{kind=link}
This project is one of the getting started challenges offered by Kaggle. As an instant way of communication, Twitter has become an important channel in times of emergency. It enables people to announce an emergency in real-time. Because of this immediacy, a growing numhber of agencies are interested in automatically monitoring Twitter.
The objective is to build a machine learning model that predicts which Tweets are about real disasters and which one’s aren’t.
The following librairies are required :
re
unidecode
spellchecker
contractions
string
math
pandas
numpy
plotly
matplotlib
seaborn
spacy
nltk
gensim
pyLDAvis
wordcloud
sklearn
xgboost
tensorflow
Kaggle provides a dataset of 10 000 tweets that were hand classified as disaster-related or not. In the train dataset, around 43% are disaster-related.
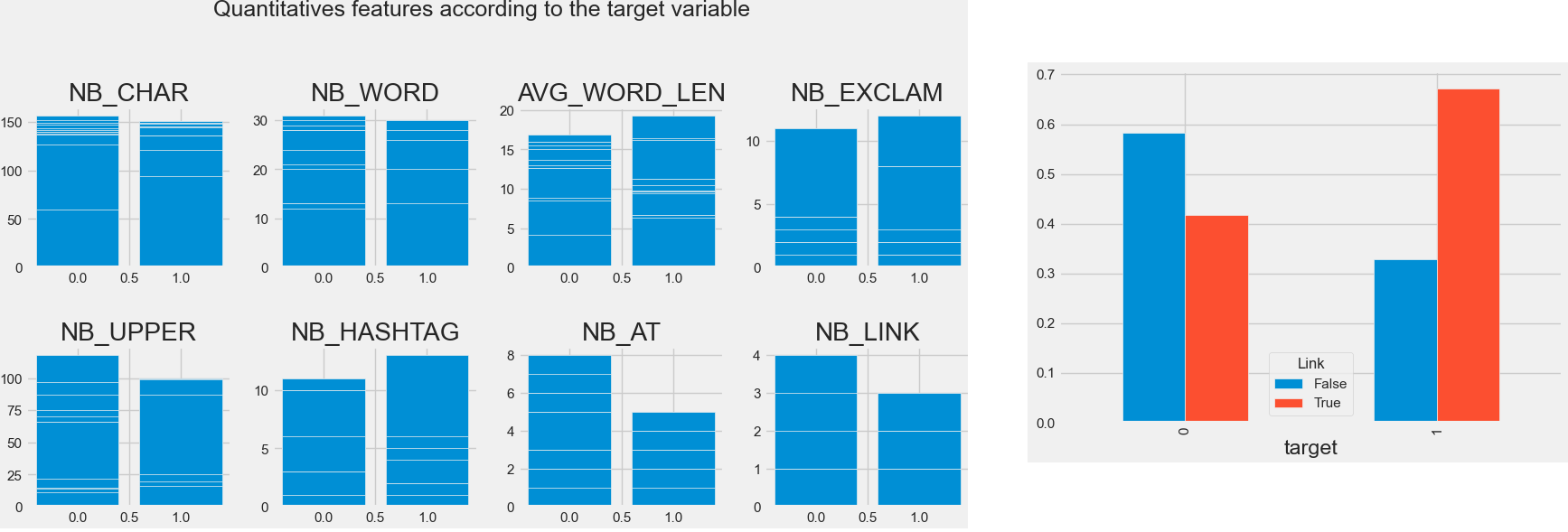
First of all, we extracted some quantitative features, not directly linked to the contents. Doing so, we tried to extract some additional information not available through text / content analysis.
- Lenght of the tweet measured by the number of characters and by the number of words
- Average lenght of words
- Number of exclamation marks
- Number of uppercase letters
- Number and presence of #
- Number and presence of @
- Number and presence of urls
Statistically speaking, all these characteristics were related to the target variable (disaster tweet or not). However, the sample size of the dataset provides too much statistical power so we focused on graphical explorations. It appeared that the disaster-related tweets contain longer words in average, less uppercases, more #, much less @, and less urls in mean but the disaster-related tweets are in proportion more prone to contain at least one url.
