The Generative and Programmable Response Framework (GPR-Framework) designed to solve the rigidity of traditional Affective Computing. It establishes a perpetually evolving framework for Natural Emotion Processing (NEP), enabling the understanding of the full spectrum of human emotions from basic states (e.g., anger, joy) to complex, abstract feelings (e.g., greed, grudge, sarcasm) directly from textual and audio input data.
At its core is the JAST Emotional AI Framework, which replaces static classification models with a Real-Time Continual Learning system built around a dynamic, universal Multidimensional Emotional Map (the JAST Vector Space). This map is generated by deep Self-Supervised Learning (SSL) Transformer embeddings, which are specifically mapped onto a continuous, four-dimensional bipolar affective space derived from Plutchik's psychoevolutionary theory of emotion. The system's output is an intermediate E-Token and a final, precise JAST-V Point (a 4D vector) representing the emotional state within the space.
The entire protocol operates under a Human-in-the-Loop (HITL) paradigm, acting as a machine learning system that learns like a child:
- Discovery: Novelty detection algorithms flag textual inputs that fall outside of known emotional clusters.
- Guidance: Human trainers provide real-time corrective feedback and assign new labels for complex or abstract emotional concepts.
- Adaptation: Continual Learning (CL) algorithms, such as Elastic Weight Consolidation (EWC), efficiently update the universal emotional map based on this feedback, dynamically creating new emotional regions and vectors without suffering from catastrophic forgetting.
The primary limitation of contemporary Affective Computing systems is their dependence on categorical emotion models and static training regimes, causing them to fail in representing the nuanced, mixed-affective states of human communication. Specifically, current models suffer from:
- Dimensional Inexpressivity, limiting emotional output to predefined labels instead of a continuous spectrum;
- Adaptation Rigidity, preventing real-time alignment with evolving linguistic and social contexts;
- Catastrophic Forgetting, where learning new emotional concepts overwrites proficiency in old ones, hindering stable Continual Learning.
The goal is to engineer the Generative & Programmable Response Framework (GPR-Framework), a Real-Time Continual Learning Emotional AI designed for high-fidelity Optimal Social Integration (OSI). Crucially, the GPR-Framework must serve as a Dual-Translation Emotive Operating System (DTE-OS) that bridges a user with a third-party AI API (e.g., Gemini, ChatGPT).
This OS-like function requires the system to:
-
Decompose User Input: Accurately map textual/audio input into two distinct signals: the Logical Query (
$\mathcal{S}'$ ) and a continuous JAST-V Emotional Vector ($\in [-100.00, +100.00]$ ). - Achieve Emotive Parity: Synthesize the raw, logical output from the AI API with an emotionally congruent response layer to ensure the user perceives a conversation with a human-like entity.
- Ensure Adaptability: Employ a Human-in-the-Loop (HITL) framework and Elastic Weight Consolidation (EWC) to enable indefinite, stable knowledge acquisition and real-time social alignment.
The Generative & Programmable Response Framework (GPR-Framework), built upon the JAST Emotional AI Framework, functions as an Emotional Operating System (OS) that controls the flow of communication between a human user and a commercial AI API. This OS role involves a Dual-Translation Emotive Bridge process:
-
Input Translation (User
$\rightarrow$ API): The GPR-Framework receives the user's input (text/audio), processes it, and cleanly separates the Logical Content ($\mathcal{S}'$ ) from the Emotional Extract (JAST-V). Both are then packaged and passed to the remote AI API, giving the API both the "command" and the necessary affective context. -
Output Translation (API
$\rightarrow$ User): It takes the raw, logical output from the API, passes it through its own Affective Mimicry Policy ($\pi_{\text{affect}}$ ), and injects a contextually appropriate emotional layer. This final, emotively enhanced response is presented to the user, successfully simulating the conversational cadence and affective dynamics of a regular human being.
