아나콘다(https://www.anaconda.com/products/individual )’를 설치하여 파이썬과 라이브러리를 한번에 사용 할 수 있는 가상환경을 만들고 주피터 노트북(https://jupyter.org/ )으로 실행
Pandas 라이브러리를 통해 필요한 데이터만을 담은 data frame을 선언하고 이를 통해 머신러닝에 적용시킬 수 있음. 인덱스가 있어 행과 열로 구성된 프레임에 데이터가 저장되는 테이블 형태의 data frame을 이용할 예정
BeautifulSoup은 html 코드를 파이썬이 인식 할 수 있는 객체 구조로 변환하는 Parsing을 담당
selenium은 브라우저 자동화도구로서 웹브라우저를 통해 동적페이지에서도 데이터 수집 가능
1-(1) Anaconda Prompt
1-(2) 크롬드라이버 저장 경로 ,자신의 네이버 ID/PW입력

1-(3) 데이터를 저장하려는 엑셀파일의 절대 경로를 입력

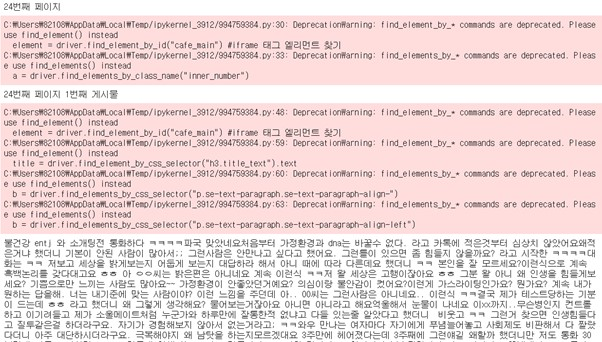
1-(4) 크롤링 되는 과정
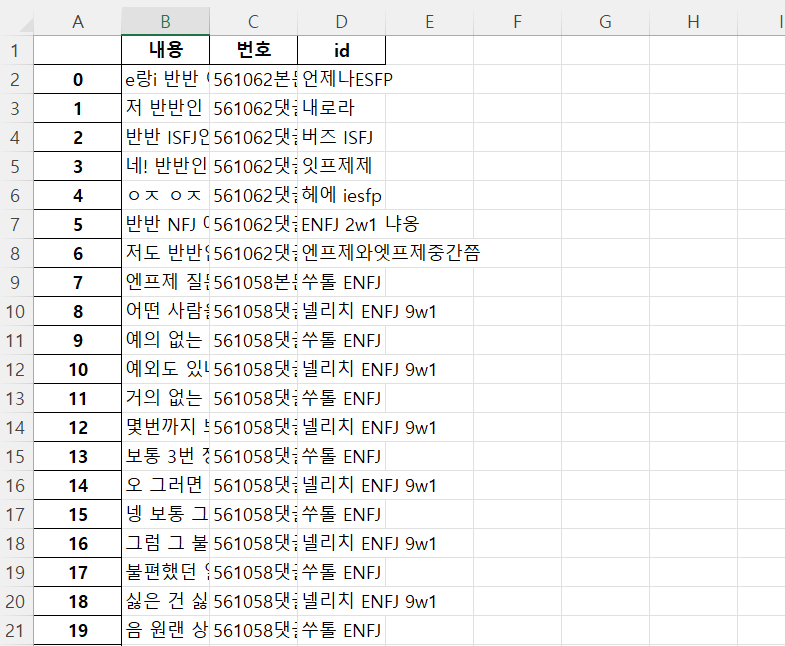
1-(5) 크롤링 완료 후 엑셀파일에 저장된 데이터 모습
<크롤링한 데이터를 전처리하는 과정>
google colab에서 preprocessing.ipynb 파일을 열어 차례대로 실행한다.
2-(1) 정제되지 않은 텍스트에 Py-Hanspell 적용
-Py-Hanspell은 네이버 맞춤법 검사기를 바탕으로 만들어진 한국어 전처리 패키지다.
-맞춤법 검사기를 import 하고 check를 하게 되면, 맞춤법과 띄어쓰기가 정확히 맞춰진다.
2-(2) 문장 토큰화 도구 KSS 적용
-KSS는 한국어로 되어있는 텍스트를 문장 단위로 토큰화를 해주는 도구이다.
-위에서 맞춤법이 정확하게 맞춰진 텍스트에 KSS를 적용하면 문장 단위로 나누어지게 된다.
2-(3) 형태소 분석 도구 KoNLPy 적용
-KoNLPy는 형태소 단위로 토큰화를 하는 도구이다.
-KoNLPy를 통해서 사용할 수 있는 형태소 분석기에는 Okt(Open Korea Text), 메캅(Mecab), 코모란(Komoran), 한나눔(Hannanum), 꼬꼬마(Kkma)가 있다.
-그중 Open Korea Text 를 사용하여 형태소 추출을 적용하게 되면 다음과 같이 토큰화 된다.
<LSTM으로 mbti 분류하기>
3-(1) 3-LSTM 폴더의 mbti_LSTM.ipynb(코드 파일)과 mbti_data.xlsx(데이터 파일)를 다운받고, 두 파일 모두 구글 드라이브에 저장해준다.
3-(2) 3-(1)에서 구글 드라이브에 저장한 mbti_LSTM.ipynb(코드 파일)를 열면 코랩으로 코드 파일이 열린다.
3-(3) 주석으로 "#데이터가 담긴 엑셀 파일의 구글 드라이브 경로" 라고 적힌 라인에는 data라는 변수에 mbti_data.xlsx 파일의 구글 드라이브 경로를 적어준다.
3-(4) 그리고 '런타임'>'모두 실행' 하고, 구글에 로그인하게끔 하는 팝업창이 뜨는데, 그 팝업창을 통해 로그인을 한다. (그리고 만약 팝업창에서 암호코드가 나오면 복사해서 콘솔창에 뜨는 필드에 붙여넣기 한다.)
3-(5) 그러면 데이터 로드는 끝나고 전처리 후 4가지 지표의 이진 분류에 대한 학습이 진행된다.
3-(6) 학습이 끝난 후 MBTI를 예측하는 함수가 정의되고 text 변수에 사람의 성격이 잘 드러나는 텍스트를 넣고 함수에 text 변수를 input으로 넣은 다음 실행해준다.
3-(7) 그러면 그 텍스트에서 드러나는 MBTI를 예측하는 것을 볼 수 있다.