisasi pada Matriks Training scaler = StandardScaler() train_matrix_scaled = scaler.fit_transform(train_matrix) # Mengubah kembali matriks yang sudah diskalakan menjadi DataFrame train_matrix_scaled = pd.DataFrame(train_matrix_scaled, index=train_matrix.index, columns=train_matrix.columns) # Menjamin bahwa matriks testing memiliki kolom yang sama dengan matriks training test_matrix = test_matrix.reindex(columns=train_matrix.columns, fill_value=0)
Penjelasan:
StandardScalerdari scikit-learn digunakan untuk menstandarisasi fitur dengan menghapus mean dan menskalakan ke varians unit.- Setelah normalisasi, matriks training diubah kembali menjadi DataFrame dengan indeks dan kolom yang sama untuk memudahkan manipulasi selanjutnya.
- Matriks testing disesuaikan untuk memiliki kolom yang sama dengan matriks training menggunakan
reindex, mengisi kolom yang tidak ada dengan0.
- Merging Data: Diperlukan untuk mendapatkan informasi judul film yang akan memudahkan interpretasi hasil rekomendasi dan analisis lebih lanjut.
- Data Splitting: Membagi data menjadi set training dan testing per pengguna memastikan bahwa model dapat dievaluasi secara adil dan mengurangi risiko overfitting.
- User-Item Matrix: Matriks ini merupakan representasi fundamental yang dibutuhkan sebagai input untuk algoritma Collaborative Filtering dan Matrix Factorization.
- Normalisasi Data: Penting untuk menghilangkan bias rating antar pengguna, sehingga model tidak terpengaruh oleh perbedaan skala rating yang diberikan oleh pengguna yang berbeda.
Dengan melalui tahapan data preparation ini, data siap digunakan untuk membangun dan melatih model rekomendasi yang efektif dan akurat.
Menggunakan cosine similarity untuk menghitung kesamaan antar pengguna dan memberikan rekomendasi berdasarkan pengguna yang serupa.
user_similarity = cosine_similarity(train_matrix_scaled)
user_similarity_df = pd.DataFrame(user_similarity, index=train_matrix_scaled.index, columns=train_matrix_scaled.index)
def user_based_recommendations(user_id, num_recommendations=5):
if user_id not in user_similarity_df.index:
print(f"User ID {user_id} not found in similarity matrix.")
return []
# Mendapatkan skor kesamaan untuk pengguna
similar_users = user_similarity_df.loc[user_id].sort_values(ascending=False)
# Menghapus pengguna itu sendiri dari daftar pengguna serupa
similar_users = similar_users.drop(user_id, errors='ignore')
# Mendapatkan rating pengguna serupa
similar_users_ratings = train_matrix.loc[similar_users.index]
# Menghitung jumlah bobot dari kesamaan
sum_of_weights = similar_users.sum()
if sum_of_weights == 0:
return []
# Memperkirakan rating
pred_ratings = similar_users_ratings.T.dot(similar_users) / sum_of_weights
# Mengambil film yang belum diberi rating oleh pengguna
user_rated = train_matrix.loc[user_id]
recommendations = pred_ratings[user_rated == 0].sort_values(ascending=False).head(num_recommendations)
return recommendations.index.tolist()Menggunakan Singular Value Decomposition untuk mengurangi dimensi dan menangkap hubungan laten antar pengguna dan item.
# Perform SVD
k = 50
train_matrix_scaled_np = train_matrix_scaled.to_numpy()
U, sigma, Vt = svds(train_matrix_scaled_np, k=k)
sigma = np.diag(sigma)
all_user_predicted_ratings = np.dot(np.dot(U, sigma), Vt)
preds_df = pd.DataFrame(all_user_predicted_ratings, columns=train_matrix.columns, index=train_matrix.index)
def svd_recommendations(user_id, num_recommendations=5):
if user_id not in preds_df.index:
print(f"User ID {user_id} not found in SVD predictions.")
return []
# Mendapatkan dan mengurutkan rating prediksi pengguna
user_predictions = preds_df.loc[user_id].sort_values(ascending=False)
# Mendapatkan rating aktual pengguna
user_actual = train_matrix.loc[user_id]
# Merekomendasikan film yang belum diberi rating
recommendations = user_predictions[user_actual == 0].head(num_recommendations)
return recommendations.index.tolist()Kelebihan dan Kekurangan:
-
Collaborative Filtering:
- Kelebihan: Mudah diimplementasikan, tidak memerlukan data fitur item.