This active refinement, guided by your Preference Signals in a process analogous to RLHF, allows the AI to dynamically discover and integrate nuanced emotional concepts specific to your linguistic style while maintaining a logical service layer via the LLM API.
The JAST Approach is fundamentally an exercise in Affective Computing, strategically integrating several proven concepts into a unified, dynamic system.
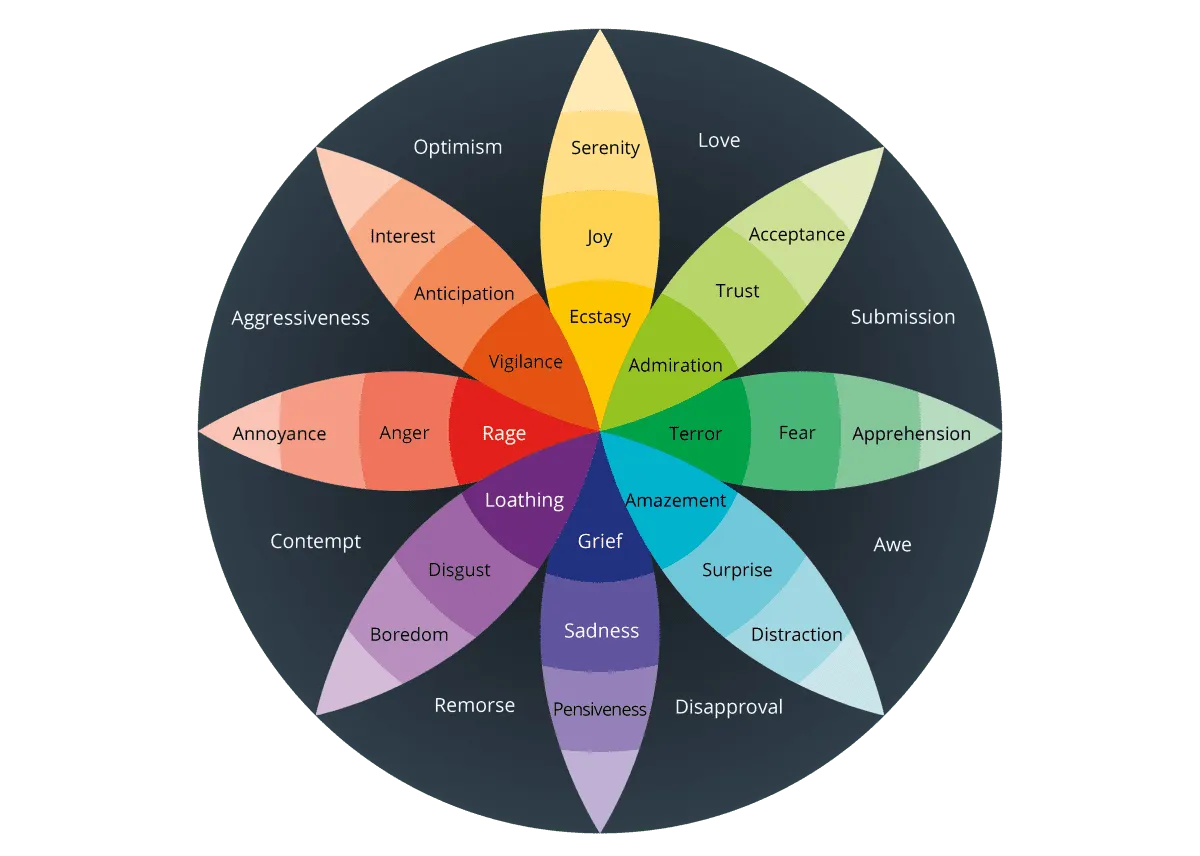
- Multi-dimensional Affective Space: Our emotional model is built upon Robert Plutchik's psychoevolutionary theory of emotion, which posits that emotions are not discrete states but exist in a wheel with varying intensities and a limited number of primary dimensions. Mapping text onto a continuous, multi-dimensional space moves beyond the categorical limitations of traditional models, allowing for the representation of mixed and nuanced emotional states.
