Walmart Inc. est une multinationale de vente au détail qui comprend une chaîne d'hypermarchés, de grands magasins discount et d'épiceries aux États-Unis. La société a été fondée par Sam Walton en 1962.
Le service marketing de Walmart souhaite construire un modèle de machine learning capable d'estimer les ventes hebdomadaires dans leurs magasins, avec la meilleure précision possible sur les prédictions faites. Un tel modèle les aiderait à mieux comprendre comment les ventes sont influencées par les indicateurs économiques et pourrait être utilisé pour planifier de futures campagnes de marketing.
Les variables disponibles sont :
- L'identifiant du magasin
- La date
- Les ventes hebdomadaires réalisées
- Si la date est un jour férié ou non
- La température
- Le prix du carburant
- Le Consumer Price Index (CPI) qui est un indicateur qui mesure le changement de prix dans les biens et services essentiels tels que les loyers, la nourriture et l'energie.
- Le taux de chômage
Ce projet est découpé en 3 étapes :
- Partie 1 : Analyse Descriptive Exploratoire et pré-traitement des données
- Partie 2 : Construire un modèle de régression linéaire (baseline)
- Partie 3 : Optimisation du modèle à l'aide de techniques de régularisation (Lasso, Ridge et Elasticnet)
Les librairies suivantes sont nécessaires :
- General :
- warnings
- math
- pandas
- numpy
- scipy
- pickle
- bioinfokit
- Graphiques :
- matplotlib
- seaborn
- plotly
- Preprocessing
- missingno
- fancyimpute
- Sélection & évaluation des modèles
- mlxtend
- sklearn
- yellowbrick
Le notebook Part 1 - EDA and preprocessing.ipynb prend en input le fichier Walmart_Store_sales.csv et réalise l'overview préalable du jeu de données ainsi que les premiers traitements de données préalables à l'analyse. Il aboutit à la création du fichier preprocessed.csv qui contient les données pré-traitées et prêtes à l'analyse.
Le notebook Part 2 - Machine Learning.ipynb prend en input le fichier preprocessed.csv et réalise :
- Le pré-traitement lié à l'analyse (imputation des données manquantes, transformation des variables, découpage du dataset en deux sous-datasets pour l'entrainement du modèle puis pour son test)
- Le modèle de régression linéaire classique - Baseline
- Les modèles régularisés - Lasso, Ridge et Elasticnet
La première visualisation montre des données parcellaires (dates manquantes, volume de données inconsistant). C'est un aspect important à prendre en compte puisqu'il vient tempérer tous les résultats obtenus - Un "bon" modèle ne compensera jamais des données de "mauvaise" qualité1.

Le caractère incomplet des données des données est renforcé par cette seconde visualisation qui permet d'appréhender le volume de données par année et par magasin.
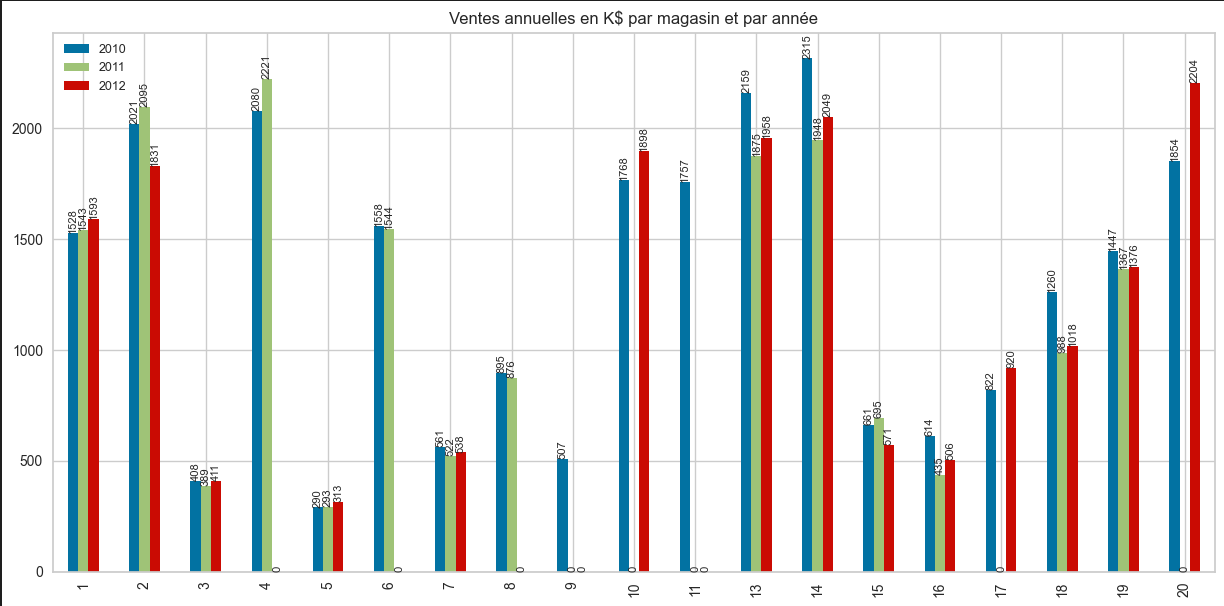
Ainsi, la base de données fournie permet un bon exercice car sa taille limitée en nombre d'observations oblige à se questionner sur les modèles générés mais aucune des conclusions tirées à partir d'un tel jeu de données ne peut être extrapolable.
