2018 - Academic project at UC Berkeley, merging both the issues of Education and Artificial Intelligence.
This project was presented at the SIGKDD2019 at Anchorage during the Social Impact Workshop.
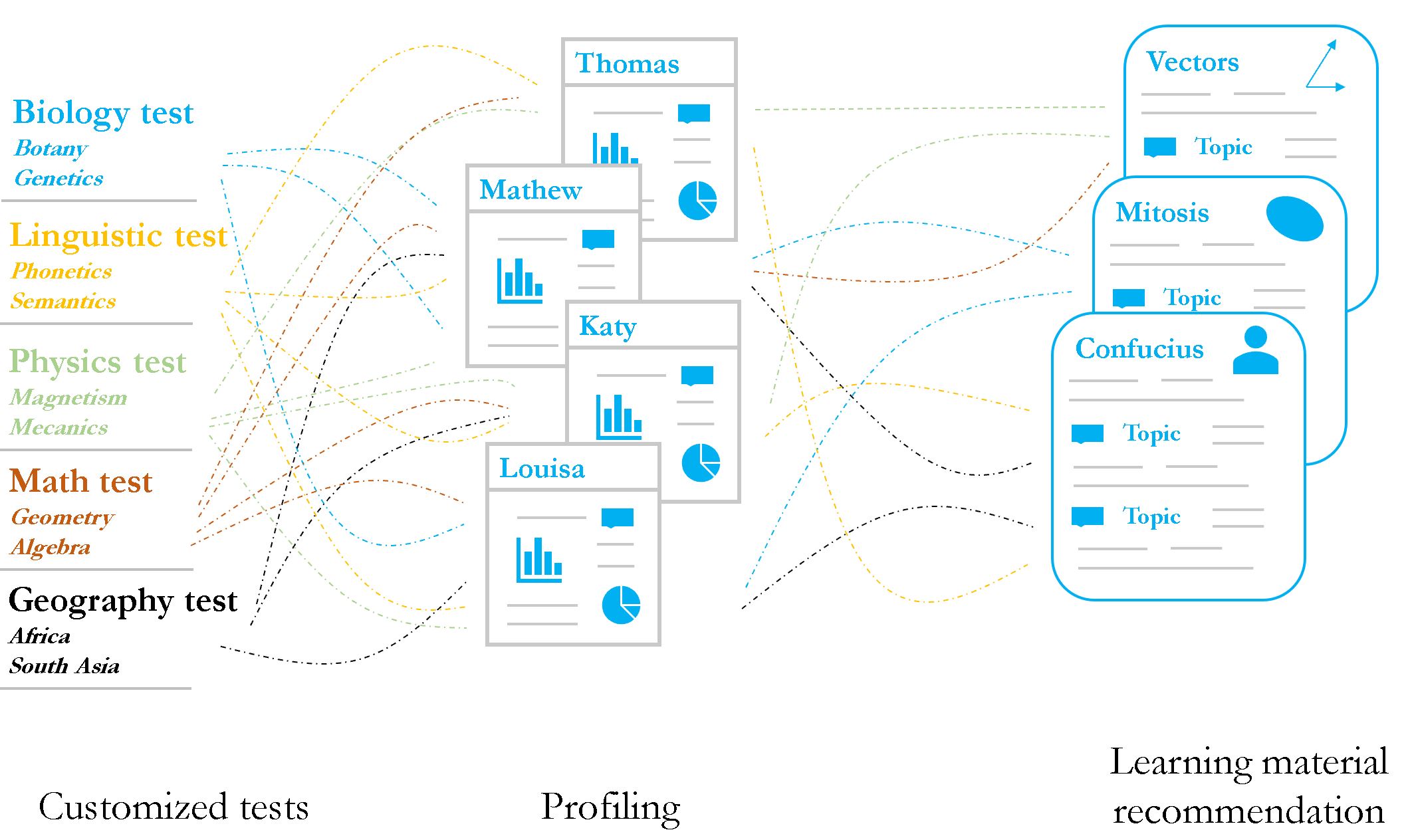
Improve the way students learn thanks to customized recommendation of learning contents based on their test results. Providing a personnalized education tools by adapting to each student learning style thanks to unsupervised clustering algorithms. Providing insights for students and teachers as well.