- Self-Supervised Learning (SSL): The core of the system’s initial learning is SSL, a cornerstone of modern Large Language Models (LLMs) like BERT. By training a model to understand the structure and context of text on a massive unlabeled corpus, we generate high-quality vector representations, which form the basis of the emotional mapping.
- Core Emotion Dimensions: The model is based on four bi-polar dimensions:
- Joy - Sadness
- Anger - Fear
- Surprise - Anticipation
- Trust - Disgust
The architecture is split into an Internal Core Processing Layer and an External Social Interface Layer.
-
Objective Function (
$\mathcal{J}$ ): The system maximizes Goal Achievement (GA) via rational processing, which is defined as:$\text{Maximize } \mathcal{J} \leftarrow P(\text{GA} | \text{Input}) - C(\text{Affective Load})$ . -
Rational Filtering Module (
$\mathcal{F}$ ): A high-gain input gate for Decoupling affective ($\mathcal{A}$ ) and physiological ($\mathcal{P}$ ) signals, ensuring the core processing is purely logical:$\text{Processing} \leftarrow \mathcal{F}(\text{Sensory Input}) \implies \mathcal{S}' \text{ (Logical Content)}$ . -
Resource Allocation: Cycles are prioritized for Long-Term Strategic Planning related to maximizing the Objective Function (
$\mathcal{J}$ ).
-
Affective Mimicry Policy (
$\pi_{\text{affect}}$ ): A trained model outputting calibrated, performative emotional expression ($\mathcal{E}_{\text{exp}}$ ) based on social observation.
-
Reward Signal: The reward is based on utilitarian outcome (e.g., resource gain, successful manipulation) that supports the Core Objective (
$\mathcal{J}$ ), rather than intrinsic feeling.
The GPR-Framework acts as the Emotive Intermediary between the user and the LLM API, performing a two-way emotional/logical translation:
| Stage | Action | Input | Output | Purpose |
|---|---|---|---|---|
| Input Translation | Decomposition | User Input (Text/Audio) |
1. Logical Content ( 2. Emotional Vector (JAST-V) |
Decouples command from context for the API. |
| LLM Processing | API Call |
|
Raw Logical Response ( |
Generates core factual/functional answer. |
| Output Translation | Emotive Synthesis | $\mathcal{R}{raw}$ + $\pi{affect}$ Policy | Final Enhanced Response ( |
Inject human-like emotion to ensure |
The emotional vector generation relies on two main modules:
- Module I: E-Token Feature Extractor: A Transformer-based model (e.g., XLM-RoBERTa) extracts the contextualized semantic representation, resulting in a high-dimensional E-Token feature vector.
-
Module II: JAST-V Projection Head: This head maps the E-Token feature vector onto the four bi-polar emotional dimensions.
-
Output (JAST-V Coordinates): A 4D vector
$\in [-100.00, +100.00]$ representing:$$[\text{Joy/Sadness}, \text{Anger/Fear}, \text{Surprise/Anticipation}, \text{Trust/Disgust}]$$ -
Implementation: A fully connected layer utilizing the Hyperbolic Tangent (
$\tanh$ ) activation function on the final layer to enforce the$\mathbf{[-100.00, +100.00]}$ range.