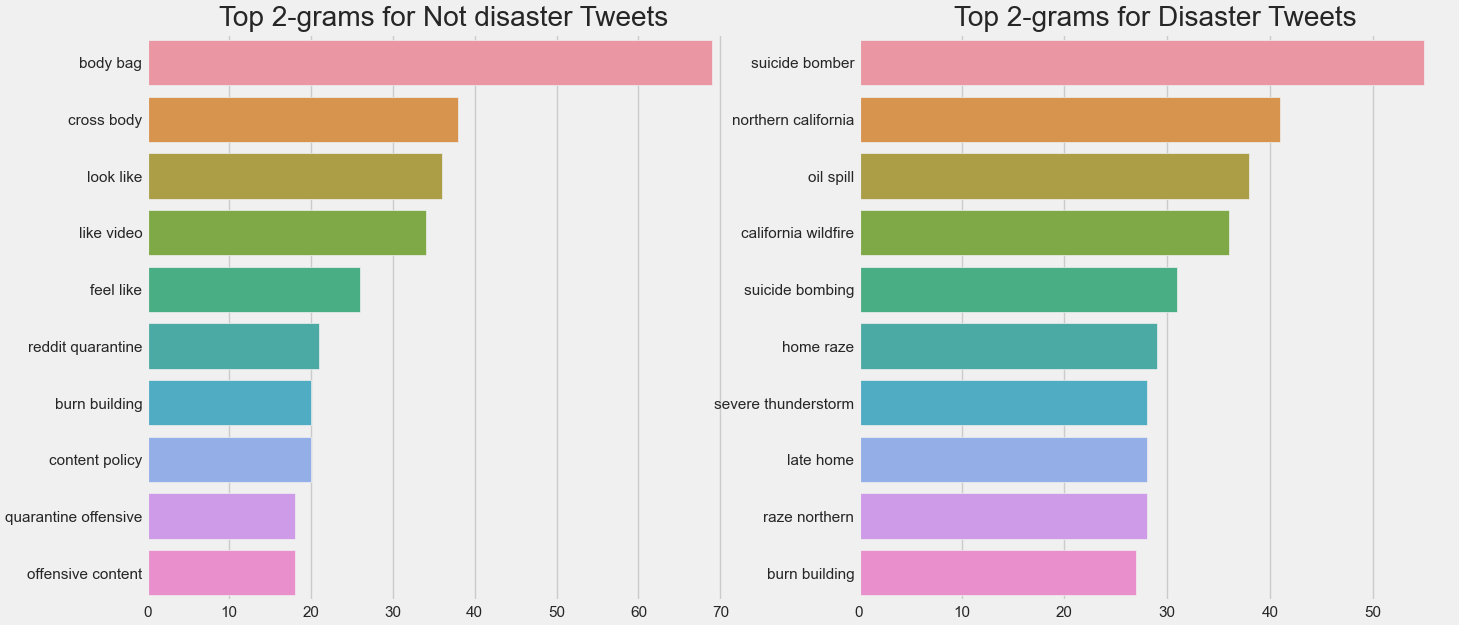
The tweets content has been described after pre-processing and lemmatization with :
- Top bigrams according to the target variable (disaster-related or not)
- Wordclouds according to the target variable (disaster-related or not)

Disaster tweets appeared less associated with neutral or positive sentiments.
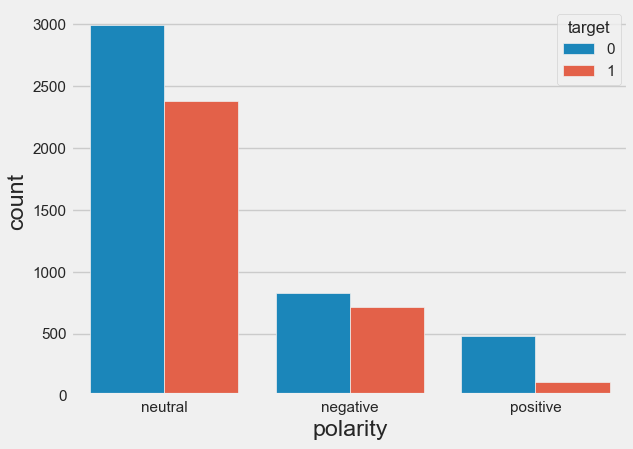
However, the sentiment analysis allowed us to detect some questionning coding in the dataset. Indeed, displaying the tweets coded as disaster-related and categorized as positive by the sentiment analysis, we can read for exemple the following tweets :
- "my favorite lady came to our volunteer meeting hopefully joining her youth collision and i am excite"
- "ok peace I hope I fall off a cliff along with my dignity"
- ":) well I think that sounds like a fine plan where little derailment is possible so I applaud you :)" ... and they do not refer to disasters. It might indicate some confusing labels in the training dataset.