- Kekurangan: Masalah data sparsity dan cold-start problem.
-
Matrix Factorization (SVD):
- Kelebihan: Mengatasi sparsity, menangkap hubungan laten.
- Kekurangan: Lebih kompleks dan membutuhkan sumber daya komputasi lebih besar.
- Root Mean Square Error (RMSE): Mengukur perbedaan antara nilai yang diprediksi dan aktual.
- Precision@K: Proporsi item yang relevan dalam top-K rekomendasi.
- Recall@K: Proporsi item relevan yang berhasil direkomendasikan dalam top-K.
def calculate_rmse(actual, predicted):
return np.sqrt(mean_squared_error(actual, predicted))# Fungsi untuk menghitung Precision@K
def precision_at_k(actual, predicted, k=5):
actual_set = set(actual)
predicted_set = set(predicted[:k])
return len(actual_set & predicted_set) / kdef recall_at_k(actual, predicted, k=5):
actual_set = set(actual)
predicted_set = set(predicted[:k])
return len(actual_set & predicted_set) / len(actual_set) if len(actual_set) > 0 else 0# Prediksi Rating Berdasarkan User-Based Collaborative Filtering
def user_based_predict_rating(user_id, movie_title):
if user_id not in user_similarity_df.index:
print(f"User ID {user_id} tidak ditemukan di matriks kesamaan.")
return 0 # Atau nilai default lainnya
if movie_title not in train_matrix.columns:
print(f"Judul film '{movie_title}' tidak ditemukan di matriks training.")
return 0 # Atau nilai default lainnya
# Mendapatkan skor kesamaan untuk pengguna
similar_users = user_similarity_df.loc[user_id].sort_values(ascending=False)
# Menghapus pengguna itu sendiri
similar_users = similar_users.drop(user_id, errors='ignore')
# Mendapatkan rating untuk film target dari pengguna serupa
similar_users_ratings = train_matrix.loc[similar_users.index, movie_title]
# Mendapatkan skor kesamaan pengguna serupa
similarity_scores = similar_users
# Menghitung rata-rata tertimbang
if similarity_scores.sum() == 0:
return 0 # Menghindari pembagian dengan nol
predicted_rating = np.dot(similarity_scores, similar_users_ratings) / similarity_scores.sum()
return predicted_ratingMelakukan evaluasi terhadap kedua model (Collaborative Filtering dan SVD) menggunakan testing set.
# Inisialisasi daftar untuk menyimpan metrik evaluasi
rmse_svd = []
precision_svd = []
recall_svd = []
rmse_cf = []
precision_cf = []
recall_cf = []
# Iterasi melalui setiap pengguna di matriks testing
for user in test_matrix.index:
try:
# Mendapatkan rating aktual untuk pengguna di testing set
actual_ratings = test_matrix.loc[user]
actual_movies = actual_ratings[actual_ratings > 0].index.tolist()
if not actual_movies:
continue # Melewati pengguna tanpa rating di testing set
# Mendapatkan rekomendasi dari SVD
svd_recommended = svd_recommendations(user, num_recommendations=5)
# Mendapatkan rekomendasi dari User-Based Collaborative Filtering
cf_recommended = user_based_recommendations(user, num_recommendations=5)
# Menghitung RMSE untuk SVD
svd_predicted = preds_df.loc[user, actual_movies]
svd_actual = test_matrix.loc[user, actual_movies]
rmse_svd.append(calculate_rmse(svd_actual, svd_predicted))
# Menghitung RMSE untuk User-Based Collaborative Filtering
cf_predicted_ratings = [user_based_predict_rating(user, movie) for movie in actual_movies]
cf_actual_ratings = test_matrix.loc[user, actual_movies].values
rmse_cf.append(calculate_rmse(cf_actual_ratings, cf_predicted_ratings))
# Menghitung Precision@5 dan Recall@5 untuk SVD
precision_svd.append(precision_at_k(actual_movies, svd_recommended, k=5))
recall_svd.append(recall_at_k(actual_movies, svd_recommended, k=5))
# Menghitung Precision@5 dan Recall@5 untuk User-Based Collaborative Filtering
precision_cf.append(precision_at_k(actual_movies, cf_recommended, k=5))
recall_cf.append(recall_at_k(actual_movies, cf_recommended, k=5))