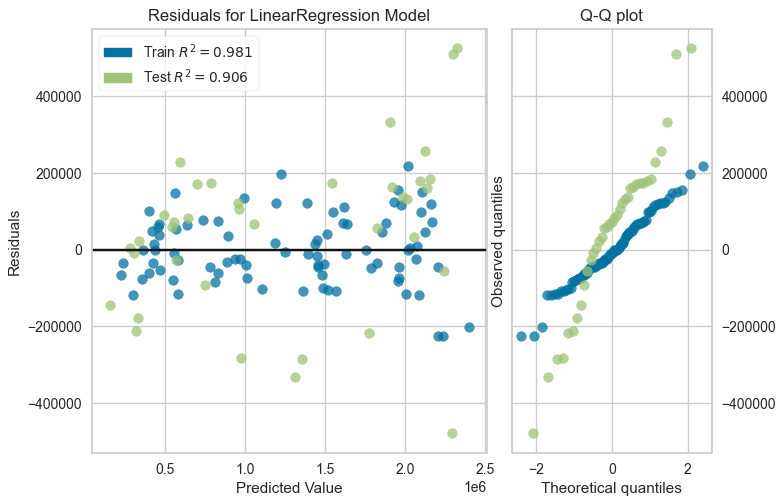
Le modèle de régression linéaire de base donne déjà satisfaction en termes de performances (R²). Néanmoins le grand nombre de paramètres estimés à l'aide d'un échantillon de taille limitée nécessite l'utilisation d'algorithmes plus complexes.
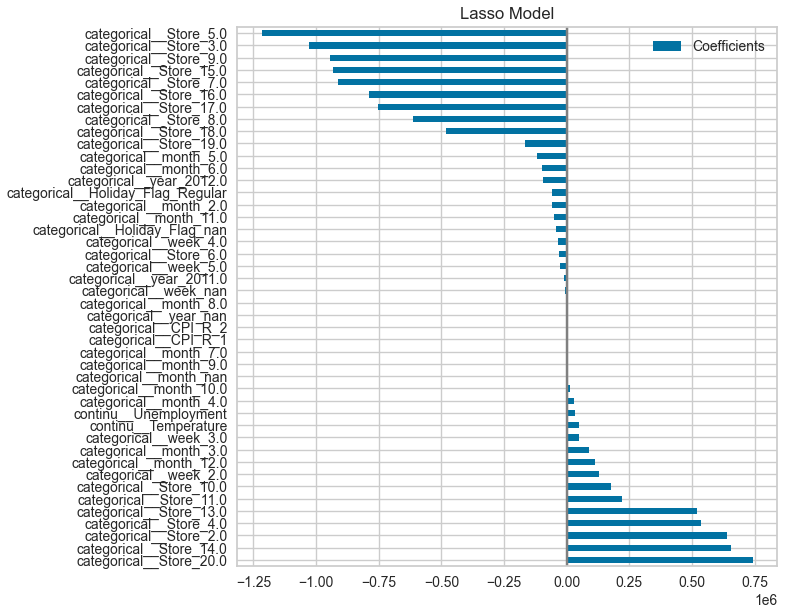
Le modèle Lasso a été préféré et il permet de simplifier le modèle en mettant les paramètres les moins explicatifs/prédictifs à 0.
Les notebooks ont été développés avec Visual Studio Code.
Auteur :
- Helene alias @Bebock
La dream team :
- Henri alias @HenriPuntous
- Jean alias @Chedeta
- Nicolas alias @NBridelance
Kaggle dataset : https://www.kaggle.com/datasets/yasserh/walmart-dataset
Footnotes
-
Cortes, Corinna & Jackel, Larry & Chiang, Wan-ping. (2000). Limits on Learning Machine Accuracy Imposed by Data Quality. ↩