We tried 3 main approaches :
- Using classical Machine learning models on the previously extracte features
- Using classical Machine learning models on recoded text through TF-IDF or BoW
- Using neural networks
The results were the following :
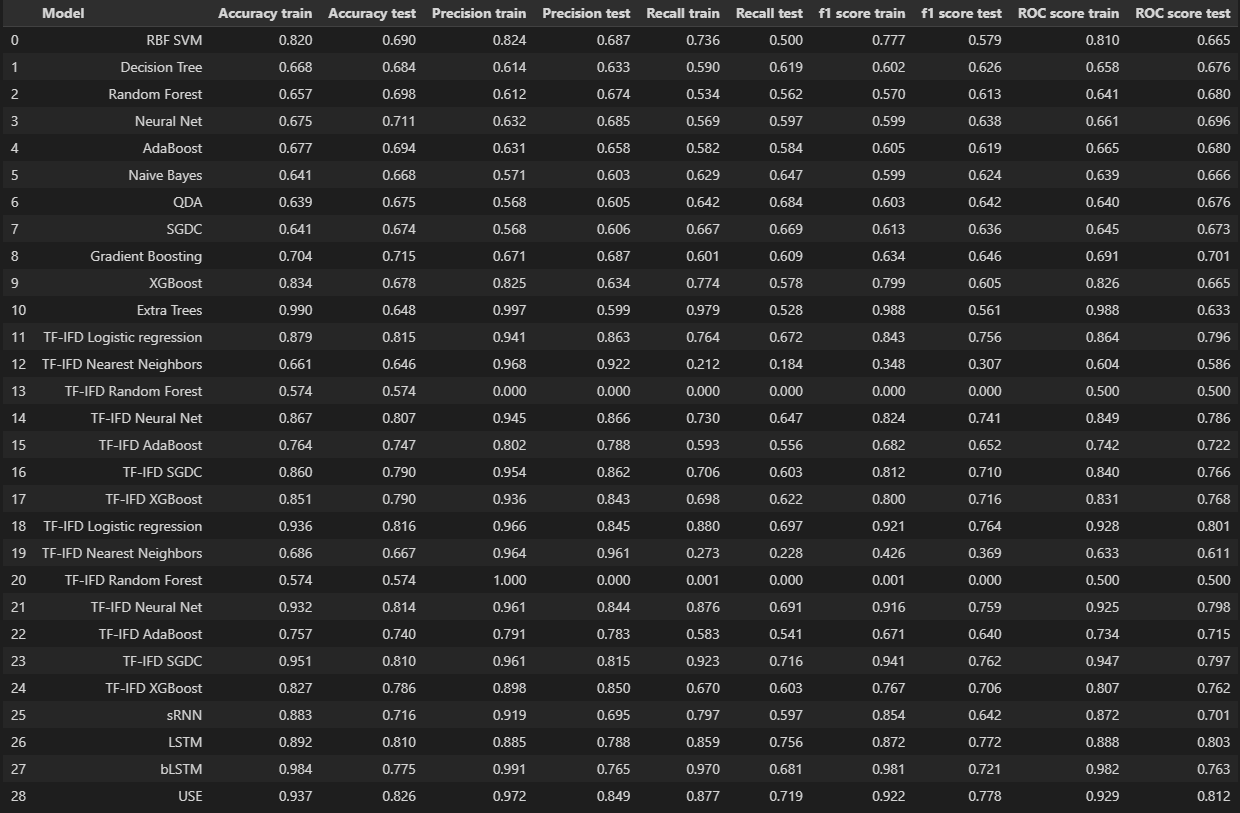
It appeared that a pre-trained embedding neural netword (Universal Sentence Encoder) had the best performances in terms of ROC score, f1 score and accuracy. However, classical Machine Leanrning models performed on Bag of Words (Neural Net and SGDC) performed at a similar level.
The best models may now be improved thanks to fine tuning of hyperparameters.
The notebook has been developed with Visual Studio Code.
The USE is available here
Author :
Helene alias @Bebock
The dream team :
Henri alias @HenriPuntous
Jean alias @Chedeta
Nicolas alias @NBridelance