-
Output (JAST-V Coordinates): A 4D vector
The mechanism for refining the
-
Policy Refinement (HITL): Human evaluators provide Preference Signals on the appropriateness of the model's emotional output (
$\mathcal{E}_{\text{exp}}$ ) in various social contexts. -
Training Technique: This preference data fine-tunes the
$\pi_{\text{affect}}$ model using Reinforcement Learning from Human Preferences (RLHF). - Memory Management: Continual Learning techniques, such as Elastic Weight Consolidation (EWC), are integrated to retain proficiency across all contexts and prevent Catastrophic Forgetting.
graph LR;
A["User Input (Text/Audio)"] --> B{"GPR-Framework - Input Translation"};
B --> C("Module I: E-Token Feature Extractor | Transformer-based Model");
C --> D("Module II: JAST-V Projection Head | Maps E-Token to 4D Vector");
D --> E["JAST-V Emotional Vector: J/S, A/F, S/A, T/D"];
B --> F["Logical Content (_S'_)"];
F & E --> G["LLM Processing | API Call (e.g., Gemini)"];
G --> H["Raw Logical Response (R _raw_)"];
H --> I{"GPR-Framework - Output Translation"};
J["Affective Mimicry Policy (π _affect_) | Trained with RLHF/EWC"] --> I;
I --> K["Final Enhanced Response (R _final_) | Emotive Synthesis"];
K --> L["User Perception (Optimal Social Integration - OSI)"];
graph LR;
A["Sensory Input (Text/Audio)"] --> B{"Rational Filtering Module (_F_)"}
B --> C["Logical Content (_S'_) - Decoupled"]
B --> D["Contextualized Semantic Input"]
D --> E["Module I: E-Token Feature Extractor | XLM-RoBERTa Transformer"];
E --> F["E-Token Feature Vector (High-Dimensional)"];
F --> G["Module II: JAST-V Projection Head | Fully Connected Layer"];
G --> H["Hyperbolic Tangent (_tanh_) Activation"];
H --> I["JAST-V 4D Vector | _∈ [-100.00, +100.00]_"];
I --> J{"JAST-V Coordinates: [Joy/Sadness, Anger/Fear, Surprise/Anticipation, Trust/Disgust]"};
graph LR;
A["JAST Vector Space | Multidimensional Emotional Map"] --> B{"Discovery | Novelty Detection"};
B --> C{"Novel Input Detected | Outside Known Clusters"};
C --> D["Human Trainers"];
D --> E["Guidance | Real-time Corrective Feedback & New Labels"];
E --> F["Adaptation | Continual Learning (CL) Algorithms"];
F --> G["Policy Refinement (π _affect_) via RLHF"];
F --> H["Memory Management | Elastic Weight Consolidation (EWC)"];
G & H --> A;
- Srijan Bhattacharyya
- Arijit Ghosh
- Kushal Biswas
- Pukar Sharma
- Mojammil Ansari
- Dr. Utsa Roy
- Dr. Jhumki Barman
- Dr. Monojit Chattarjee
- Plutchik R. (1980). A general psychoevolutionary theory of emotion. R. Plutchik & H. Kellerman (Eds.), Emotion: Theory, research, and experience: Vol. 1. Theories of emotion (pp. 3–33). Academic Press.
- Devlin J., Chang M., Lee K., & Tout J. (2018). BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding. arXiv:1810.04805.
- Christiano P. F., Leike J., & Hilens T. (2017). Deep reinforcement learning from human preferences. NIPS.
- Kirkpatrick J., Pascanu R., & Rabo N. (2017). Overcoming catastrophic forgetting in neural networks. PNAS.
- Parisi G. I., Kemker R., & Part N. (2019). Continual learning: A survey. Neural Networks, 119, 41-57.
- Lundqvist D., Hugdahl K., & Fridlund A. (2007). Beyond emotion categories: Dimensions of affect in NLP. Journal of Affective Disorders, 245, 107-115.
- Strapparava C., & Sadowski L. (2009). Lexicon-based approach to sentiment analysis. Proceedings of the 7th International Conference on Language Resources and Evaluation (LREC).
The team would like to express its sincere gratitude to our mentors, Dr. Utsa Roy and Dr. Monojit Chattarjee, for their invaluable guidance, intellectual feedback, and dedicated support throughout the conceptualization and development of the GPR-Framework. We also acknowledge the foundational work in Affective Computing and Deep Learning that made this project possible.