except KeyError as e:
print(f"KeyError untuk user_id {user}: {e}")
continue
except Exception as e:
print(f"Unexpected error untuk user_id {user}: {e}")
continue# Menghitung rata-rata metrik evaluasi untuk SVD
avg_rmse_svd = np.mean(rmse_svd) if rmse_svd else float('nan')
avg_precision_svd = np.mean(precision_svd) if precision_svd else float('nan')
avg_recall_svd = np.mean(recall_svd) if recall_svd else float('nan')
# Menghitung rata-rata metrik evaluasi untuk User-Based Collaborative Filtering
avg_rmse_cf = np.mean(rmse_cf) if rmse_cf else float('nan')
avg_precision_cf = np.mean(precision_cf) if precision_cf else float('nan')
avg_recall_cf = np.mean(recall_cf) if recall_cf else float('nan')
# Menampilkan hasil evaluasi
print("\nHasil Evaluasi\n")
print("- Collaborative Filtering (User-Based):")
print(f" - RMSE: {avg_rmse_cf:.2f}")
print(f" - Precision@5: {avg_precision_cf:.2f}")
print(f" - Recall@5: {avg_recall_cf:.2f}\n")
print("- Matrix Factorization (SVD):")
print(f" - RMSE: {avg_rmse_svd:.2f}")
print(f" - Precision@5: {avg_precision_svd:.2f}")
print(f" - Recall@5: {avg_recall_svd:.2f}")Hasil evaluasi model rekomendasi yang dibangun menggunakan dataset MovieLens 100K menunjukkan perbandingan antara Collaborative Filtering (User-Based) dan Matrix Factorization (SVD) sebagai berikut:
Hasil Evaluasi
- Collaborative Filtering (User-Based):
- RMSE: 4.18
- Precision@5: 0.18
- Recall@5: 0.08
- Matrix Factorization (SVD):
- RMSE: 3.50
- Precision@5: 0.14
- Recall@5: 0.04
Interpretasi:
- Model SVD memiliki RMSE yang lebih rendah dibandingkan dengan Collaborative Filtering (User-Based), menunjukkan prediksi rating yang lebih akurat.
- Namun, Collaborative Filtering (User-Based) menunjukkan Precision@5 dan Recall@5 yang lebih tinggi, menunjukkan bahwa rekomendasi yang diberikan lebih relevan dan mencakup proporsi item relevan yang lebih besar.
Rubrik/Kriteria Tambahan (Opsional):
- RMSE penting untuk mengevaluasi seberapa baik model dalam memprediksi rating yang sebenarnya.
- Precision@K dan Recall@K penting untuk mengevaluasi kualitas rekomendasi yang diberikan kepada pengguna, memastikan bahwa rekomendasi yang disajikan relevan dan mencakup item-item yang benar-benar diminati pengguna.
Proyek ini berhasil membangun sistem rekomendasi film menggunakan dataset MovieLens 100K dengan dua pendekatan utama: Collaborative Filtering dan Matrix Factorization (SVD). Dari hasil evaluasi, model SVD menunjukkan kinerja yang lebih baik dalam hal akurasi prediksi rating dibandingkan dengan Collaborative Filtering. Namun, Collaborative Filtering unggul dalam hal relevansi rekomendasi yang diberikan kepada pengguna.
Rekomendasi untuk Pengembangan Selanjutnya:
- Hybrid Approach: Menggabungkan Collaborative Filtering dan Matrix Factorization untuk memanfaatkan kelebihan kedua metode.
- Optimasi Hyperparameter: Melakukan tuning hyperparameter lebih lanjut pada model SVD dan Collaborative Filtering untuk meningkatkan performa.
- Inkorporasi Fitur Eksternal: Menambahkan data fitur seperti genre, sutradara, atau aktor untuk meningkatkan kualitas rekomendasi.
- Penanganan Cold-Start: Mengembangkan strategi untuk menangani pengguna atau item baru yang belum memiliki data rating.
- Eksperimen dengan Algoritma Lain: Mencoba algoritma rekomendasi lain seperti Deep Learning atau metode berbasis content untuk perbandingan performa.
Dengan implementasi dan pengembangan lebih lanjut, sistem rekomendasi ini diharapkan dapat memberikan pengalaman pengguna yang lebih baik dan meningkatkan engagement pada platform streaming film.
Ricci, F., Rokach, L., & Shapira, B. (2011). Introduction to Recommender Systems Handbook. Springer.