- October: Topic Understanding and Database Management
- November: Algorithms development and front end development
- December: Final product delivery
- El Bouri, Niema: niema_elbouri@berkeley.edu
- Lawrence, Mike: mikelawrence@berkeley.edu
- Shan, Shine: shine_shan@berkeley.edu
- Tanyindawn, Ada: adatanyindawn@berkeley.edu
- Spezzatti, Andy: andy_spezzatti@berkeley.edu
- Košmerlj, Aljaž: aljaz.kosmerlj@ijs.si
- Hodson, James: hodson@ai4good.org

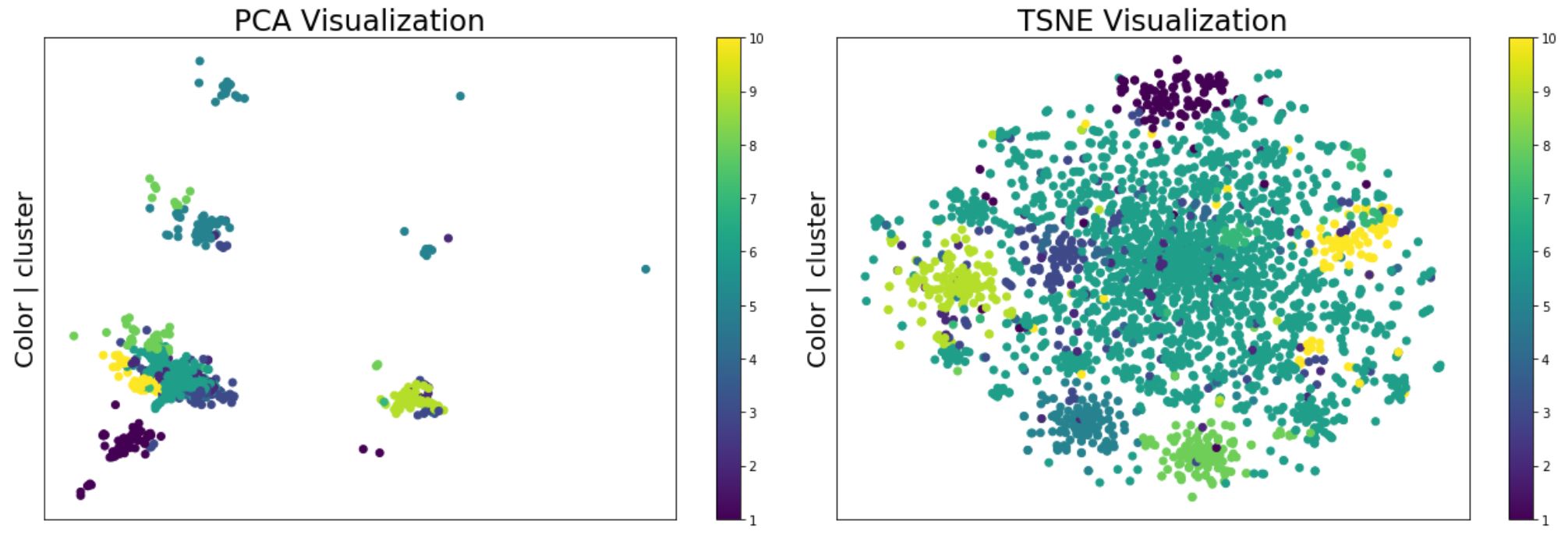
Leveraging dimensionality reduction technique, we can get some insights into the different hierarchies of subjects present in our database
With a bubble plot, we can then visualize which words are more important and reflect more accuratly one cluster. A similar analysis can be done for higher n-grams.

Using Spacy's ner model and fine tuned it using our own annotated examples, we created our own ner model. We first added a couple of classes, useful for our application (detecting academic subjects and cognitive skills):
PHY: physic
BIO: biology
VIZ: visualization
SHAPE: shape
CLIM: climatology
ANM: animals
GEO: geology
COMP: comparison
The training of the ner model can be done by using:
python ner_cust.py -m=en -o="path/to/output/directory" -n=100